13:47> How to debug a crashing bug in Red with all the gory details: https://github.com/red/red/issues/3692#issuecomment-450722963
Added to the wiki: https://github.com/red/red/wiki/%5BDOC%5D-Debugging
hiiamboris
14:58Great! One thing however that I still don't get. Why do we have to reserve an extra character?
dockimbel
15:47@hiiamboris You mean in the UTF-8 loading code?
hiiamboris
15:59@dockimbel I mean this: https://github.com/red/red/blob/master/runtime/unicode.reds#L214 and https://github.com/red/red/blob/master/runtime/unicode.reds#L182 and https://github.com/red/red/blob/master/runtime/unicode.reds#L245
16:00What's that "edge case" that is being mentioned, that requires an extra character on top of the string length?
16:04Does it write a zero terminator at series/tail for 16- and 32-bit strings?
dockimbel
05:16@hiiamboris The edge case is when s/tail points to the end of the available space in series buffer. We need to account for one extra character, as cp is written at the tail after the upgrade, we need to be certain that the newly allocated space accounts for it:
true [
s/tail: as cell! buf1
unit: UCS-4
s: Latin1-to-UCS4 s ;-- upgrade to UCS-4
buf4: as int-ptr! s/tail
end: (as byte-ptr! s/offset) + s/size
buf4/value: cp
buf4: buf4 + 1
]
buf4/value: cp is writting at the tail.
05:20Series buffer allocation are rounded to next multiple of 16 bytes. So there are often extra available space after an encoding upgrade for more characters before requiring an expansion. The edge case is when the allocated space is get fully filled after the upgrade (s/tail pointing at the end of the allocated space). Failing to account for the next cp character to write after the upgrade will result in a memory corruption.
08:40@hiiamboris Impressive work on View backend in recent commits, many thanks for the hard work to improve it! :thumbsup:
meijeru
13:50@dockimble Very instructive! A good peek at what goes on behond the scenes...
hiiamboris
14:16Ah so these this-to-that upgrade functions were written specifically for the from-utf8, which requires them reserve an extra char. Makes sense...
@dockimbel ☻ Sure! And I'm glad you are aware of every PR out there!
dockimbel
16:03@hiiamboris > Ah so these this-to-that upgrade functions were written specifically for the from-utf8, which requires them reserve an extra char. Makes sense...
Right, they need to ensure that an extra character can be safely added at the tail.
16:04@meijeru Thanks. I'm still unsure how informative such debugging session log can really be.
Dobeash
21:29Is "Latin-1 strings can now be decoded" true?
21:55@Dobeash FYI R2 does not decode latin-1, in fact it does not decode anything, just makes bytes out of hex, and since world does not actually end on Europe border, the result in another locale will be not what you expect: for example it shows Ashley Trьter for me.
greggirwin
22:40@Dobeash, to only loads as UTF-8 currently. @qtxie, what is the way to access unicode/load-latin1 functionality?
qtxie
00:53@greggirwin It's not exposed in Red level yet.
dockimbel
03:26@Dobeash See this [SO entry](https://stackoverflow.com/questions/43379932/access-error-invalid-utf-8-encoding-ffd8ffe0/43383454#43383454). Using such simple converter, you get:
03:26We should add Latin1 as a codec in Red (PR welcome).
rgchris
04:06@Dobeash See also: [clean.red](https://github.com/rgchris/Scripts/tree/master/red/clean.red)
04:11*(takes a binary, ignores valid UTF-8 and converts any other high code points according to CP-1252)*
dockimbel
08:59FYI, I have modified VID to merge properly actors from template styles with the user-provided ones. So now the following construct is possible:
view [
style but: base
on-down [face/color: face/color / 2 do-actor face event 'click]
on-up [face/color: face/color * 2]
but "Say hi!" red on-click [print "hi"]
]
08:59Let me know if that change causes any trouble in VID actors handling in your own scripts.
11:19Just had a quick look at some Github stats about Red. Can you guess how many repos using Red language exist on Github? See the result here: https://github.com/search?q=red+language%3ARed&type=Repositories
11:27It seems difficult to get some stats for Rebol as its file extension conflicts with R language, so Github gives wrong attribution, like there: https://github.com/pocoso/Intelligent-Systems
11:30Stats per languages are not very reliable on Github it seems.
11:37@BeardPower Try removing the "red" word in the query.
BeardPower
11:43@dockimbel Same. Maybe I blocked public search.
toomasv
15:42@BeardPower https://github.com/search?l=&q=user%3ABeardPower You seem not to have public red repositories :question::exclamation:
ne1uno
16:32@toomasv they don't like some browsers, but even their advanced search is bad. [1. user BeardPower (https://github.com/search?q=user%3ABeardPower) [2. BeardPower wiki](https://github.com/search?q=user%3ABeardPower&type=Wikis)
toomasv
16:33@ne1uno Do you see some public Red repositories there?
16:51Thanks guys. I'm taking the wrath of @9214 ;-)
endo64
21:11What do you think about changing new-lines default behavior to new-line/all and add /only refinement for the current behavior? I almost always use /all.
AlexanderBaggett
23:16? action! lists the various things that are actions , but I am not sure how to list it in a way that would allow for me to write it to a file. How would you do that?
23:17I mean I would write the result with write %actions.txt but not sure what I would put in for the data argument
amreus
23:20@AlexanderBaggett I don't know the direct answer but you could parse the output of what
AlexanderBaggett
23:21@amreus , I appreciate it, I will see what I can do with it.
23:23hmm that doesn't quite work. I can't bind it to a value. >> x: what action! gives me Script Error: x: needs a value
04:14> ? action! lists the various things that are actions , but I am not sure how to list it in a way that would allow for me to write it to a file. How would you do that?
@AlexanderBaggett, help / help-string are designed for human output, and aren't intended to be loadable. Depending on what you want to learn, you could either parse the output, as @amreus suggests, or look at the source for show-datatype-help (in help-ctx), see how it works, and hack it to do what you want.
04:21> What do you think about changing new-lines default behavior to new-line/all and add /only refinement for the current behavior? I almost always use /all.
@endo64, good design question. I use /all as the default interactive mode too, but not for code generation formatting. Red clearly wanted to be Rebol compatible. I have an old func, from R2 days to save time for my most common use:
It's not a terribly intuitive func interface for me, so I probably have a half dozen ad hoc wrappers for it like that. That said, I don't know if changing to an /onlymodel is better.
gltewalt
04:28If help didn't return unset, you could write it to file easily
endo64
10:49@greggirwin I also have a similar function: nl: func [block [block!] /step num [integer!]] [either step [new-line/all/skip block true num] [new-line/all block true]]
10:53But I just found a difference between Red and R2/R3, which we should raise a ticket and fix: new-line flags are not cleared on subsequent calls:
>> b: [1 2 3 4]
== [1 2 3 4]
>> new-line/all b on
== [
1
2
3
4
]
>> new-line/all/skip b on 3
== [
1
2
3
4
]
>> new-line/all/skip b on 2
== [
1
2
3
4
]
13:19I have been inspired by @dockimbel 's check-brackets function (can't remember in which room he published it) to write one which fully takes into account the lexical structure of Red. His one, only Proof of Concept, could not cope with brackets inside strings and end-of line comments. Mine does. To remind you: this is about finding unmatched [ ] and ( ) by line number in the source -- something that the compiler/interpreter cannot give you. Especially with large programs this can be helpful in more quickly finding the culprit. The program is [here](https://gist.github.com/meijeru/53eeb6131c3ff7a9cb4873d9f8a39371) and has been tested on all the .red sources of the toolchain.
13:36Interestingly, I was not able to devise a set of parse rules to do the necessary checks, opting rather for a simple traversal of the text, char-by-char with a single lookahead in the case of # and <. The program became big because of the detailed rules of what can go where...
13:40It is not that spectacular, just following all the rules (and there are some...).
mikeparr
14:28@meijeru you probably know that there is also a pretty-printer by Gregg Irwin (can't find the link -sorry) derived from Carl's at http://www.rebol.net/cookbook/recipes/0042.html This identifies [ ] of course - not sure if all the cases are covered.
meijeru
14:31In my program, I intended all the cases to be covered - I welcome comments about ones that are not.
toomasv
16:16@meijeru Got inspired by you and tried to cook a [shorter one](https://gist.github.com/toomasv/c78254ecdd970b623417e5b2146a0e0a). But I am not sure it covers all cases. Er.. in fact, that it works at all in most cases. :blush:
hiiamboris
17:31You can't possibly accurately detect a missing or misplaced closing ] bracket like this. Why not consider the *indentation* as a hint on the limits where it should be found?
17:38And, by the way, I'd love to have a special lexer mode that will, apart from the block returned data, provide a block with tokens and their locations in the source (file, line number, column) and in that data (as blocks of paths of indices). Current lexer just discards the info containing all the ties between the input and the output, the very info that may serve as a source for a variety of code analysis tools, editors, etc.
toomasv
17:59@hiiamboris Indentation can be used as hint in cases where code is indented according to suggestions, but it is in no way necessary for execution to be indented in this way. As red is free-form, indentation is not reliable indication of structure. But admittedly, in many cases it can be used as hint.
giesse
19:42@meijeru if your script can do it, why can't the interpreter?
19:48@hiiamboris the only real problem (well, aside from memory usage) is that blocks can be manipulated, so even if you preserve line numbers you may end up with results that are more confusing than they are useful.
IMHO, parse on strings and load should give line numbers on errors; do cannot really, but, the interpreter should have a built in "debugger" so that you can go and look at what was going on when the error happened and, in most cases, figure out exactly where it came from.
hiiamboris
20:04Well, right, line-preserving load is already a huge leap forward in error reporting. And with it you could just do/next thru your code and when that fails you could find where the failure originated from using the supplied line data. Apart from dynamically generated code, which isn't plentiful, I figure this will work, maybe even as a basis for a debugger.
But I was thinking on even smaller applications. Like maybe you want to do code highlighting? Do you really have to cut the parse patterns out of the lexer to make it happen? That's what everybody does it seems, but I don't see no elegance in this.
meijeru
20:45@giesse The interpreter (i.e. the lexer part of it) could do it, but it would require a totally different approach than the current parse-based one, I believe. In any case, there are design decisions involved that I do not get involved in. My straightforward analysis does nothing else than check the structure, it is not at all adapted to real "lexing".
giesse
22:34@hiiamboris I think there's very little value in an external debugger. It needs to be part of the interpreter.
Also, there's no reason why an editor couldn't use load/next already for syntax highlighting. And of course, it would be nice to have something like Romano's Anamonitor as well.
hiiamboris
23:30@giesse load/next loads the whole block (context, function body, whatever). How would you apply that to individual lines?
04:20@hiiamboris Having load returning some line info in addition to the loaded values (using a specific new refinement) is something I have been considering since a few months.
04:22@giesse Do you have a debugger in mind for Rebol-like languages already? How would it work?
05:45@dockimbel Well, what I'd want is something very different from what people consider to be a debugger. I just want the interpreter to write to a file a complete execution trace, then have a UI that lets me step backwards and forwards in the code, and so on. So, if there's an error, I want to be able to step *backwards* from the error, not the other way around.
dockimbel
07:51@giesse That should not be difficult to support, but that would give you a limited access to the global state, you would only see the data modified at each step.
meijeru
09:47@gltewalt Your remark about breaking lexical rules with make is both generally true, and not relevant for the bracket matching algorithm, since that one is essentially re-doing part of the lexical analysis. The lexers in the toolchain serve the purpose of constructing values that are valid for programming in Red (using the "do dialect" so to speak). With make one can construct other values that may have their use in other dialects.
09:51@gltewalt On your other question: the algorithm I used is based on the same principle as the one you refer to. It is of course much more extensive, since we have to cope with 9 (nine) different pairs of brackets, each with their own rules of what can be between them, plus end-of-line comments and newlines. But the basic structure is very simple: read a character, switch into alternatives, push or pop the stack, advance the pointer.
dockimbel
10:06@hiiamboris I'm not sure if you're aware or not of the two failing tests (on W10) you added to the tests suite:
===group=== to-image check
--test-- tic-1 size adequacy FAILED**************
--test-- tic-3 capture of color blending FAILED**************
rcqls
10:14Just to let you know that this repo [docker-red-gtk](https://github.com/rcqls/docker-red-gtk) provides notes to use of red/GTK branch in a docker container after building the docker image. This is for macOS and Linux users mainly (not hard to adapt for Windows users). Hope that this allows,red community to help developping red/GTK branch more easily. Maybe, a red/gtk room could be interesting to discuss red/GTK branch development.
dockimbel
10:42New blog entry: https://www.red-lang.org/2019/01/full-steam-ahead.html
10:44@rcqls Thanks. A GTK room is welcome. Here it is: https://gitter.im/red/GTK
17:54If not may be you know how to improve perfomance of draw calls?
amreus
18:28Is the blog entry saying that linking to a 64-bit .dll will be a Pro feature?
pekr
18:30I don't think so, but don't take it for granted. There seems to be some plan to offer another compiler target, which in itself supports production of 64bit binaries. In next sentence the blog article states, that full 64 bit support for Red toolchain intself, might come the next year ....
9214
20:32@amreus no, article says that /Pro version will offer a compiler backend as an advanced alternative to the current one. With it you can target platforms that team doesn't have time and resources to properly support in community version - that includes 64-bit platforms - and also do some fine-tuning with optimization layers.
Linking to 64-bit libraries will be possible in either version, except that /Pro comes first, and community version will require a dedicated work to extend compiler backend in the next year or so.
greggirwin
20:33@schwarzbox draw is an interpreted dialect, but you can look at the redcv work @ldci has done, as well as the mandelbrot(+fast) examples in the red/code repo under https://github.com/red/code/tree/master/Scripts. If yo provide examples of what is slow, the great Red optimizer (people here) may produce some help.
giesse
21:15@dockimbel yeah, modification at each step since the start of the program, assuming the initial state of the interpreter is always the same you do get the global state. Or dump that at the start if you think that's necessary. In most cases though, local state is all you need to figure out where the problem is; after all, all we do now is probe a few things here and there.
tmpbci
21:22On macOS apparently the new IO tests udp/tcp examples advertised in the blog doesn't work with 0.6.4 automated build because of open. But it work if I build console with qtixie red 0.6.3
amreus
21:23@9214 Thanks for the clarification. I understand the need for profitability and why that is prioritized.
9214
21:34@tmpbci this UDP/TCP implementation exists solely for testing purposes, and is not intended to be the final API.
tmpbci
21:34I see just to report. I'm really pleased to have these :)
PeterWAWood
23:38When the port! datatype is implemented, how difficult would it be to emulate Apple's [urlSession API](https://developer.apple.com/documentation/foundation/urlsession)?
greggirwin
01:20@PeterWAWood I think this may be the telling point:
> The URLSession API involves many different classes working together in a fairly complex way that may not be obvious if you read the reference documentation by itself.
PeterWAWood
01:54Sounds like a 'no' then. I guess the alternative would be wrap the Apple API and the Android equivalent. I'm guessing that the Windows System API doesn't provide such features though .NET could well do.
qtxie
02:12> The URLSession class and related classes provide an API for downloading data from and uploading data to endpoints indicated by URLs. The URLSession class natively supports the data, file, ftp, http, and https URL schemes.
@PeterWAWood I think the file port, ftp port, http port, etc, will cover the features of it. So the question is, how difficult would it be to implement those ports?
dockimbel
02:24@PeterWAWood Ports should be covering a lot of those features, except the ones that rely on the OS: > The API also enables your app to perform background downloads when your app isn’t running or, in iOS, while your app is suspended.
PeterWAWood
03:10@dockimbel Thanks. Those OS related features would seem somewhat tricky to reproduce.
It's encouraging to think that the bulk of such features could be made available cross platforms. It would surely enhance Red's attractiveness to desktop and mobile developers.
03:56I just wanted to thank everyone who has contributed lately. So many bugs found and fixed, old tickets addressed, docs improved...it's great. Sometimes I'll try to add a note of thanks, but can't always keep up with everything, so please understand that when you hear the "click" of your contribution being accepted, it's an acknowledgement, itself, for what you've done.
THANK YOU ALL!
rebolek
09:10Get it to the frontpage! https://news.ycombinator.com/item?id=18843544
18:53about debugger try the next code ( only on cli because red console has the output buffered). I think it would work better if do would allow it. Note, for example, that last assignments aren't evaluated.
ed []
codeg: [
n: 1
f: func [a b][a + b]
a: f 2 4
n: n + 1 loop 3 [
n: n + a
]
n: a + 3
n: 12
]
native-loop: :loop
loop: func [num codel][native-loop num [eval_code codel]]
eval_code: func [code] [
while [not empty? code][
;print ["=>" mold code]
nl: new-line? code
if nl [new-line code off]
insert code '>>>>
if nl [new-line code on]
probe head codeg
remove code
if nl [new-line code on]
;if block? code [eval_code]
set [value ] do/next code 'code
wait 1
print ["==" mold any [attempt [:value] 'unset]]
]
]
eval_code codeg
loop: :native-loop
halt
metaperl
18:36Just FYI, this rejoin example with b2 shows the wrong evaluated output of [3 + 4 "result"] ... it should be [3 + 4 " is result"]
18:36Is the online sandboxed red available yet? I cannot run the executable at work - they lock down unrecognized executables.
mikeparr
20:14@metaperl Re RBE error - thanks, will fix later.
metaperl
21:15 sudo apt-get install ia32-libs libc6-i386 libcurl3 on Debian yields "Package ia32-libs is not available, but is referred to by another package. However the following packages replace it: lib32z1 lib32ncurses5"
No, that's planned for this year, but there are some other things to do first.
hiiamboris
22:44It would also be great to have these sandboxes for different platforms, instead of having to run a whole lot of VMs to test stuff.
dockimbel
04:18> sudo apt-get install ia32-libs libc6-i386 libcurl3 on Debian yields "Package ia32-libs is not available, but is referred to by another package. However the following packages replace it: lib32z1 lib32ncurses5"
The first process (ia32-libs) should be probably removed from Downloads page, as @giesse correctly wrote, it's ancient stuff and I'm not sure if there's any distro that's still using it.
18:38i dont know if this is old hat to y'all but it might be a good pitch for red as a whole
18:39also it's crazy that it's running do on each keydown with no noticeable lag
9214
18:52@garthgoldwater [an old hat](https://twitter.com/red_lang/status/857126572272254977) indeed, but it's great to see that you have fun with Red. Welcome!
garthgoldwater
18:52i feel like that should be on the front page of the website or something
pekr
19:49As for above code - where does the outputcome from? Isn't that a typo?
x8x
20:41@dockimbel For Arch installed thru Manjaro or Manjaro Architect this is what's needed:
pacman -S lib32-curl
(tested with version 18.02 on a 4.20 kernel) (@rebolek not sure since which release but it's not crashing anymore when doing a read url!)
For Ubuntu thru 17.10: libcurl3 For ubuntu from 18.04: libcurl4
Also this:
apt-get install libc6:i386 libcurl3:i386
can be reduced to:
apt-get install libcurl3:i386
as libc6 is a dependency like there are many others, is it ok to update with the short version or is there any reasons to specify it?
And in the commands, we sometimes have sudo and sometimes not, probably more copy/paste friendlier to include sudo if it's needed.
Agree with @giesse and @rebolek, it's dinosaurs' era stuff, not used at least since Ubuntu version 11.10 which was released in October 2011, I would remove that and readd it if some specific system/OS needs it.
Dobeash
21:42> Trim now supports binary! values. By default, only null values are removed.
>> trim/with #{00} null
== #{}
works.
>> trim #{00}
hangs console.
9214
21:42@Dobeash confirmed. Would you like to open a ticket for it?
21:43FYI, we have [/bugs](https://gitter.im/red/bugs) room where you can post bugs for confirmation.
21:44@Dobeash start [here](https://github.com/red/red/issues/new?template=bug_report.md) and fill in all the info.
Dobeash
21:44Perfect, should I move this entire discussion there?
9214
21:44Sure, if there's something else to discuss. There's no need to delete messages and cross-post them in another room though, that was just a remark for future.
05:49@rebolek BTW, about structured editors, I promised to send you some links that I gathered during my own research on that topic about two years ago: https://www.greenfoot.org/frames/ http://nickgravgaard.com/elastic-tabstops/ http://leoeditor.com/ https://www.microsoft.com/en-us/research/project/live-programming/ http://www.pyxisystems.com/file/BoxerStructures.pdf https://shaunlebron.github.io/parinfer/#paren-how-it-works
05:51Greenfoot is the most advanced I have found, though after playing some time with it (despite the terrible slowness), it seems it just cannot scale up well visually with deeply nested code.
rebolek
06:14@dockimbel Wow, lot of stuff to explore! Thank you!
huangyg11
09:35how can i make a post request and parse returned json?
rebolek
10:21@huangyg11 see send-request function from https://github.com/rebolek/red-tools/blob/master/http-tools.red It can send POST requests and does automatically parse returned JSON data
10:26POST request is done with write/info server [POST some-data].
meijeru
12:31I repeat my signal: the feed in the right column of this page, wich is a useful tool for me to keep up-to-date, seems to be stalled. Most recent item I see is "toomasv commented #3714" on Jan 07. It is now Jan 10, and I am sure that much has happened that needed to be in the feed. Will someone look into this and take it up with Github?
gilbert
16:53are there any examples of compilers written in red?
9214
17:50@gilbert VID and RTD dialects, the former compiles declarative description of GUI layout to a virtual tree of components, the latter takes a stylized text and compiles it down to a single string with a low-level styling description. C3 (currently in development) compiles a domain-specific language for smart-contract development down to EVM bytecode. One of community members implemented [Brainfuck to 8085 assembly compiler](https://github.com/nickkoro02/bf-to-8085). There's also [this](https://github.com/eranws/red-false).
If you mean compilers for general-purpose languages rather than DSLs and esolangs - Red and Red/System compilers are written in Rebol, which is 95% compatible with Red.
greggirwin
19:15@x8x, do you know what the issue might be, that @meijeru reported above?
mikeparr
19:24@9214 Congrats on you well-written, balanced article on Red vs Racket on Reddit.
greggirwin
19:27I'm anxious to get to it today @9214. Thanks for doing that.
mikeparr
20:02Red vs Racket is at: https://www.reddit.com/r/Racket/comments/aec1ae/contrast_with_racket_with_red/
9214
20:04@mikeparr that's a cross-post in Racket subreddit, the "article" you've mentioned is [here](https://www.reddit.com/r/redlang/comments/aebxct/contrast_red_with_racket/).
17:56@9214, absolutely fantastic reddit Racket write-up. Don't lose that. We should find a good place to post it, or start our "Red for Blub" developers series and use it there.
9214
18:09@greggirwin such series would require writers who know both Red *and* Blub thoroughly, to make a fair review. "X vs. Y" topics are extremely important to handle blandly and with due respect to both sides. And posting them on behalf of Red might imply a biased "X vs. y" rather than "X vs. Y" to someone.
19:50If only Red relaxed lexing rules a bit and allowed , as part of a token, then BF would be fully loadable :wink:
greggirwin
19:52@9214, yes, people need to at least be familiar with the other lang. And they can grow over time. The main thing is to be a primer, so they can find their feet with Red.
huangyg11
06:42twice: function [a [integer!] /one return: [integer!]][ c: 2 a: a * c either one [a + 1][a] ]
06:42in this function definition, what is the "/one" represents?
07:13@huangyg11 http://www.rebol.com/r3/docs/guide/code-functions.html#section-6 We have a dedicated room https://gitter.im/red/help for learning Red and help you debug simple code
dockimbel
05:29@x8x Do you want me to recreate the webhook link for the right activity panel here?
16:35@meijeru I got a look at Github settings about the missing events in the right panel here, and there a warning message now on Github about such integration: > Note: GitHub Services are being deprecated. Please contact your integrator for more information on how to migrate or replace a service with webhooks or GitHub Apps.
16:35So, if Gitter can provide us a webhook, we can integrate it again with Github events.
16:44@meijeru @x8x I have recreated the Github integration using a webhook/token found in the Settings here. Seems to work again now. Moreover, we also have tighter control over which kind of Github event should be sent.
meijeru
17:41Great! Happy to see the service continued, because for me -- and I suppose for others -- it is a useful tool. :+1:
17:46There is a gap though, apparently it was not possible to catch up with all events...
greggirwin
21:33@meijeru, yes, no message queue with guarantees behind it.
hiiamboris
03:24> we also have tighter control over which kind of Github event should be sent.
REP repo can be added there for one. I've seen some actions on PRs missing too (review comments maybe?)
dockimbel
04:30@x8x ^--- Do you have all the admin rights to add that webhook for REP repo on the activity panel here?
hiiamboris
07:02@gltewalt [This note by @dockimbel](https://github.com/red/red/issues/3720#issuecomment-453913177) on stricter block/hash indexing looks like worth documenting somewhere
GiuseppeChillemi
21:10I have a block. If the last value of the path referring to it is not coherent I get a NONE result but if the middle path of the path is not existant I get an error. I think it is not coherent but not knowing the deep design decision behind this behaviour I leave to you any consideration:
21:11Also I don't understand what the error message is communicating.
nedzadarek
21:14@GiuseppeChillemi > Also I don't understand what the error message is communicating.
One of the elements of the path is none (it can be b or ce) so you cannot select on it. I guess more descriptive error message would be nice (e.g. what element is none).
GiuseppeChillemi
21:16@nedzadarek I have undestood this but I expect NONE too in the last scenario.
21:18A selector not heading to any result is the problem so it should give an unique result regardless of the position of the "missing hit". But there could be higher reasons.
nedzadarek
21:24@GiuseppeChillemi As for the first question: > if the middle path of the path is not existent I get an error.
In my opinion it's good design choice. Say you have typed a/b/c/dd instead of a/b/c/d(you just mistyped a last word d). You get none but you expect some value. You checked the source and fixed your typo. On the other hand you have a/bb/cc/dd. Does it mean you mistyped bb, cc or dd? In this case I would rather get an error than some "silent none". ps. of course there could be other reasons or my post could be wrong.
endo64
21:36@GiuseppeChillemi Note that select is relaxed on none values, so you can get none by using it:
>> select select select a 'b 'ce 'ded
== none
21:38And of course you can always do attempt [a/b/ce/ded] ; == none.
nedzadarek
21:46ps. :point_up: [January 14, 2019 10:14 PM](https://gitter.im/red/red?at=5c3cfbb51cb70a372adba716) in here I mean "select" not select
greggirwin
22:34@GiuseppeChillemi this behavior is by design.
22:35In addition to @endo64's note, you can easily use attempt around your path evaluation, if you want to ignore the error.
gltewalt
00:39@hiiamboris I book marked it. Will cover it when I get to hash!
hiiamboris
03:29Hey guys. I think the activity feed is now doubling every event...
05:46@GiuseppeChillemi > @nedzadarek I have undestood this but I expect NONE too in the last scenario.
And none is what you get from a/b/ce:
>> a/b/ce
== none
But you are asking then an extra /ded from that none value, so the error is justified. As pointed out above select offers a relaxed behavior in cases where you need it to be a none pass-thru (mostly for conditional expressions).
GiuseppeChillemi
08:07@dockimbel Doc, the documentation states that "an invalid block selector returns none". So you expect to apply this rule to all "invalid block selectors". I have learnt this rule [here](https://github.com/red/red/wiki/%5BDOC%5D-Differences-between-Red-and-Rebol#invalid-block-selector-returns-none). It would be good either to change the documentation and to change the error message too because you do not understand what is happening when you read " ** Script Error: path a/b/ce/ded is not valid for none! type" . "** Script Error: path a/b/ce/ded is not valid as one of its component returned none! type" could explain more accurately the error event
19:25@GiuseppeChillemi, I'll take a look at the wiki. Thanks for pointing that out.
> " Script Error: path a/b/ce/ded is not valid as one of its component returned none! type"
There may be a way to improve the error message, but it may also just be a lateral move. That is, a change, but not better or worse, just different. e.g., it could, *perhaps* list the path at the point where the none! value occurred, but that would be worse, if you have different roots that all use the same set of nested keys. You want to see the full path in that case. The current wording, once you understand it, is quite general. That's also by design in Red, to keep the size down. As with doc strings, it means we sometimes have to give up details. Sometimes it just makes us think a bit more about how to explain things. Could we trim the tail part of the path on output instead? Same issue in reverse. Each may be better in some cases, but not all. Most? Can't say.
In this case, the error occurs because, during the path evaluation, a value is found that does not *support* path evaluation (the eval-path action doesn't exist for it). More like "path a/b/c/d/e is not valid because a/b/c returned <type>".
bad-path-type: ["path" :arg1 "is not valid for" :arg2 "type"]
Since that only appears to be used in %actions.reds (line 53 in get-action-ptr-path), and the fire func, from %datatypes/common.reds, can take one more arg, it might be possible to include both the full path and point of error without too much work.
Thoughts anyone?
x8x
20:48@dockimbel you added a webhook and the service issue has just been fixed so both were now sending events updates, have disabled the service, no more doubled events.
dander
01:06> "path a/b/c/d/e is not valid because a/b/c returned <type>"
having been confused by the error in the past, I really like this message.
JacobGood1
02:36Do not forget about pharo as a structured editor: https://pharo.org/
04:15@GiuseppeChillemi > Doc, the documentation states that "an invalid block selector returns none". So you expect to apply this rule to all "invalid block selectors". I have learnt this rule here.
That wiki page you've pointed out is just a random list of differences in behaviors that users have collected between Red and Rebol. I wouldn't call that a "documentation", but more like a reference for a future documentation. Moreover, your quote is actually the title of an entry, not a "rule". That entry describes a different case than yours (words selection in blocks in your case vs index selection inconsistency in that entry). BTW, that entry should be worth a ticket, as I think this inconsistency is worth examining again. It seems like a side-effect from another departure from Rebol in ordinal selectors.
04:19Path error messages are often poor in Red (not that they are very explicit in Rebol either). This is mostly due to the way paths are compiled, breaking the path into pieces so that the original path does not exist anymore, hence can't be reported in an error. In the above case, we can have a look at it if someone opens a ticket, though no guarantee that it can be improved in the current state of the compiler.
greggirwin
20:35@dockimbel, so my suggestion [above](https://gitter.im/red/red?at=5c3e3612ba355012a4442d52) may be too simplistic?
dockimbel
01:21@greggirwin See the -path* root calls for get-action-ptr-path in %runtime/datatypes/common.reds, the path argument is null. The ending * in function names in the runtime library is marking functions calls generated by the compiler. Though, it would be possible for the compiler to store those paths somewhere (in the redbin payload), and modify those -path* functions to pass a reference to them.
bitbegin
01:34routine [a [integer! float!]] should be supported?
dockimbel
01:47@bitbegin Routines map to a R/S function once compiled, so can have only one type per argument.
bitbegin
01:56can't we treated the block as Red type(do type check), and compile it to R/S red-value!?
dockimbel
05:24That could work. I just need to check the type-checking part for the interpreter to verify that it can be implemented without too much trouble.
>> Moreover, your quote is actually the title of an entry, not a "rule". That entry describes a different case than yours (words selection in blocks in your case vs index selection inconsistency in that entry). BTW, that entry should be worth a ticket, as I think this inconsistency is worth examining again. It seems like a side-effect from another departure from Rebol in ordinal selectors.
You always search for and create a general rule when learning new concepts . "Invalid block selector returns none" is a rule when you are trying to understand how path works. Also It is unspecific so you will think that all: a/b or a/b/ce or a/b/ce/ded will return none. While you may consider a long path and block selector be 2 different things, here I see the former as block selector too because it act as a block selector.
About the inconsistency, I will open a ticket either for the error message and the error triggering as
1) Error should state that something in the path has returned NONE
2) Should be investigated if a path with a none selctor in between should return NONE too istead of triggering an error.
21:30[Link to the ticket:](https://github.com/red/red/issues/3743)
greggirwin
01:20@GiuseppeChillemi I commented on the ticket, to clarify that it's not a bug, but a wish.
GiuseppeChillemi
09:13@greggirwin i consider it not a bug to but a an inconsistency. The message, instead, must be changed as it dosn't communicate what is exctly happening.
metaperl
17:45[There are no "instructions" in Red, it's all data (blocks, words, integers, strings, etc...).](https://stackoverflow.com/a/54017174/149741).
garthgoldwater
21:41hey idk if there's a writeup anywhere but I would be more than willing to do a screenshare with @toomasv and record a walkthrough of the code. that gif is INSANELY cool!! or we could just go over it and then i could write up an article (it's a littl ehard to find and navigate all the messages so sorry if this is redundant)
dander
22:03for others, I believe @garthgoldwater must be referring to [this post](https://gitter.im/red/sandbox?at=5c41b4f935350772cf4e3b24) in the sandbox room
garthgoldwater
22:33yeah! and the editor-in-the-editor that I'm struggling to find on mobile
greggirwin
23:26That would be great @garthgoldwater. @toomasv is on EU time, but will surely respond when he's back online.
01:09Hello all, first post for me. I will likely mangle the Markdown, sorry. I'm going to try to drop some GIFs on the post, no clue whether it will work.
Just introduced to Rebol and Red, I use Autohotkey regularly. I'd like to share some executables in AHK that run Red .exes (probably Rebol also, haven't tried it) without a command window popping up.
Not sure where I might post the executables, here is AHK Code, though.
N.B.: You will almost certainly have to run these .ahk files either with your own AutoHotkey installed, or download an executable and run, e.g. 'Autohotkey.exe redrunner1.ahk'. Compiled is certainly better. (redrunner2.ahk - you can drop a Red executable on the file in Explorer, it will run without a visible command window)
; How to run a Red language .exe without a command window?
; Got Autohotkey?
; You're in business!
; No PowerShell, no batch files.
; Launch a command prompt and attach to it
DetectHiddenWindows, On
Run, cmd,, Hide, PID
WinWait, ahk_pid %PID%
DllCall("AttachConsole", "UInt", PID)
; Run another process that would normally
; make a command prompt pop up
;RunWait, %ComSpec% /c ping localhost > %A_Temp%\PingOutput.txt
;RunWait, .\vid-rtf-R.exe
RunWait, %1%
; Close the hidden command prompt process
Process, Close, %PID%
/* vid-rtf.r
Red [Title: "rich text" Needs: 'View]
view compose [rich-text 200x100 data [i b "Hello" /b font 24 red " Red " /font blue "World!" /i]]
*/
(redrunner1.ahk is a GUI to drop Red .exes on, it runs redrunner2.exe in turn on the dropped file. It can be left open for repeated executions)
Gui, new
Gui, Add, Text, , Drop a Red exe here.
Gui, show, w200 h100, RedRunner!
return
GuiDropFiles:
file := % A_GuiEvent
RunWait, %A_ScriptDir%\redrunner2 %file%
return
Escape::
GuiClose:
ExitApp
(rrr.ahk is a one-shot GUI for running Red .exes with no command window)
Gui, new
Gui, Add, Text, , One-shot Red exe runner.`nDrop a Red exe on the GUI!
Gui, show, w200 h100, RedRunner!
return
GuiDropFiles:
Gui, Submit
file := % A_GuiEvent
DetectHiddenWindows, On
Run, cmd,, Hide, PID
WinWait, ahk_pid %PID%
DllCall("AttachConsole", "UInt", PID)
; Run another process that would normally
; make a command prompt pop up
RunWait, %file%
; Close the hidden command prompt process
Process, Close, %PID%
ExitApp
Escape::
GuiClose:
toomasv
04:38@garthgoldwater Hello! Did you refer to [this](https://gitter.im/red/sandbox?at=5babe5ee4d320a463bfabfaa) gif?
garthgoldwater
07:25yes that one and also the one where you make a visual editor in another visual editor (if that makes sense)
07:26honestly a walk through of any of your projects with red would be valuable to community members and newcomers IMO
07:30itz like 2:30 AM in the US right now so I might be worse at writing right now but I think your projects get to the core of what's exciting about red in a way that would be really helpful for outreach if explained even a little but
07:51we can/should move to PM to coordinate or if you prefer email mine is garth@stilllife.studio
07:52monday anytime would work really well for me, Sunday is a maybe. any other time next week is good
dander
08:36Hi @winterlaite, thanks and welcome. If you don't want to see the console window, you can also compile with -t Windows to produce a gui-only executable.
17:23@toomasv Just saw your "syntax-highlighter" which is (also) a code-viewer with many qualities already and more promises! Small suggestion: in the action code for the Dir... button, it needs show files otherwise they don't show up. I continue playing with it. The help tips are great.
18:47i must go to sleep.....I will go to work tomorrow.....see u tomorrow....thks.....good night~
gltewalt
18:48Ok. When you come back, try red/help room so more of us can try to help you
Oldes
06:26@c61292558 as there is no codec for dwg files.. you cannot expect loading this file and being able to work with it. At least in some user friendly way.
09:26Btw... DWG is proprietary and complex binary file format. There are only _reverse engineered_ specification like: https://www.opendesign.com/files/guestdownloads/OpenDesign_Specification_for_.dwg_files.pdf
If you want just to parse some data from DWG, maybe it would be easier to convert it to plain text DXF file and work with it. https://images.autodesk.com/adsk/files/autocad_2012_pdf_dxf-reference_enu.pdf
uri
03:52Anyone able to help me run a red file? I'm on MacOS with red 0.6.4 trying to run red print_something.red where print_something.red is just print "hello" I get the following error *** Error: Red header not found!
9214
03:54@uri does your script contains a mandatory header? FYI, we have a [dedicated room](https://gitter.im/red/help) for asking questions about your code.
uri
03:57Thanks for pointing that out, will use that room in the future.
18:58Hi! Has anybody run latest Red (0.6.4) under Linux with latest Wine (4.0)? On my system it compiles console, then a window shows for a fraction of second, and closes. Last error message I get is 002d:err:seh:raise_exception Unhandled exception code c0000005 flags 0 addr 0x41db83.
rebolek
19:44@loziniak AFAIK Wine is unsupported. It would be great to find what the missing features are, but I believe those problems should be reported to Wine, not to Red.
loziniak
19:48@rebolek yes, I've read about it. Just hoped that somebody had some positive experience, or maybe some workarounds exist :-) BTW I've managed to run *Red Wallet* under Wine, although with errors.
rebolek
20:56@loziniak Interesting! Can you post those errors into a Gist for example?
loziniak
22:00@rebolek probably I'll disappoint you a little, because it works only in [my softwallet fork](https://github.com/robotix-pl/wallet/tree/softwallet), where I [disabled](https://github.com/red/wallet/compare/master...robotix-pl:softwallet) hardware wallet code. The error message is (probably due to wine networking problems):
$ wine wallet.exe
002c:fixme:dwmapi:DwmIsCompositionEnabled 0x32fe40
002c:fixme:win:RegisterDeviceNotificationW (hwnd=0x20074, filter=0x32f780,flags=0x00000000) returns a fake device notification handle!
002c:fixme:winhttp:winhttp_request_QueryInterface interface {06f29373-5c5a-4b54-b025-6ef1bf8abf0e} not implemented
002c:fixme:ole:CoCreateInstanceEx no instance created for interface {06f29373-5c5a-4b54-b025-6ef1bf8abf0e} of class {2087c2f4-2cef-4953-a8ab-66779b670495}, hres is 0x80004002
gltewalt
23:47There are anonymous Red examples on Rosetta Code - are the any redbol gurus who would be willing to audit the submissions?
gltewalt
00:07Or submit alternative entries if the originals are not idiomatic?
greggirwin
18:05Do you have links, or is there an easy way to find them on Rosetta Code?
OneArb
20:26@rebolek Regarding Wine the exact situation may call for regression Testing as a couple Red versions ago seems to work fine on Linux.
It is unknown if new Red features is the cause it or if a new Wine version does.
Does Red run ok on Windows 7?
Just in case, making sure Red runs on Wine opens the door to running on MacOS
22:19As a long-time crossplatform developer, the Macintosh is going through some a period of very poor quality control. The latest Mac OSX Mojave broke printing of Carbon library programs until 10.14.2; and the previous version also broke printing until the .3 release several months later. The iPhone and mobile devices make so much more money for Apple that their founding computer products have lower quality engineers, and their QA leaves a lot to be desired. One of Apple's subsidiaries, Filemaker, which makes the rough equivalent of the Access database, but even better in many regards, previous versions have been broken by the latest OSX. So i had to take the unusual step of running Windows inside VMWare Fusion to run an Apple product Filemaker 13. It is provable beyond a shadow of a doubt that Windows does a better job of backwards compatibility. By the way VMWare Fusion is a very reliable product, and a wonderful way to run Windows. So anyone who really wants to run Red can easily use VMware fusion, with very little inconvenience. Just absorbs about 2GB of RAM. Although the Macintosh desktop market share has been below 10% overall for a very long time, it is over 90% in certain industries, like graphic arts, prepress, and has extremely high shares in A/V production, and of course to develop for iOS you pretty much have to use a Mac, and the iTunes App Store is a gigantic success. I myself created 100 apps, and iOS is a wonderful simplified version of OSX that is easy to develop for. I would venture to say that the iOS market is far more important for Red than the desktop Mac market. There are hundreds of millions of iOS devices out there, and the vitality and quality of the IOS software is unmatched.
22:23here is a link showing that mobile browser usage is over 50% for IOS:
22:25So this is why i say iOS is the big deal, vs. Mac desktop which is probably only 3% of desktop user base worldwide. In fact, the Chromebook market is growing so fast, that I expect it to exceed Mac desktop any day. The schools have voted, and they like Chromebooks because it is an intrinsically simpler product to administer.
22:35I would estimate from strictly an active user base, the most important platforms economically are 1) IOS, 2) Android, 3) Windows desktop, 4) Linux server, 5) Mac desktop, and 6) Chromebook, and Chromebook on the rapid upswing. iOS has a lot of paying customer, and although Android outnumbers iOS 4:1, the truth is that the active paying customers that create a vibrant ecosystem are important.
22:36Apple is very fortunately to have the richest segment of customers in every country. Steve Jobs used to boast about the quality of his customers, and he wasn't exaggerating.
giesse
00:42@CodingFiend_twitter with the caveat that what you say is valid for the US, but not the rest of the world. The US is mostly iOS, most other markets are mostly Android. So it's not such an easy choice, *especially* given that it is extremely hard to develop your own toolchain for iOS. (In the sense that Apple fights you every step of the way.)
OneArb
00:52@CodingFiend_twitter I tend to agree Mac may be underated as a Red target in particular repositioned as a blockchain friendly product.
Your comment make realize and wonder whether IOS and Mac customers are part of a higher income bracket.
Another consideration is what market Red is going after. If startups are considered at the forefront of technological innovation, working Red into a startup project, ideally blockchain related, may be all Red needs for greater visibility.
A Windows only product is everything I have been trying to jail break from when getting interested in Rebol.
I am poking in the Ren-C direction, ANSI C89 embeddable is pleasing as C remains the top dog in terms of portablility.
Within a couple of years Webassembly might be the way to go.
The Wine team made it clear it gives priority to "regressions":
8.8 My application worked with an older version of Wine, but now it's broken!
This is called a regression. Please perform a regression test to identify which patch caused it, then file a bug report and add the "regression" keyword: we'll pay special attention to it, since regressions are a lot easier to fix when caught early.
I mention this as an option if someone feels they need Red Wine...
@CodingFiend_twitter VMWare VirtualBox run great, now go convince people to install those just to take a look at your app.
CodingFiend_twitter
03:42I wrote a popular CD labeling program called Discus. It sold about a million copies (mostly through OEM bundles for under $1 a copy so don't get too excited), but did manage to sell about 60k copies for about $40 each, so that was good. Anyway it was a cross-platform Mac + Windows CDROM written in Modula-2, using a QuickTime emulation layer on Windows, and I kept records of the user base, and it was majority Macintosh, even though the PC installed base was 10:1 windows, from a money standpoint, there is no question that the Apple user base is way richer and more active from a software purchasing point of view. The apple users are particularly rich overseas, where Apple products command a huge price premium. The iPhone for example in Brasil is about USD$2000. Anyway as for developing for iOS i did the first 90 apps using Objective-C in XCODE, but then switched to Adobe AIR, because using AIR i could export to both iOS and Android from a single code base. From a dollar standpoint i think that the 4:1 unit advantage Android has means nowadays the Google Play store is about as much money as the Apple App store. So it is important nowadays to ship for both IOS and Android, and i believe Red would be best served if it attacked both at once, because that is what the developers need. The Apple app store is a brutally competitive environment, with literally millions of apps, poorly indexed, but the user base is wealthy, and since Apple kind of forces users to register a credit card, they are only a touch authorization away from buying something, so it is now i believe the largest software marketplace for individuals. Of course corporate subscriptions to cloud products like SalesForce and MS Office are larger dollar-wise, but the mobile App stores are now many times larger than the PC shrinkwrapped market, and larger than Xbox and Playstation software sales. When Jobs invented the App store, they created about categories, and they have barely increased the number of categories, which is absurd. Once i did an app that had fine art paintings in it, and there was a picture of Adam and Eve nude. Nothing fries Apple's gears like nudity, and it was stuck in the approval process for months. After wrangling back and forth i finally escalated to a manager, who had to admit that Adam and Eve would not be wearing much, and it was approved, but while i had this high level person's attention, i pointed out that the Library of Congress uses the Dewey Decimal system for indexing, which easily expanded to include new categories, and although it has flaws, something like it would be ideal for sorting all the apps, and the rep remarked that he had been to a library once. Yikes! i realized then that Apple was being run by youngsters who knew very little of the world, and for sure don't get out of their spaceship much!
04:12But i completely agree, that native platform support is the only way to broadly succeed on a machine, that very few people are sophisticated enough to run VMware Fusion, as easy as it is to use, it is just too many extra steps for many people.
04:15Anyway my point in brief is that it isn't just raw popularity, but popularity weighted by economic power that really matters. This is why Linux desktop is a most pathetic platform, with a hard-core base of people who are opposed to buying software. I do think that Linux server is a very vital area, especially with all the cloud hosting companies that are making it oh so easy to spin up a container for however long you need it for. The elasticity of computing is a modern marvel!
Thanks for the run down on your software marketing success.
The cloud based might as well run Linux under the hood and half the web run on Linux servers.
MacOS can provide a one step install through Winebottler and Linux through one step install through a Snap package including Wine.
That's two platform to support with very little effort out of a single Windows code base.
gltewalt
04:59@greggirwin Yes, all Red submissions should be under this:
https://rosettacode.org/wiki/Category:Red
CodingFiend_twitter
07:44Upon further reflection, i think that Red is more of a platform independent language than most; and thus it competes not so much against conventional languages like C or C++ which always host their functions using huge API libraries, but is instead more directly competing with Unity, Qt, Adobe AS3/AIR, and Java, all of which basically create their own OS that you live inside, and are quite platform neutral. Red's graphical system for example is very platform neutral. There are a lot of game-generation specific platforms that don't get much press, like GameMaker, Corona (which uses Lua as the scripting language inside), and these are also direct competition that Red has to surpass. I know that the initial target domain is Crypto, but Red is far more general than that tiny sliver of the programming space, and with the appropriate supporting modules and tooling it can compete against these tools. The wrinkle in all this, is that the effort to be cross-platform is considerable. Weird quirks abound in computer systems, and making something regular and rational is a challenge when the designers of these systems which are inevitably chaotic committees always create a mess. A huge number of people use Unity, which is a 3D engine, in pure 2d form, just because it handles the platforms they need. Python is super cross-platform, however, it never evolved as a game platform. Game playing is split across wildly diverse hardware/OS combinations, and i would estimate game programming is half of all programming. There are lot of games, and people are very interested in making them. I think text massaging would be another area Red could get known for, as the Parse system of Rebol/Red is super powerful, and Python's simplistic lists data structure tops out pretty quickly. Like any plant, you start in a crack and grow. I myself would most like to bump off JS, which is an uncredited 99% copy of ActionScript 2, and it is a great tragedy of history that the browser companies didn't adopt AS3 many improvements like static typing. Red is growing quickly, and I caution you guys to make sure you have a very good keyboard, because carpal tunnel syndrome has felled many a pioneer!
greggirwin
08:44Thanks so much for the input and thoughts @CodingFiend_twitter. Much appreciated.
amreus
10:39If the doc for round says "Returns the nearest integer." then is it correct to return a float!?
hiiamboris
10:43@amreus I think the meaning is an integer number rather than a value of integer! type
amreus
10:56@hiiamboris Maybe I'm used to Ruby and Python which return an Integeror int unless a precision is used.
nedzadarek
11:01@amreus I think it depends on the n argument:
11:03@nedzadarek That makes some sense given the extensive datatypes of Red.
hiiamboris
11:08@amreus by default (and it makes sense) round returns the same type as the argument, but sometimes an integer! type result is desired. In this case use round/to x 1
amreus
11:16@hiiamboris I saw that refinement but don't quite get what scale means. I think using 1 can be thought of as round to the "ones column" or first digit left of decimal point? In which case using 10 would round to the "tens" column? In which case the scale is related to the base of a number?
11:18Not asking for an extensive answer at the moment. Just a basic understanding. I can always use to-integer on the result .
hiiamboris
11:19@amreus it rounds to the multiples of scale around zero (which is 1.0 by default):
11:20@hiiamboris Oh I'm over-complicating things as usual. :)
11:29So the help doc string "Return the nearest multiple of the scale parameter." means exactly what it says. :grimacing:
nedzadarek
12:28@hiiamboris why not just to-integer? I mean if you are rounding to the nearest number (for example 3 in your last example) then it makes sense. If you just want to get integer! then to-integer makes more sense.
amreus
12:31@nedzadarek I would say in order to preserve the type. It's more general.
12:35@nedzadarek Maybe I want an integer. Maybe I want to preserve whatever type I used which in my example happened to be an Integer. My thinking was too narrow - Red was already ahead of me.
nedzadarek
12:41@amreus I meant: If I want an integer! (a: 42 type? a ; integer!). For example I have 42.0 from a round 42.33. I want this number to be of type integer!. round/to X 1 may do the job but it doesn't tell you "I am converting a float (or just just a value) to the integer!. /to doesn't show an intent. to-integer, in this case, is more readable... at least for me.
>> print [round/floor/to y 1 round/ceiling/to y 1]
1 1
>> print [round/floor/to y 1.0 round/ceiling/to y 1.0]
0.0 1.0
greggirwin
06:31I'll look at @hiiamboris's ticket shortly, but I can speak to the design of round.
1) It's a single function, with refinements, rather than separate funcs. It was a battle, as separate funcs would be very simple (which is good). The big win, though, is when you do help round, you can see all the different ways to round things in one place, and they all have round at the call site, to make the intent clear.
2) It's flexible. We could have gone with rounding to N decimal places, as many other langs do, but that's a fairly coarse solution. By using a scale parameter, it can round to any precision, which is handy for all kinds of things: time values rounded to 15 minute intervals (which I just found doesn't work! Somebody open a ticket for supporting time! as the scale arg.), interest rates that are commonly in 1/8ths of a percent, increments for imperial fractions, etc.
Side note: In the R2 version of round, an integer! is the default type returned, as that is handy for use with loop funcs (which may not always support non-integer args). It's also a mezzanine in R2, so you can see the source for it easily. Ladislav Mecir gets the credit for that amazing code.
Now I need to look at @hiiamboris's ticket, as percents seem to have an issue too.
>> round/to 3.881% .125%
== 3.88125%
06:34OK, time! currently delegates to float/round and percent! inherits it directly.
17:38@CodingFiend_twitter Thank you! Very interesting stuff! Just to add some fresh stats [Apple Now Has 1.4 Billion Active Devices Worldwide](https://www.macrumors.com/2019/01/29/apple-1-4-billion-active-devices/), 900 million of those are iPhones.
rebolek
07:27In Rebol, it's possible to write empty binary! using n#{} notation:
>> 2#{}
== #{}
>> 64#{}
== #{}
However in Red, it throws an error:
>> 2#{}
*** Syntax Error: invalid integer! at "2#{}"
*** Where: do
*** Stack: load
>> 64#{}
*** Syntax Error: invalid integer! at "64#{}"
*** Where: do
*** Stack: load
12:13Hello. Thank you all team for work on Red. I very exiting when use this language. I am inspired by live coding features and work on live-coding environment . Here result. [EmptyCore](https://github.com/schwarzbox/EmptyCore) 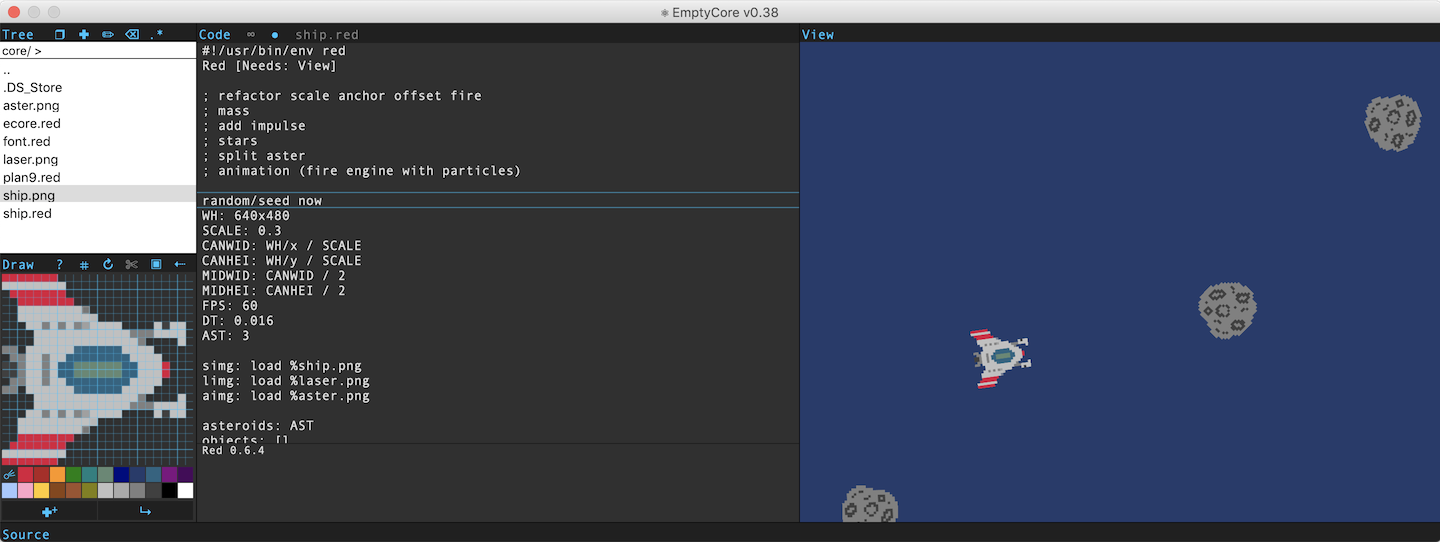
12:40@schwarzbox Interesting project... but doesn't run on Windows unfortunately :( A few suggestions: - why not use compose instead of rejoin? - why not define your print&Co functions instead of replace-ing them?
18:50@schwarzbox Very nice! From now, it only opens in linux Red/GTK and it needs some improvements to be fully working. Good motivation to make it working...
19:50@hiiamboris 1. I try to test on Windows. 2. Good advices. I try to check how use compose in this situation. And you idea, about func so simple and I understand that I am just play around “homiconity”
20:08@rcqls And I hope it open in MacOS too :-) in this case I have only problem with Windows. Yes, I have some ideas. Small editor for simple images, maybe tabs, but all of this after I improve parsing algorithm, improve line numbers, color syntax, fix hotkey crashes. So thank you.
20:12@rebolek @endo64 @BeardPower @moliad thank you. And maybe somebody know, how I can change : 1. background color for text-list face 2. Cursor color for field face.
hiiamboris
20:18@schwarzbox 1st is just color facet of the text-list, 2nd you can't change (the OS chooses the color)
greggirwin
22:55@schwarzbox very cool. I'll check it out for real once it runs on Windows.
22:56I predict that there will be a LiveCode/IDE showdown before the end of the year. :^)
22:57Not a battle to the death, but different takes on how to do things, each learning from and taking pieces of others.
rcqls
08:57@schwarzbox My first OS is macOS and indeed it opens on macOS … Good program of improvement.
schwarzbox
09:05@hiiamboris I try to declare “print” function, and have one problem. How can I define function which takes zero or more arguments. I know how it works in Python, Lua.
09:06@greggirwin Maybe :-) I start learn Red as side "project" and now try to manage time for stay productive in my main tasks. Looks like I fall in love with Red :-)
rebolek
09:07@schwarzbox Red functions have fixed arity. You can pass variable number of args in block! for example.
hiiamboris
09:10@schwarzbox I think your own print should be compatible with the native print, no? ;) Otherwise, you can include unset! type into each argument of your print and live in constant danger :D Also let's discuss further matters in the [help room](https://gitter.im/red/help) to keep this one clean for the team.
schwarzbox
09:12@hiiamboris @rebolek Thank you. I try. See you in "help room"
GiuseppeChillemi
06:58@rebolek , where I could find the source code of function creation, args passing and interpretation of the args block ? Or Maybe I should ask to @9214
16:56Hi Folks, is there any way to have red and all dependencies inside one folder? I have to deploy a solution that will be hosted at hostgator, because they will not install dpkg --add-architecture i386 apt-get update apt-get install libc6:i386 libcurl3:i386 apt-get install libc6:i386 libcurl4:i386
20:29No, it doesn't support Docker, I will have to run it at cgi-bin directory, you know
x8x
15:18@djrondon Looking at Hostgator offers, if you have the $3.84/mo WebSite builder offer, you wont be able to run Red, you would need at least the $29.25/mo VPS offer but you can get cheaper offer at around $5/mo at https://www.digitalocean.com/pricing/ or you can have a 12 months free use at https://cloud.google.com/free/ . There are of curse many other options. If you really have to run in cgi-bin, maybe have a try with Rebol http://rebol.com/downloads.html (there is a Linux 64bit build as well).
rebolek
18:05https://rebolek.com runs on skysilk.com and I'm also considering ovh.com
lepinekong_twitter
21:19@rebolek ovh sucks for support though they're french like me will never go back to them, on what skysiklk plan ? Can I try with 2$ plan ?
22:44This RED was one of the candidates for what became the Ada language. It didn't make it.
burque505
23:49@lepinekong, might I ask if you have considered doing the Part IV of your "Red for Hopeless Programmers" series? I'm referring to this quote: "How to send keystrokes to automate your favorite windows's application (part IV)." I use AutoHotkey quite a bit, so this aspect of using Red would be very, very interesting to me. Thanks!
PeterWAWood
01:16@burque505 [Here] is a very basic example of sending keystrokes to Notepad. It may be of some help.
08:31What? another Red lang? also it use square brackets!
*Once an abstracton is defined by a systems programmer, application programmers can use the abstraction without having to understand the advanced features used in its implementation*
Lovely but too late :-)
rebolek
08:56@lepinekong_twitter thanks for info. They're french? I see, I don't want hosting that's constantly on strike :smirk: I've got two plans on Skysilk, one is 2 CPU/8GB RAM/100 GB SSD that I got for free during the beta phase, but it's too much for me, so I'm moving it to 1 CPU/2 GB RAM/30GB SSD which is $5/month. for $2 you get 512RAM which is too low for me, I think.
22:33@burque505 I think the -c and -r options are mutually exclusive. One creates a shared library and links the executable to it, the other creates a stand-alone executable. It looks like -r takes precedence if both options are given.
22:56@amreus is correct. The readme in https://github.com/red/red explains them. More specifically, dev mode (-c) makes compiling a *lot* faster, because it doesn't have to recompile the runtime each time.
20:54@JacobGood1 See GTK room. @rcqls has done great work!
habibalamin
22:34Anyone know how I can get a file drop zone working with Red?
22:36Ideally, I'm looking for a cross-language or even cross-platform way of doing this. How are things like NSDraggingDestination implemented?
22:37How do drop zones work under the hood for a graphical app?
22:38How can one app know what is being dragged from another app or that the thing being dragged is on top of it? It seems impossible to do without going through the platform's GUI framework.
22:38Or through some OS layer that the apps share.
rcqls
00:04@toomasv Thanks! And at least this wonderful animated code/Showcase/ellipse.red is working...
00:05[](https://files.gitter.im/red/red/2ErX/Capture-d_ecran-2019-02-13-a-01.02.12.png)
burque505
00:14@habibalamin, I have similar questions. I got the following response in red/help: >@burque505 drop-file event is not implemented yet, here you can see @Oldes 's PR for that: https://github.com/red/red/pull/2838
15:21Red supports Cross Compilation, so you could add a new target ABI to it and implement it there. If the CPU is already part of the supported list, it should be relatively easy to do, if you have the low-level knowledge of the ABI. The fact that there are already 2 posix based ABIs (Mac + linux) may help you with the implementation.
16:10the proper channel for this would be in red/red/system since people savvy with low-level Red/System are listening there... https://gitter.im/red/red/system
habibalamin
19:49@burque505 I've already seen that PR, but unfortunately, it's Windows only and I'm looking for a macOS solution. Sorry, I should have made explicit the platform I'm targeting.
habibalamin
12:37I think I can contribute drag and drop functionality for macOS, and we can hopefully move this PR forward https://github.com/red/red/pull/2838. However, I need some help understanding how to import built in Red runtime files for use. I can't even get a simple print read-clipboard call working.
9214
12:52@habibalamin can you be more specific? read-clipboard should work on macOS, and files can be included with #include directive. Let's move to [/help](https://gitter.im/red/help) room though.
greggirwin
19:03@ehmry Someone did work on a FreeBSD port as well, which you can cross compile to, but these are big projects.
19:04@habibalamin, I'd like to see that PR move forward as well. One thing holding it up is that there was no work done on the mac side yet, which we feel is important.
spTorin
13:09https://domains.google/tld/dev/ need register red-lang.dev :)
21:38 Hi, I wish to inform that someone at UltraEdit forums took care of my support request for the REBOL UltraEdit wordfile which I am using as base for the RED one. They solved some of the problems that acient wordfiles has (I think it is mine, then changed from Gregg or Sunanda, I don't remember who, and then back in my hands). Thanks to this wordfile we could have a list of functions, objects and methods (If I have correctly explained how they works). Above is an example of its object/functions list window:
22:16Include has been added from the previous wordfile editor, I have never used It.
22:17I do not Remember about DO , please, take a look at It
JacobGood1
03:14hey guys, I am watching a video "What Functional Programming can Learn From Smalltalk", I think a lot of what is in this video is also relevant to red: https://youtu.be/baxtyeFVn3w
18:30@moliad > @GiuseppeChillemi cool that ... though I use my own literate Rebol setup which doesn't use the actual code.
Interesting, could you post the remaining of the windows, and a code example? I find interesting and worth having a look at your way to organize things.
meijeru
18:39@GiuseppeChillemi The doc is at [https://github.com/meijeru/red.specs-public/blob/master/specs.adoc](https://github.com/meijeru/red.specs-public/blob/master/specs.adoc). You could copy the words out... But I got them by program first:
Red []
list-by-type: copy []
list-alpha: copy []
write %word-list-by-type.txt ""
write %word-list-alpha.txt ""
foreach w words-of system/words [
unless unset? get/any :w [
t: type?/word get/any :w
s: to-string :w
either find [function! routine! action! native! op!] t
[
insert/only tail list-by-type reduce [
'function! rejoin [s " (" uppercase first to-string t ")"]
]
][
insert/only tail list-by-type reduce [t s]
]
insert/only tail list-alpha reduce [s t]
]
]
sort list-by-type
sort list-alpha
old-type: none
foreach e list-by-type [
if old-type <> first e [
write/lines/append %word-list-by-type.txt first e
old-type: first e
]
write/append %word-list-by-type.txt " "
write/lines/append %word-list-by-type.txt second e
]
foreach e list-alpha [
write/lines/append %word-list-alpha.txt form e
]
19:16Yes, I will need to look at some code to understand how graphically you organize it.
moliad
19:18I'll zip you all you need, including a code sample and some instructions on how to set it up within Uedit's scripts and keyboard shortcuts. (via email)
GiuseppeChillemi
19:20I have found in my arkives a message from from Tom Colin on 08/dec/2007 on REBOL ML. He replied to my request of a way to print REBOL words. Here is the code he posted.
Rebol [
File: %gen-syntx.r
Author: "Tom Conlin"
Date: 10-Apr-2003
Title: "generate syntx"
Library: [
level: 'intermediate
platform: 'all
type: [function reference tool]
domain: [text]
tested-under: none
support: none
license: none
see-also: none
]
Purpose: {
generate the list of defined 'words separated by their 'type
I used the list as a basis for syntax coloring in an editor
works with versions before core 2.5.5 but does not return natives in core 2.5.5
}
to-use: {run the script then use the contents the file 'xyz-f'} ] echo %xyz-f
help datatype!
echo none
xyz-a: read/lines %xyz-f
remove xyz-a
xyz-c: rejoin [";;;" tab system/product tab system/version tab now/date newline]
foreach xyz-d xyz-a [
xyz-d: pick parse xyz-d none 1
echo %xyz-f
do rejoin ["help " xyz-d]
echo none
xyz-b: read/lines %xyz-f
;print [xyz-d xyz-b/1]
if equal? "Found these words:" trim xyz-b/1 [
remove xyz-b
insert tail xyz-c rejoin [";;;;;;;;;;;;;;;;;; " uppercase copy xyz-d newline]
xyz-e: rejoin ["(" head remove back tail copy xyz-d ")"];;; pre
/core-2.5.5
foreach xyz-g xyz-b [
xyz-g: parse xyz-g none
print [xyz-g/1 xyz-g/2]
if all[ (string? xyz-g/1)
(not equal? xyz-g/1 "")
(not equal? "xyz-" copy/part xyz-g/1 4)
any [xyz-g/2 = xyz-e xyz-g/2 = xyz-d]] [
if equal? xyz-e "(op)" [insert xyz-g/1 " " insert tail xyz-g/1 " "]
insert tail xyz-c join xyz-g/1 [newline]
]
]
]
]
write %xyz-f xyz-c
It still works. Thanks again Tom, everywhere you are !
19:21@meijeru thanks it works. I will change the UltraEdit wordfile.
20:20@JacobGood1, someone else must have posted that link before. Once the video came up I remembered having seen it.
JacobGood1
20:30@greggirwin Smalltalk environments are very impressive aren't they?
One thing I found interesting is how the speaker kept asking "why we don't have such things in our language." He kept saying that the features of Smalltalk have nothing to do with the language itself, that any language could implement these features. He also spoke about how Smalltalk's community is tiny, yet they have been able to accomplish some incredible things. I wonder if the language itself is correlated with this type of productivity, even though that idea was downplayed by the speaker.
9214
21:38@JacobGood1 IIRC Siram is an avid Shen follower?
JacobGood1
21:44He is definitely a Shen fan, not sure about how much he uses the language though.
gltewalt
21:48I think it can do all of that because it’s a living image.
22:34There are always pros and cons. The hyperproductive developer is one who wrote all the code in the system, so they know it intimately and can move faster, more safely. Anecdotally, this is where Smalltalk wins (and some others as well). You have a much higher percentage of developers who work on things long term, and are also expert in the use of the tool. Mainstream langs and developers as a commodity can't compete, though they win in other areas. e.g. risk mitigation in some cases (scale is the enemy for any tool there). Large projects are just plain hard, so tools that help reduce project size are a win.
moliad
22:41one thing all people forget and as a manager I am starting to appreciate more. there is no substitute for programmer skill.
22:41use any language, in any production environment and if you have a team of smart people, it will work.
22:43this was one of the claims of the people behind agile dev btw.
22:45smart people have the main quality that they get shit done, no matter the environment they work in. they'll be the best mechanic, the best programmer, painter, shop worker. it matters not.
22:46and SMART isn't based on I.Q. its based on attitude, will and creativity. the most intelligent person in the Room can also happen to be the biggest idiot.
dsunanda
23:06@moliad It's a standard industry truism that the better programmers are 10 times as productive as the typical ones - in any language. Some discussion of that here: http://www.devtopics.com/programmer-productivity-the-tenfinity-factor/
JacobGood1
02:49@moliad that may be the case, however, it strikes me as an odd argument to make in a channel dedicated to making a tool (red) that promises to increase programmer productivity.
moliad
04:42smart people tend to do the best with tools which let them be smart. Things like agile dev, functional langs. Red fits that bill too cause a lot of the language is meant to providing tools to build your own purpose specific tools and dialects. things like binding allow you to build your own functional language (I known I've built at least two already).
04:45other paradigms like OOP are meant to even out the field, a bit like Apple assumes and treats every one like an idiot. very smart people will be stifled, even if they will be more productive than their peers, IMHO they cannot attain their full potential.
djrondon
11:33Guys, is that an opportunity for Red? https://venturebeat.com/2019/02/18/facebooks-chief-ai-scientist-deep-learning-may-need-a-new-programming-language/
04:59I’m looking for some advice / guidance from the community. I need to do some very simple 3D stuff for a project and I am looking for a way to do it in Red. I have found the 3D-MATH library on git but it is a bit too raw for me to utilize (beginner programmer). I also found r3d from Rebol. The r3d demo with the robot arm is about the level I would need. Nothing more complex would be needed. Is there a version of r3d available for Red? For the time being, I will do part of my simulation in 2D via DRAW. I thought I would ask early on in my project, just in case there is an option that I have not found yet. Thanks !!
rebolek
07:04@BuilderGuy1 If you want to do 3D in Red (or Rebol, it doesn't matter), then you need to translate 3D coords to 2D. So in the end you will always use Draw.
17:32using OpenGL isn't that hard, if you just want simple shading... there was a simple OpenGL shim library in Rebol2 which should be relatively easy to port to red/system
rebolek
19:48True, but it's still additional work, compared to doing something directly in Red.
moliad
20:17yeah but it will be thousands of times faster :-)
20:18if r3d works though, it may be enough.. :smile:
rebolek
20:25> I need to do some very simple 3D stuff ... The r3d demo with the robot arm is about the level I would need. Nothing more complex would be needed.
20:26So suggesting OpenGL is bit of overkill I guess :smile:
BuilderGuy1
20:49Yes, eventually OpenGL but not yet :-) I still have a lot to learn about programming (...and Red) so simple and accessible is the order of the day ;-) I will revisit r3d and see what I can do with it. I'm also attempting to script the Cheetah3D modeller (javascript) to do the same thing. Docs are very limited and I'm new to javascript. MUCH learning to do :-)
rebolek
20:52Porting JS code to Red is not very hard. But porting Rebol code to Red is much easier :smirk:
JacobGood1
22:05@BuilderGuy1 I suggest using a game engine, since you said you are new to programming in general
03:10since red is working so hard in the area of crypto contracts, here is an interesting article on some of the flaws and attack points of recent history. https://www.technologyreview.com/s/612974/once-hailed-as-unhackable-blockchains-are-now-getting-hacked/
9214
03:41@CodingFiend_twitter well, no, the article is extremely bad at pointing out (new) attack vectors, and its author spends too much ink on restating the obvious, shilling the story about network upgrade's delay and EIP 1283 instead.
Majority attack applies to Ethash PoW algorithm that Ethereum Classic hard fork runs - a rather interesting observation in the light of @x8x's recent post in /blockchain room. Reentrancy (the reason for Constantinople delay) is as old as Ethereum itself, so as contract's code immutability - so much for a "recent history" and clickbaity "a whole new can of ~~worms~~ bugs"... All of these (and much more) are well-known to the Red team, and I've personally gathered many papers on the subject, and have a few to recommend to an interested reader: * [A survey of attacks on Ethereum smart contracts](https://eprint.iacr.org/2016/1007.pdf) * [A Concurrent Perspective on Smart Contracts](https://arxiv.org/pdf/1702.05511.pdf)
CodingFiend_twitter
19:22I figured you guys would have the real inside story on Crypto contracts, and i guess that once again journalists do a slight disservice by spreading incomplete and often misleading information. There is a crying need for better tech journalism. I find for example in the area of climate change research, a complete lack of candor as to how inaccurate their models have proven to be, and how intrinsically when you put in differential equations into a model you inevitably get exponential results, and how much data fudging goes on. We really need a better trained kind of writing corps, because there are big decisions that have to be made about all these different things. In the case of Crypto, we clearly need to address the high cost of transactions in the credit card industry, and the inefficiency of the lending system which is now averaging 17% on consumer debt as reported today in the WSJ. It is also an interesting issue in Crypto the consumption of electricity to perform proof of work. That will have to bend towards proof of stature, and i can imagine a cooperative system for blockchain that achieves integrity through dispersion of paid parties that are diverse in interests not to collude. I can well understand why Red has selected Crypto as one of its foundation cracks to grow out of; every new language has to take strong root in some niche in order to grow well. Amazon after all started just selling technical books...
rebolek
21:00Lot of points here...I'm not sure what I can make of the climate change research, being on fourth hottest year in row, but let's get back to crypto - what high transaction costs in credit card? As a customer, I have free and fast transactions. ETH is close with almost free and almost fast transactions and BTC is expensive and slow.
BeardPower
22:17@rebolek ETH is all but cheap and fast. IOTA, Nano, DigiByte, ByteBall. Those are cheap or even free and fast.
CodingFiend_twitter
00:16With regards to climate research, i recommend watching the YouTube talks from Burt Rutan who many consider the greatest living aeronautical designer, who has studied the raw data as few of us have the time or interest to do. You either have looked into the data and the models or you are just blindly taking someone's word for it. The short term data is constantly being adjusted, and as one of my professors at MIT once taught us, you should allocate a single person to adjust the data because having multiple people tweaking the data can lead to poor conclusions. With regards to credit card processing fees, in the USA we have a near monopoly with First Data which is the gateway for something like 75% of all transactions, and has classified them into over 100 categories of credit card, and the rate they charge is approx. 3% of the gross. In the debit card world it is just as corrupt, as although the Federal Reserve which runs the debit card system mandates a fee of only 0.05% plus 20 cents, there is a loophole, and the average rate charged for a debit card was 1.5% last year. You can see the actual details on the federal reserve site, i am doing this from memory. Somehow the banks cheat and run debit cards as credit cards so they get the 3% and if they do this for 50% of the transactions you will get a net average rate of 1.5%. This is a huge sum of money, in the hundreds of billions per year given the massive volume, and this comes right out of the seller's pocket and into the greedy, lazy, and dishonest banking system. There is no good reason why debit cards which move money from one account to the other with zero loans extended should extract such a high per transaction fee. I am personally hoping for a disruptor to enter the market. If Steve Jobs had lived, i suspect he may have started a bank; goodness knows apple had the capital to do it, and although a bad tempered fellow, Jobs was quite honest, and i have done a lot of business with apple and they are very strict about money. American express by the way charges about 1/2% more than regular MasterCard/Visa/Discover does. The whole racket of cash back needs to be stopped, as really customers are paying extra for all this skimming off the top. If we could get transaction down to 1/2% that would still leave a ton of money for processing fees, and shoppers would be getting a 2.5% raise in their disposable income. It would be a huge, noticeable effect if someone could crack the monopolies. There used to be competition amongst card companies, but mergers and evolution of the industry have caused other competitors to wither like Diner's club, etc. I am not familiar with the JCB rates, that is the #1 japanese credit card with a giant share in Japan's market. The VISA consortium is owned by a collection of banks who funded it in the beginning. At the start they mailed credit cards to random people just to get it started. It was a very interesting marketing effort in the beginning, crypto could learn a thing or two about how to get people into using a new form of money.
00:25A dollar backed cryptocurrency will likely be the winner in my estimation. Anything to get away from the banking industry which is milking their legacy systems to obscene profits. Everywhere you turn now, there is some monopoly where someone gets a huge sum for running a modest sized database. Maybe it is the ISBN number racket, or the phone number database, etc. By the way, the bitcoin system is something like 100x slower than it would need to be to handle the volume of the US' credit and debit cards, so in its current form Bitcoin cannot possibly be a replacement. I am expecting to see a company modeled after Square that offers a great rate to merchants; that is an instant billion dollar company. Square started out super cheap, but has now graduated to a more typical $20/month + 3%; it used to be per transaction only. That per-transaction only fee would be incredibly successful as many people do seasonal and occasional sales, and want to accept non-cash either via the internet or in person. Note that Square started very cheap and built a huge customer base, then monetized it by raising rates, and even getting into lending, and is now worth 30billion. I am not familiar with some of the other companies in the space like Stripe, etc., but the whole payments space has an elephant sitting in the corner, which is the credit card monopolies.
00:37And i should mention, that although the typical rate is about 3% for credit card transactions, there are lots of add-on fees and upcharges for various options that the banks offer, and the rate can creep towards 5%. In the restaurant industry, which has millions of workers, that industry only nets 20% profit on a good day, so losing 5% to banking overhead is 1/4 of their entire profit. And don't get me started on the evil that is Uber Eats, they were charging 10% last time i looked (it may have dropped) a completely unsustainable rate for a restaurant. And by the way this payment system is also a big factor in the Uber /Lyft empire. Right now those entities are taking about 20% to run the computer systems; you could easily see regional collectives of drivers administered by a computer program that only consumed 5% which would be of great benefit to both the drivers and the consumers. Payment is everywhere, and I think Red could make a taxi service/delivery client + server program that would be awesome. Really to my thinking it is the combination of payment + another service that would make an unbeatable combination. It is strange but disruptors like Square after a few years turn into about the same kind of company as they were disrupting. It is like the US congress, it is a swamp that affects all the people who enter.
BeardPower
00:42Running/starting a bank is all but cheap. You need a lot of money for various licenses, which will cost you from 250k to 2 million USD.
00:43There are a lot of cryptocurrencies out there which target just one thing: money transfers. People have to exchange to fiat money in the end as they cannot buy food with crypto assets.
00:43Another option would be collaborating with a service provider.
02:34@Respectech there's no need to feed speculators and help them with this pump'n'dump move. Not to mention that the original post is discrediting at best.
Respectech
02:38Sorry. That was my knee jerk reaction to someone saying something ignorant about Red.
9214
02:41@Respectech no problem, thanks for weighing in anyway. At least now they won't be misinformed :smirk:
07:26Thought we need to to contact the author as at the end of the FAQ…. So really interesting since it looks like in some aspects to red.
rebolek
07:37Yes, small executable, cross-platform GUI, ...
rcqls
07:44However, it does not seem to be a LISP-like language but it is already bootstrapped and x64 compliant. I am curious to see the GUI part internals….
BeardPower
08:44Wow. V looks very promising. It's syntax is not my favorite but the compiler is blazingly fast.
08:49The developer said that it has the same paradigms as Go.
13:19Red-By-Example: I've made a few minor changes, fixes. Thanks to those who sent corrections. Please note that I shall be taking charge of RBE from Arie. He is not very well. I would like to change it into a wiki, but will mention this in the Docs room.
rebolek
10:35There's system/console/history which keeps input buffer, but what about output buffer? I guess it would be useful too.
14:12@Tovim because in my block, block/1 is function that gets evaluated with path access. In your block, 25 is evaluated to 25, so both values are same.
>> obj: object [f: does [print "Evaluated."]]
== make object! [
f: func [][print "Evaluated."]
]
>> equal? obj/f get in obj 'f
Evaluated.
== false
hiiamboris
20:53This is actually harmful. By writing block/1 you are meaning to do what? To call the first function of a block? What a nonsense. *Most* likely you are meaning to fetch first item. That's just how it reads.
When your path is not numeric, but something/word then on the other hand it's likely a function call or an attempt to get the value of the associated *word*. It reads differently, and in this case evaluation is what you would expect. Yeah I know about get-path etc etc. But I also know from my little experience this is a source of bugs, and affects not just newbies (we're all human after all, and everyone is lazy to spare the extra colon).
Now, I'm not criticizing really. I don't see yet an elegant way how to get out of this situation within the current semantic model. Just wanted to point out that this is a shady area that really could use some improvement - if anyone will be able to figure out how to do it.
rebolek
20:56Why is it harmful? It's just a rule you have to remember - path evaluates, actions do not.
It's all hanging right now on a thin thread called "compiler limitations" (that's why the original collect is still okay). The example by the way shows that it's not just about paths, but about the general "execute it if you wish" policy.
greggirwin
21:531) Can we solve all design issues? No. Everything is compromises. 2) Would having indexed access not evaluate be better? I think we'll be divided on that, but would have to try it to know.
We can find flaws with almost any choice. The more strict, and less flexible and expressive we make the language, the more some people will like it, because it offers more guarantees, and less ways to shoot yourself in the foot. But that is not the design goal of Red. If we maintain consistency as best we can, to minimize surprises, and document these cases, that's a good place to start.
If we want to change deep language fundamentals, that's more work. Sometimes worth it, and always important to keep opens minds though.
giesse
02:34@hiiamboris more special cases is worse in the long run. something/:x evaluates, but not if x is an integer? Or maybe it should depend on the phase of the moon? :P
Function values always evaluate when referenced by a path or word. (Path being a generalization of word, if you think about it - or said the other way around, you can think of a word as a path of only one element.) If you don't want evaluation, use a get-word! or get-path!, or something like fist or pick or get etc.
05:58"Compiled functions don't evaluate functions passed as arguments inside their body code, like interpreted functions do." ([Source](https://github.com/red/red/wiki/[DOC]-Guru-Meditations#compiled-versus-interpreted-behaviors))
giesse
06:56@9214 keep still needs to use a get-word! though, that way it can work in both environments. It's also generally bad practice to use a word! to refer to untyped arguments unless you specifically intend it.
hiiamboris
12:27collect was just the first function! that my eyes picked from ? function! output. And I've patched some bits of reactivity system not so long ago from the same issue. I imagine we'll need some sort of static code analyzer to go over the whole Red side of the Red code and find the possible places where an unwanted execution can occur. Not a 100% bugproof solution but it'll be a start. Plus future big enough code bases will benefit from it.
04:56When right-clicking on an area in Windows XP (and probably in later Windows OSes, but I haven't checked), there is an option to switch to “Right to left Reading order”. Is it currently possible to switch on this “Right to left Reading order” from Red (analogous to setting HTML's dir attribute)? And if not, would it be theoritically possible for Red to have this capability, or does the Windows API not allow access to this “Right to left Reading order”, programmatically?
GiuseppeChillemi
19:43I am experimenting with objects, words and paths. I have an object whose content is a group of words which contain values and a blocks whose content, reduced, refers to the other elements of the object. Then I have a function which should reduce the provided object element until no block to reduce exists anymore.
I am experimenting an infinite loop but I can't understand the reason.
04:25@WiseGenius Red doesn't support right to left reading order right now; I believe a long time ago someone asked about this feature with regard to the Arabic language, and the answer was that it might be eventually implemented as a part of localization support and platform-specific OS metrics.
04:26@gltewalt I think this belongs to /help room.
19:58What lacks on RED to have this [great tool](https://www.softinnov.org/rebol/scheduler.shtml) ported ?
greggirwin
00:00@GiuseppeChillemi it shouldn't be hard to port, once we have full I/O. Red will support it for sure.
00:00I use it a lot in R2, and extended it as well.
GiuseppeChillemi
08:39@greggirwin Have you extended it ? Wow, what have you added ?
08:40@greggirwin It will need full I/O for.. timings ?
greggirwin
20:11It used system port for timing, yes. I added things like on date! at time! rules, the ability to add extra data to tasks, and support for listing upcoming events.
I was advised to use [sleep (ms)](https://github.com/red/red/blob/master/runtime/platform/win32.reds#L270), but it throws an "undefined symbol" error. It seems I'm getting close to being able to use AutoHotkey.dll with red, but not quite. I can retrieve variables from red via stdout thanks to the new 'print' command in View, or from the print command in the stable version if not using view. I can pass these to AutoHotkey via a library "stdout2var.ahk". I want to be able to execute AHK commands from red, and pass variables to red. I believe it to be possible.
There are many teasers in the documentation. There is reference to using libRed.dll with VB and VBA, and mention of an Excel demo of that, but neither the demo nor any real-world examples of VBA/red interaction are to be found. The reason I mention this is that AHK can create COM objects for which the VBA/AHK correspondence is very close, making it relatively easy to use COM from AHK. Easy from red? I have no clue.
All help always appreciated. Regards, burque505
9214
07:43@burque505 answered in [/help](https://gitter.im/red/help) room (where all questions belongs).
alex65536
17:05Hello, I am new to Red language. Can you explain what does is operator do and how to use it? Red by Example seems to lack documentation about this
17:14@alex65536 welcome! is is a part of reactive programming framework. Here are [documentation](https://doc.red-lang.org/en/reactivity.html) and original [blog post](https://www.red-lang.org/2016/06/061-reactive-programming.html) announcement.
No way to use 64-bit integers at this point, although there's a preliminary implementation of bigint! datatype.
16:45Reminder to all code contributors to red/red repo: please properly prefix your commit messages according to the convention we use since the beginning: * FEAT: new feature. * FIX: ticket or bug fix. If it's a ticket, then the form is: FIX: issue # () * TESTS: new or modified test(s), or testing framework related. * DOCS: related to the part of the documentation that is in red/docs.
16:47Those prefixes are used to extract changelogs, make stats and more easily search through history, so please use them.
hiiamboris
16:57I didn't know ;) What, every commit message? Or just PR titles?
dockimbel
17:04@hiiamboris Just look through the history of my and @qtxie's commits. ;-) Yes, every commit message.
hiiamboris
17:14So if I made a typo in some string or something, how should I spell the commit message? "FIX: for a fix of issue #number iteration Nth"? :)
17:17Okay I'll have to squash all the commits into one from now on then. Still, often I'm adding some post-fixes, after I read the comments of Gregg or others. Or after I see tests failing.
dockimbel
17:20@hiiamboris If the history of individual commits is useful to you or others for the sake of understanding the changes, then don't squash it.
17:22@hiiamboris > So if I made a typo in some string or something, how should I spell the commit message? "FIX: for a fix of issue #number iteration Nth"? :)
17:23Only use the last 8 characters of a commit hash when referring to it in a commit log, no need to overload it with the full hash.
loziniak
21:58http://helpin.red/Faces.html Is there a reason that default image size is 100x100 and base is 80x80? It just stroke me :-)
endo64
06:05@dockimbel should be first 8 character of commit hash, no?
greggirwin
06:30@loziniak, every style has its own default size. Is there a reason you think base and image should be the same?
dockimbel
08:45@loziniak @greggirwin No particular reason for those different sizes. Though, for nice alignments, it could be good to have them use the same default size.
08:46@endo64 I'm not sure, IIRC it was the last 8, but maybe Github's editor autorecognition feature works with both?
10:05Not sure about GitHub, but Git lets you choose commit by at least four first characters, but not by any amount of last chars.
greggirwin
18:37@dockimbel, do we want to consider it for things like tab-panel then as well? I'm all for consistency where it makes sense. Many styles won't fit this criteria, but at least a few can.
dockimbel
13:17@greggirwin Tab-panels are meant to be containers for other faces, unlike base and image, so panels need to have a bigger default size.
greggirwin
16:23Agreed. The irony is that it's smaller right now.
youngaiden
11:34Hi guys, just a quick question: does 'view' work on 64bit (L)ubuntu 18+ ? I've followed the instructions on 'https://www.red-lang.org/p/download.html' and enabled i386 etc but can't even get 'view [text "Hello World!"]' to work. I get *** Script Error: view has no value *** Where: catch *** Stack:
9214
11:37@youngaiden it was stated multiple times that GTK backend is a work in progress. Follow instructions [here](https://github.com/red/red/wiki/[NOTES]-Gtk-Bindings-Development) and ask developers in [this](https://gitter.im/red/GTK) room if you have any questions.
11:38@rebolek also ships [unofficial builds](http://values.red/builds/), including GTK one, so you might want to check them out first.
youngaiden
11:39thanks, Vladimir, I *do* appreciate your 'heads-up'
rebolek
20:34@youngaiden I'm moving my server to different VPS and once it's done, my build script should be upgraded to provide @rcqls dev builds too.
10:58is there going to be a webkit component or some package similar to electron?
rebolek
11:00@aolko someone might try do something like that, but definitely not official one. Red uses native OS UI, so there's no need for Web-based one.
aolko
11:02people might conseider html+css > VID due to it's flexibility
rebolek
11:07Then those people can add webkit backend to Red. For me, having to use three different languages with three different syntaxes to get GUI is not a sign of flexibility.
13:30It's just a matter of writing required styles.
13:33It's of course gonna take some time, but this GUI didn't just popup into existence by itself too. There's for example no native <stacked-round-avatar> tag in HTML :smile:
14:22Cheating? Draw is regular part of Red, was always part of Rebol's GUI as well. It is just a bit different subsystem. No cheating there, other than any such widget / style, will not be tied to the native UI and hence will not reflect eventual global OS UI changes, no?
aolko
14:23i mean, people don't draw new elements every time with html+css, they use css to modify existing ones
17:10The way I see it, you have HTML + CSS + JS + JS toolkit (JQuery, React, Riot, etc.), so I'd say at least 4 languages, but possibly more, to make a modern website.
greggirwin
18:46@aolko, Red is not browser based. You can't really compare them. A question to ask is not "Can Red do everything the web stack does, while being hundreds of times smaller, with tens of thousands of times less resources?" Ask instead, does it need to? That is, don't ask if Red can do something that may not add much value, and call that a limitation.
rebolek
19:15@greggirwin well, Red certainly needs some technologies that browsers have and some of them are in queue. I think that better question is what we *don't* need.
tmpbci
00:39And probably as @Respectech points out adding all these langages capabilities will defeat the purpose of simplcity ?
00:42and following the brython idea it's probably the browser to add red not the other way around :) https://github.com/brython-dev/brython
Respectech
00:43I think if Red could run in the browser and output to something like a JS Canvas, that would solve most of the issues of complexity with present web technologies.
12:55@dockimbel @greggirwin I'm not experienced in Red/View, so I ask these questions about default sizes more as a mean of getting additional information, than pointing out any errors. From first glance at the system, I'd rather expect default size of base and image as 80x80, and panel or tab-panel as 100x100.
13:02@rebolek is there any chance of you publishing the code of your implementation of @aolko's GUI? Or could you point me to other good examples / tutorials about creating custom styles to achieve this kind of non-native visual GUIs?
rebolek
13:06@loziniak Here's the GUI https://github.com/rebolek/gritter/blob/master/mockup.red , remove line 123 with avatar picture and here's simple [guide](http://red.qyz.cz/writing-style.html)
loziniak
13:08@rebolek fantastic! That's more than I could ask :-) BTW have you just written this guide in 4 minutes? ;-)
13:27@rcqls I've just copied @aolko 's example, but it would be nice to use it for Gritter.
rcqls
13:34I did not guess that it can look very similar to html style… BTW I understand now why you need fill-pen bitmap on linux...
Respectech
17:52@rcqls So all the stuff above @rebolek 's dashed line separator in the code is like CSS and the rest is like HTML, but they both share the same language and format, unlike CSS + HTML.
08:26(but, fair enough, it goes so far to allow making browser-based webapps, not win32 webapps)
rebolek
13:09/only can be used to limit words /with can be used to add words what would be best name for a refinement to remove/ignore some words? /ignore doesn't sound that great
17:02As you may already noticed, the VSCode plugin for Red was updated recently. Now it's much more powerful than previous version. It's implemented as a [language server](https://langserver.org/), which means we can give the same features to any editor supports this protocol with minimal effort. So here is an example for using Red LSP in Sublime Text 3: https://github.com/bitbegin/redlangserver/wiki/demo-for-sublime-text
03:21@qtxie where does the lsp server live, as saas over the net or as a windows service running on the machine?
rebolek
06:27@9214 I have function object-diff that compares two objects, word by word. object-diff/onlyimplies I want to compare only some words, object-diff/omit or object-diff/without implies that I want to ignore some words, but what does object-diff/some imply?
9214
06:29@rebolek personally I'd pick /some and /skip instead of /only and /omit.
07:39@moliad It's running on the machine. We can also run it over the net once we have TCP support.
moliad
14:34@qtxie ok thx its an interesting idea. especially coming from MS.
greggirwin
01:03@rebolek /with is better than /only in this case, but /without doesn't sound as nice for the inverse. I'd go with /ignore, as both /only and /skip have different meanings in their standard uses today.
rebolek
04:28@greggirwin Is it? To me /with sounds like I would add additional words, not limit them.
04:29Currently I use /only - compare these words only, /omit - omit these words from comparison.
gltewalt
04:54/with leaped to my mind because of trim/with - until it read your function name again
rcqls
05:31Is somebody could explain the output of img/argb ?
In the source code, img/argb is supposed to be a copy-memory? So I thought red-image! was represented in memory in argb format. Is it normal that output of img/argb is in the reverse order (like would be img/bgra)?
05:54img/argb is in red-binary! format and the following output does not say that red-image! is in ARGB format but in BGRA format.
06:26@rebolek I don’t think so since the source code I am reading is in runtime/datatypes/image.reds and the previous outputs are like in the official documentation…. The goal of platform dependent file (image-gdk.reds is to convert red-image! to pixbuf (supposed to be in rgba format).
07:13@rcqls If the format of the native image is not argb, you have to convert it.
rcqls
07:16@qtxie But do you confirm that red-image! is in bgra format? And if I understand you, red expects native image to be in argb format to work in the import phase.
qtxie
09:03@rcqls It's [ARGB (word-order)](https://en.wikipedia.org/wiki/RGBA_color_space#ARGB_(word-order)). Maybe RGBA (byte-order) is a better choice. There are some issues about it and we need to review them.
Oldes
09:22I think it should be possible to use also other refinements, like: /rgba, /bgra, /hsv, /saturation, /hue, etc.. with appropriate binary (or vector?) result for all pixels (as it would be more efficient than computing these values per pixel traversing the image manually). But I understand that it is not a priority.
rcqls
10:25Thanks @qtxie for the link! Indeed for newbie people /bgra is more understandable or maybe /binary….
11:41@qtxie Now I understand what is the difference between little endian and big-endian…. I need to read more to understand what it is the convenience of such concept. So for both three OS, it is BGRA (byte-order).
15:53@rebolek /with is for when you want to specify an override for "all words".
moliad
03:41@rcqls the advantage of little endianness, in general, is that type-casting to larger bit depths is a simple copy, there is no shift required. its basically faster since you can just do additions between different bit depths with no extra bit twiddling by the CPU. we often think only of integer additions, but its also used for memory address arithmetic (which happens for many struct, program counter and other memory offsets). because this requires less transistors to implement in practice, most modern CPU use little endianness.
little endianness:
A
BB
CCCC
you can add A to CCCC directly.
big-endianness
>>>A
>>BB
CCCC
here to add A to C you need to shift A by 3 bytes
03:44there are probably other reasons, but this I understand is the main reason... its even a bigger deal for 64 bits, since there are even more shifts to do.
rcqls
05:16@moliad Thanks for the explanation! For image manipulation, I am not sure there is convenience. Also, I am not sure that the code I did now for solving a color issue on image (for red/GTK) is working in big-endianness. I thought this concept is transparent except when using shift operators.
giesse
06:47@moliad hmm, that does not make much sense to me. The only reason to shift A is if it was loaded into a register as A000 rather than 000A, and I don't see why that would ever be the case.
as the name implies, there is really no difference between little-endian and big-endian systems, it's just the designer's preference. it boils down to the reasoning that since bit 0 is the least significant bit, then byte 0 should also be the least significant byte; on the other side, the reasoning is that when writing down the words, you would write 00112233 for eg, therefore if you are dumping memory byte by byte, you would most naturally expect to see 00112233 rather than 33221100.
BeardPower
12:02We should use middle-endian as a compromise ;-)
rebolek
12:20I vote for no-endian. What is byte-order good for? We need byte-disorder!
ldci
12:26@Oldes RedCV includes all space color conversion such as /bgra or /rbga
gltewalt
16:50There was a source comment that read, “Avoid big endian!”, that I found much too funny.
13:34Hello. Had a question about Red as a whole. Putting its "alpha-ness" aside, does it have enough features to build most - if not all - use cases?
9214
13:37@RayMPerry Hi, can you be a bit more specific?
13:38Aside from full I/O support, modules and documentation we have almost everything needed for 1.0 release.
RayMPerry
13:39Yeah, that's what I was looking to hear. I like Red and I'm not averse to the small ecosystem. Hell, if I was better at programming, I'd contribute.
13:43@RayMPerry you might want to run your own research, if you want specifics. [This](https://www.reddit.com/r/redlang/comments/az9yvk/limitations_of_red/) and [this](https://www.reddit.com/r/redlang/comments/aebxct/contrast_red_with_racket/) subreddits should give more-or-less full picture.
> What's missing on the I/O support front?
port! datatype implementation (we have a preliminary one cooked up for C3 development) and actual port schemes. Check [roadmap](https://trello.com/c/Iz0cl1e8/61-070-full-i-o-support) for the details.
20:12I can attest to the fact that it has become rather stable. I have not had a single hard crash /segfault for months. we are in the process building some rather large-ish prototypes and its perfectly predictable.
20:13my current work involves a 6000 line project doing advanced binding, dynamic code loading, and parsing source files. it all works ok.
20:14there are a few little rough edges, but no unrepeatable issues where it just bombs out. even the gui seems pretty stable (at least on windows it is, don't know about other platforms).
endo64
20:15@moliad Long running tasks or your scripts/project starts, runs and ends?
moliad
20:16(When I say "we", I'm talking about an independent company, not Red foundation with deep knowledge).
20:19no long running tasks yet (no port! system) but we have a real desktop app which is probably about 10000 lines (or more?) and it has never crashed. any problems are expected, reproducible real bugs in the code (and a few alpha ish limitations in the run-time and a few missing functions like join ;-). all problems have had stable work-arounds implemented, often just by adding a new mezzanine or changing an approach.
endo64
20:24That's quite a thing. Good to hear that it is stable enough to run that big scripts.
moliad
20:25the garbage collector has helped a lot with bigger apps... its MUCH less memory hungry now.
GiuseppeChillemi
04:27About little endianiss and big endianess, guess who called it wrong in the wrong way for 30 years... we are two and one is a big Amiga figure we should all thank.
20:37the idea behind construct is to be able to directly create an object from a block like the above, IMHO. my use case is converting from map! to object!, which I guess should be handled directly by to, but in any case I think construct should not be "smart".
map-to-object: function [map [map!]] [
body: body-of map
words: clear []
values: clear []
foreach [word value] body [
append words word
append/only values :value
]
obj: make object! append copy words none
set bind words obj values
obj
]
endo64
21:05I see. non-smart construct could be useful but would be incompatible with R2 & R3. About map to object, maps can have non-word keys:
>> map-to-object #(a: 1 "x" 2)
*** Script Error: invalid argument: "x"
21:06So handling simply by to could be problematic.
I'd expect construct to always do the dumbest thing and yieldmake object! [a: b:] in this case.
10:07So * both construct and object convert word! values to lit-word! for no good reason. * both construct and object treat set-word! values as keys even if they are at even indices or are a part of expression. * construct for some reasons adds extra none for "missing" keys, just like object in Rebol does.
rebolek
10:42@9214 one could argue that construct [a: quote b:] should result in make object! [a: 'quote b: unset!] instead of none.
11:02So in REBOL you *have* to use construct with body-of instead. Makes sense.
giesse
19:19@9214 in the case of make object!, the semantics are really simple:
* the block is scanned, non-recursively, for any set-word! * the list of words found is used to create a context * the block is bound to the context (this is always recursive) * the block is simply evaluated with do
Therefore, what you see above is by design. There is a good argument to make for a way to create an object with different methods; for example in Topaz object! has nothing to do with context! and follows different semantics, so you can pick whichever works for your use case.
construct though is meant to allow to build objects programmatically without any evaluation or trickery, and I think it makes no sense if it doesn't allow you to round-trip with body-of. But, I can imagine counter arguments, though I can't imagine real uses cases for the counter arguments. :)
19:22the lit-word! thing with mold etc. stems from the fact that REBOL didn't use to have a literal format for object! (as well as many other types), therefore the only way to save and then load back an object was to do things like the above, so that do on the result would yield back the original object. This is of course bad for a number of reason, therefore #[object! ...] and mold/all were born.
19:22I believe that construct was originally added to process the REBOL header without evaluation.
9214
19:22@giesse I know about make object! semantics, but IMO it's a bit too greedy when it comes to set-word! collection (see e.g. object [a: quote b:]).
19:23> I believe that construct was originally added to process the REBOL header without evaluation.
Yet in above examples it sort-of evaluates and even nicely adds extra nones.
giesse
19:25It's not really evaluating, but, IMHO it's trying to be too smart and I'd rather it be stupid. The adding of none could be argued for, see my map-to-object above where I'm adding none manually, I could skip it by using construct instead (I didn't know or didn't remember that it did that).
19:25on make object! what I mean is that the scan is simple, it does not know about quote or the meaning of any other function or native within the block.
19:26in fact, unless you turn quote into a keyword, it *cannot* know.
9214
19:31> It's not really evaluating, but, IMHO it's trying to be too smart and I'd rather it be stupid.
Agreed. construct IMO should take even / odd indices into account during set-word! collection. And I'm still not sure about extra nones...
> in fact, unless you turn quote into a keyword, it *cannot* know.
Good point!
hiiamboris
21:12So, to summarize, construct currently does not support two value types: set-word! and lit-word!. Right?
giesse
01:54I would say that the problem with lit-word! is on the side of body-of. There is also an issue with mold but that's tricky and eventually /all will solve it.
>> body-of context [a: 'b]
== [a: 'b]
>> construct [a: b]
== make object! [
a: 'b
]
>> construct [a: 'b]
== make object! [
a: 'b
]
>> select construct [a: b] 'a
== b
>> select construct [a: 'b] 'a
== 'b
01:55I don't see an argument for wanting to evaluate the result of body-of, so I would expect [a: b] as the first result above.
loziniak
12:56Hi! Is it possible to embed fonts int Red application to use them in face options?
This new version is based on a compiler that generates parse rules from topaz-parse rules. This means that you can use topaz-parse without having it as a dependency (just use the compiler output directly).
It needs a lot of work but it's able to compile itself which is the important starting point.
Please let me know if you are interested in contributing documentation or examples.
11:40@giesse Thanks for sharing red-topaz-parse, generating parse rules is a cool idea!
Oldes
12:56@giesse you are referencing parse-compiler.red [here](https://github.com/giesse/red-topaz-parse/blob/master/topaz-parse.red#L30) but it is not in repository.
12:57It's named parse-compiler-template.red instead.
rcqls
13:04@Oldes Since I had the same thought at first, It is regenerated in make.red from a downloaded parse-compiler.red (if it does not exist) and parse-compiler-template.red.
17:52@Oldes indeed, the parse compiler is needed to build the parse compiler. For bootstrapping, a known working version is downloaded automatically for you. From that point onward, you can build your own from the sources.
giesse
21:04btw @Oldes I'm thinking of changing the name of the files so this is less confusing. There will be a %parse-compiler.red in there, it will load something like %complied-rules.red, and if not found it will provide a more reasonable error message (like, "Please do %make.red first" or something).
How much interest is there in a Red to Red compiler? The purpose would be to experiment with new features, types, etc. in a way that doesn't affect Red itself, and doesn't require Red/System programming and so on. Additionally, it could work as an optimizer or even static analyzer for Red code.
9214
21:07@giesse I'm pretty sure that @BeardPower would be interested in that, and many others too (me included).
giesse
21:30Another project that has been on my mind for a very long time is this: a Javascript-like dialect that generates Javascript, but with parse, load, mold, ports, etc.
Ie. as close to JS as possible to be appealing to a wider audience, but with all the goodies from REBOL so that it can be useful to us too. Eventually it could evolve into a set of dialects to generate web apps. It could be just a Red dialect, or even a stand-alone language. Just curious about thoughts and interest.
@giesse How different than Topaz? Red to Red compiler is definitely an interesting idea.
9214
22:23@giesse everything web-related is worth a shot IMO, since JS / WASM compilation targets are the typical demands, but all of this is a low priority for the core team ATM, and an uncharted territory on and of itself. Your experience with Topaz will come handy for sure.
greggirwin
23:18I'm all for doing more at the mezz level, but I'm concerned about experimentation and divergence on a broader scale, given our limited resources. @giesse has probably given more time and thought to this than almost anyone else (and certainly anyone can work on what they want, which is great). The first question I have is: what are the big missing or new pieces that this fills the need for?
Language design, change, and experimentation have to be done, or there's no progress. Unfortunately, we also have to make and sell products and/or services. Balancing these aspects is tricky.
giesse
05:16@endo64 it would be JS-like rather than REBOL-like. So not like Topaz.
05:20@greggirwin this is precisely why I think doing this as a Red to Red compiler would be less problematic than forking Red or forcing you guys to come up with easier ways to extend the language. It only adds to what is already in Red and avoids taking away any time from the core team. In turn, you guys can more easily evaluate proposals if they can be tested for a while.
greggirwin
18:36Go for it. We are most productive and creative when working on things we want to work on.
mikeparr
12:26There is a new download of my 'ride' Red editor, at: http://www.mikeparr.info/redlang.html The main change is in the pretty-printer handling of code with incorrect nesting of [...]. The new approach is to warn you, and to not delete lines from your file.
endo64
20:25I have converted @9214 's brief explanation of how Red works to wiki, take a look: https://github.com/red/red/wiki/%5BNOTES%5D-How-Red-Works---A-brief-explanation
9214
20:41@endo64 thanks! I extended it at the bottom with another comment of mine.
giesse
21:15I have a weird issue with mold (at least I think that's where it's coming from) where in a couple spots a newline is replaced by a random character. This suggests that it may be gc-related memory corruption. I don't have an easy way to reproduce it yet. It may even be Linux only. Anybody else noticed anything like that? (master branch)
23:55@endo64 thanks to you for conversion (converted from??? Where???)
toomasv
04:41@GiuseppeChillemi Source is right below the title :)
GiuseppeChillemi
06:45@toomasv yes but it was 2:00 AM and fine print are not recognized during that time of the day.
07:53@9214 @endo64 Added 2 lines from the original articles where Vladimir described value slots strucuture.
08:14Just a questions about the mechanisms described in the article: During the load phase, functions seems to have a 2 states: the loaded one, and state after being interpreted for the first time. In the second phase they become "insensitive" to changes in spec and body. So a double level seem to exists: the visual one and the inner one and they may become out of sync. Is my interpretation right ?
Ok it is not the "visual one" , it is the "expected one". You think there is still Z after f: but it isn't there anymore. This becouse now Z has been used as argument and while you expect it being the spec argument of F it isn't there, only its content is there which has lost any reference to Z.
toomasv
08:59@GiuseppeChillemi What you describe is not different from:
a: 1
b: a
b
;== 1
a: 2
b
;== 1 ; <-- do you expect this to be 2?
> During the load phase, functions seems to have a 2 states: the loaded one, and state after being interpreted for the first time.
During load phase there is no function, but word! and 2 block!s, after interpretation there is function!, which is represented in similar way as after load. Body can still be changed, and it is not "insensitive" to changes.
Body can still be changed, and it is not "insensitive" to changes.
You change it differently. It isnt' composed anymore from a block derived from workings like reduction. It doesn't exist anymore in that way, its is a block that could be accessed only using WORD-OF.
I have investigated on the sources of this misunderstanding inside myself and I think this problem has been caused:
1) Never read in documentation about the 3 pieces -> 1 function change after evaluation.
2) Lack of visual rapresentation of the change that help bringing to a different working domain. When youprobe get 'f you get an output which too identical to standard words and blocks. So you automatically think its working like blocks.
Also, as far I remember spec-of F could not be changed later. It is another difference I have been introduced [time ago](https://gitter.im/red/help?at=5c74eba3c1cab53d6f3e0daf) but with no evidence on documentation.
>>> ;== 1 ; <-- do you expect this to be 2? >>> Yess
But [b: a] is not a value assignment it is a reference assigment. You are pointing to the value slot that contains "1" taken from a. Then you loose connection with aand b keeps it with the value slot. When you assign 2 to a you are creating a new value slot and a connection to it. (Please, correct me if I am wrong)
10:58I was hoping you could give me some feedback.
11:00I don't have any contact information for Nenad Rakovic.
pekr
11:02I am not organizer, just a regular community members. There are some ppl in here, who work closely or are part of the Red team, they will surely listen and consider your ideas ....
31880994zz
11:03Okay, thank you. I understand. Thank you very much for your support.
11:04I don't always go online to chat rooms abroad. It's a problem to climb over the wall. So I hope you can give me some feedback on today's suggestions. Thank you very much!
9214
11:06@31880994zz all blockchain-related questions or suggestions belong to a [dedicated channel](https://t.me/redofficial). This is a development channel and you should keep it on topic.
11:08@9214 Our sincere hope is that Red Programme is getting better and better.
meijeru
11:35@9214 and collaborators: congratulations on the Wiki entry "How Red works". It should be required reading for everyone! It could reduce the number of questions and misunderstandings.
rcqls
11:40@9214 Thanks for this great pedagogical explanation. And thanks @endo64 for posting it in the wiki!
BeardPower
11:45@9214 @giesse Absolutely. I looked into http://www.ssw.uni-linz.ac.at/Coco/ as well. It could benefit in our goal to get Red self-hosted.
greggirwin
20:16@31880994zz I cleaned out the cross-posted blockchain messages here, so they're only in the red/blockchain room now. Just FYI.
20:27Linked How Red Works from https://github.com/red/red/wiki/Reference. Thanks guys!
https://www.red-lang.org/2015/12/ > For now, the model we aim at is the Actor model. It is a good fit for Red and would provide a clean way to handle concurrent and parallel tasks across multiple cores and processors. Though, a few years has passed since that plan was made, so we will need to revisit it when the work on 0.9.0 will start, and define what is the best option for Red then. One thing is sure, we do not want multithreading nor callback hell in Red. ;-
https://static.red-lang.org/Red-SFD2011-45mn.pdf • Concurrency support – Task parallelism: using "actor" abstraction – Data parallelism: using parallel collections
I understand that there are many more urgent things on the todo list and it is unlikely that any work on that has started. Still, just to make sure: no work has been done on that (by the community, perhaps)? No discussion, no design docs? Has the plans changed? (I see no mention of parallel collections in 2015 post and that is a good thing IMHO).
31880994zz
19:07@greggirwin @raster-bar You guys are the best.
19:10@greggirwin @raster-bar The core of the block chain is that applications can land and create value for humanity.
raster-bar
19:12I don't want to steal someone's else credit. You have copied my nickname by accident.
greggirwin
19:12@raster-bar the plans have not changed. This part has to be led by the core team, but there is plenty of design research done, and options for async I/O models being evaluated with this in mind.
31880994zz
19:13@raster-bar You mean we have something in common, right?
19:15@greggirwin I'm sure your team and your company will get better and better.
19:16@greggirwin I believe you must belong to the elite.
19:17@greggirwin I may have some problems with my English.Not really.
raster-bar
19:17@greggirwin Is it correct to assume that there's no place for contribution from outsiders until the initial release of the actor model support (given that it will require a massive update of the language internals)?
9214
19:17@raster-bar contribution are always welcome. Do you have anything specific in mind?
19:18What time is it over there, friends? @greggirwin @9214 @raster-bar
raster-bar
19:19Not at my current level of competence - I'm still studying red. I just don't want to waste my time at something that is guaranteed to be rejected.
9214
19:20@31880994zz I believe I already asked you to keep this room on topic. Please give us some breathing space to discuss the important matters.
19:21@raster-bar at this stage in development it's more important to explore what is possible and gather real-world requirements, so the work that you have in mind might not be as "irrelevant" as you might think.
19:26Just stick around and try to have some fun, the rest will come :wink:
greggirwin
19:34@raster-bar, what @9214 said. If you're just starting with Red, get a feel for the language, look at open tickets for things to cut your teeth on, and have a good time.
raster-bar
19:35I assume we don't want data races. Given that we have no hardcore type system (like Pony or Rust, for example) we can either copy everything passed between actors (Erlang style) or introduce read-only values to alleviate the inevitable performance problems. Read-only values will lead to the language overhaul and thus can not be implemented by outsiders (and that is assuming that the team will find read-only values acceptable). If I'm wrong please let me know:)
19:41@greggirwin How Red will handle concurrency/networking is the defining factor for how much time I should invest into it. I understand that things may change and nobody owes me anything but planning is important, isn't it?:)
9214
20:04@raster-bar I think it's safe to assume that actor model is the the most likely candidate, because it ties nicely with reactivity and ownership model that Red already has, plus leverages object! as a datatype, alluding to Rebol's message-passaging and object-orientation.
21:44@raster-bar, @9214 is on track. Rebol was originally designed as a messaging language, and Red is all about the data. That makes the copying approach a more natural fit.
02:27@greggirwin thank you. I hope this is a preliminary vision and we won't end up with Erlang-style "copy but use workarounds for large data" and opt for more generic approach. Time will tell.
greggirwin
02:28The problem with the real world is that there are no perfect solutions. It's all compromises.
02:29We'll try to avoid the most painful and annoying compromises though. :^)
10:59@xqlab Why is there so little official news lately?
rebolek
10:59@xqlab AFAIK relocation is not finished yet (bureaucracy), which is the reason of lack of news.
31880994zz
11:00@rebolek When will all the relocations be completed?
xqlab
11:00I do not know. I just hope that there are just temporary delays because of the relocation.
rebolek
11:02Well the team is moving from one continent to other, so it takes some time. But sooner or later, this process will be finished and work will continue as usual.
31880994zz
11:02@rebolek Well, I hope so. I hope nothing else goes wrong.
rebolek
11:04Something can always go wrong. Meteorites can fall, or there can be zombie apocalypse, who knows :smirk:
13:08@BeardPower The French attach great importance to block chain technology. To build a block chain country, invest 500 million euros
9214
14:32@31880994zz please move your discussion to /blockchain room.
14:39@xqlab we'll post more news once there is something to announce on public, that goes without saying. Allow the team to take their time and do what needs to be done properly, and start contributing by yourself if absence of activity concerns you so much.
22:27Coming from red/bugs, there is discussion of possible multi-line comment syntax. We have runtime support (comment), which can be aliased to a short name, but there is no lex-time support, which we'd want for it to be safe and side-effect free. @9214 and @hiiamboris lean toward a macro solution, which has benefits. I'm generally not a fan of macro solutions, but this is one place where it may be a really good fit.
A related feature came up in the Rebol world many years ago. Heredoc strings: https://www.curecode.org/rebol3/ticket.rsp?id=1194
For my part, I'm much less concerned with performance than usefulness (as is almost always the case :^). By usefulness, in this context, I mean how comments/heredocs/here-strings can be used as data. Escaping is the other key issue that comes up with this feature. Interpolation can be related as well, which ties us to the format project and its syntax.
GiuseppeChillemi
23:30Why is not allowed to copy literals using COPY ? It seems so straightforward !
greggirwin
00:55What would be the purpose? They are already independent values.
00:59You also need to answer how things like same? behave. If you want real copies of scalar values, you have to consider the cost when it comes to comparisons and storage.
GiuseppeChillemi
06:40@greggirwin because you change the way you express the same action for different kinds of data. If you have a block of values and you wish to conditionally copy part of it to another,
06:41then you must change the way you express the copy action in RED
09:38@maximvl all questions will be answered in due time and in official announcement. Besides, there's some info about Red/Pro scattered around blog posts, Gitter and Reddit, enough to make an educated guess.
meijeru
13:01@GiuseppeChillemi One way would be to define copy on direct values as the identity. This would not be a big change.
13:12@meijeru what you mean with "to define COPY on direct values as the identity" ?
meijeru
13:20I mean extend the definition of the copy action so that it is also defined on direct values , but does not actually copy them. In other words, if type? x is not in [series! any-object! bitset! map!] , them copy x ==> x.
9214
13:39@meijeru this is a questionable extention, as it confuses two rather distinct actions - copying of underlying buffer and identity morphism.
meijeru
13:42Yes! The alternative is to program it yourself, testing each argument on whether it is an indirect value or not. Since that is done at high level, it will be less efficient.
13:43Or, somewhat better, define a built-in action! say xcopy with the above definition, but programmed in Red/System.
9214
13:53@meijeru I don't follow - what xcopy should do exactly? If we're talking about identity function, then id: func [x][x] is enough. If we're talking about copy on direct values - this simply doesn't make sense, because they don't have anything to copy. Like I said, making copy act like id for direct values mixes two operations, which I don't think is desirable.
meijeru
13:56Then we are back to programming it explicitly in Red, testing each value as to their type, which is what @GiuseppeChillemi found awkward...
GiuseppeChillemi
14:53"Copy" is an action verb that I instantly think it could be applied to values of a word, any type of values. I suppose other developers thought the same at their start of REDBOL career. It is a natural way of thinking because the word itself is general and not specific and using it on words content, you naturally assume "any word content".
meijeru
19:08But what would copy 5 mean? And given a: 5 what would copy a mean?
GiuseppeChillemi
22:15@meijeru I have a long reply but it is too late to write it in a proper way, I'll write you soon
greggirwin
02:16I will say with some certainty (which is rare for me), that copy isn't going to change. What may seem like an innocent and helpful change, because you can blindly use copy on anything without knowing what it is, has deep implications and the effects will ripple out.
I want Red to be easy to use, and accessible to a wide audience, but that's not the same as "anything goes" or "no learning required".
Red requires a different mindset and approach to learning than other languages. New Red users (who are not yet Reducers ;^) often use Red as they would other langs, and can easily complain that it doesn't offer much more than their old tools from a basic coding standpoint. If they move beyond using strings for everything, and over the initial hurdles, they may start to see that in Red datatypes are first class citizens. That's a *very* different way of thinking. We also have different types of functions (function, native, action, op) that may seem like a step back from a single underlying type (e.g. base object in Smalltalk). But there are reasons Red is designed and implemented (an important aspect) the way it is.
To become a Reducer, we need to understand that types, and their forms, are central to Red's power; and that they sometimes share characteristics, but are not all interchangeable.
Hiding details *can* be good, but it's not a silver bullet. It can also lead to problems. Designing a language is a balancing act, built around a set of core choices and a vision.
pekr
03:19I remember a wild discussion on the R3 'make' copying (or not). There were several related blog posts, ppl varrying on what should be the ideal aproach and Carl proposing various changes, while admitting, any such change can have deep implications .... http://www.rebol.net/r3blogs/0241.html
greggirwin
04:12Thanks @pekr, we must remember our history. :^) Too bad the link to Carl's copy semantics docbase entry doesn't work.
05:11@greggirwin the problem is caused from hidden players of REDBOL not being introduced early and clearly in the learning path.
greggirwin
06:32@GiuseppeChillemi remember that every user is different, and what you, as a single user, think might be a good change, could be perceived as equally bad by another user. When there is collective agreement about a design issue, we address it. Of course we also want to improve and broaden documentation to help users. That's the much more effective thing to do, because almost anyone can do it.
We are open to input, on the language, tooling, blockchain aspects, etc., but we also take into account how people explain and defend their positions, their understanding of all factors involved, and whether they have thought deeply about changes or features they request.
meijeru
07:55@neluno Worth saving the content of that link before it too disappears!
mikeparr
08:07I'm just tidying up a cross-reference program. It reads in a Red program and displays a list of every item used, and its line number(s). I'm not sure it handles absolutely every type of literal (but see the following example for binary handling). I like a cross-reference for spotting 'spell-check', and 'only used once' errors.
Red ["Cross-ref demo"]
x: "Mike"
a-pair: 99x100
print a-pair + 1
multi-line:
{A long multi-line
string
}
replace/all "ABCD" "A" "Z"
a-bin: #{
AAAABBBBCCCCDDDD
000011112222
}
if x = "Mike " [print "got it"]
print "Done"
File name please: cross-ref-demo.red
**********Cross Ref of cross-ref-demo.red ************
"A long multi-l... || [7]
"A" || [10]
"ABCD" || [10]
"Cross-ref demo" || [1]
"Done" || [17]
"got it" || [16]
"Mike " || [16]
"Mike" || [3]
"Z" || [10]
AAAABBBBCCCCDDD... || [12]
replace/all || [10]
1 || [5]
+ || [5]
= || [16]
a-bin || [11]
a-pair || [4 5]
if || [16]
multi-line || [6]
print || [5 16 17]
Red || [1]
x || [3 16]
99x100 || [4]
draegtun
12:47@meijeru The DocBase wiki is already copied here - https://github.com/revault/rebol-wiki/wiki
12:47Here's the exact link to "Copy Semantics" - https://github.com/revault/rebol-wiki/wiki/Copy-Semantics
GiuseppeChillemi
13:09@greggirwin Gregg, you are right. Every user come here from a different experience and face different problems. However I think I have found common error patterns in learning REDBOL and what is causing them. My english is not so good but I will try to create something capable of helping newcomers not fall into the same problems....
gltewalt
16:15@mikeparr Shouldn’t the output be in order? “Cross ref..” [1] x [3 16] etc...
16:19@GiuseppeChillemi I have heard it argued that introducing “hidden players” early will scare new users away, as the ease of use should draw them in at first.
I disagree when it comes to learning the language, but I see the point of tools and apps are created that may allow a certain amount of scripting with Red.
GiuseppeChillemi
16:28@gltewalt I have a couple of ideas about how to introduce those players so users could build a proper mental model while learning the language. We (I) could fail but we should try. Too many casualties in the path for the elinghtment
mikeparr
17:56@gltewalt re cross-ref - it is like a book index , yes. A couple of issues with the sorting of numbers. Thanks.
GaryMiller
19:03Yeah, I have to admit that even after knowing many programming languages and reading the book coding in Red feels like you need to understand internal implementation details to make your own code work. I have been able to re-write my AI app in it but I still feel I am fighting the language and not really taking advantage of many of it's features yet like reactive programming, DSLs. and RED/system yet. So far happy but far from enlightened.
giesse
19:28@GaryMiller unfortunately "many programming languages" usually is a hindrance, because people have a hard time seeing through the veil, or, perhaps I should say the surface of the deep lake.
I don't agree that you need to understand the details of the implementation; you do if you are dealing with interpreter bugs or other issues (eg. in the case of REBOL, it being closed source and all that meant that you sometimes needed to take advantage of every implementation detail you could).
You do need to understand the design and philosophy behind the implementation though, and understand why it's different. Unfortunately, this scares people away very quickly so since both REBOL and Red are companies and can't afford scaring away people it's never going to be the first thing you are told.
GiuseppeChillemi
20:21@giesse . >>You do need to understand the design and philosophy behind the implementation though, and understand why it's different
Gabriele, we need only a couple of players to be in the mind of people when learning and some addition to the available documentation. Users do not need to know about the 128 bytes pointers or the payload but needs no fully undestand why ":" is not "=". You CONNECT left and right, you don't make them EQUAL. Its very different !
greggirwin
20:26Thanks for finding the copy semantics links guys!
giesse
20:48@GiuseppeChillemi > Users do not need to know about the 128 bytes pointers
That's exactly what I said.
> why ":" is not "=". You CONNECT left and right, you don't make them EQUAL. Its very different !
I'm not really sure why you would word it that way. Except for purely functional languages, generally assignment *sets* the "thing" on the left to the "thing" on the right, "thing" usually being a variable and a value respectively.
I have criticized multiple times the use of the word "variable" in REBOL-like languages because it confuses people coming from other languages. But, I'm not really sure this is the issue you are talking about.
21:01@9214 I think they're talking about references to values.
GiuseppeChillemi
21:24@giesse > I have criticized multiple times the use of the word "variable" in REBOL-like languages because it confuses people coming from other languages.
You are right, using "variable" is misleading because it brings readers to a knowledge not belonging to REDBOL. They retrieve in their minds what they have learned elseway which is no use here. Think like a "variable" makes SELECT brain 'old-knowledge on new users when they encounter that word.
21:26@greggirwin > @9214 I think they're talking about references to values.
Yes, they need to know there is a reference, not how it is physically implemented. (Despite being very interesting and formative)
greggirwin
21:43I can't argue as a newcomer now, but I was once, and I used Rebol successfully, without knowing internal details, for a long time. Finding the right amount of detail, and most helpful explanations, is obviously a hard nut to crack, or it would have been done a long time ago.
21:57Even Brian Harvey, in Computer Science Logo Style has a hard time with it:
> The technical name for what I've been calling a "container" is a variable. Every variable has a name and a thing (or value). The name and the thing are both parts of the variable. We'll sometimes speak loosely of "the variable person," but you should realize that this is speaking loosely; what we should say is "the variable named person." Person itself is a word, which is different from a variable.
"Named Contextual Reference" just doesn't roll off the tongue. "Value Reference" isn't much better. "Reference" may be the best single word other than "Word", but I want to add a reference! type to Red, which makes that problematic. So we're back to "word".
9214
21:59@greggirwin I just stick to "symbolic value" - technically correct and handwavy at the same time.
GiuseppeChillemi
22:42Rereading this topic before closing my eyes https://gitter.im/red/help?at=5c4b40d61cb70a372a376965
04:54I don't think the problem can be solved by finding a term which will make it easier to understand what a word is. There must be a few people for which Red is a first language, but for the vast majority, people are coming in with previous programming experience and trying to find an analogous concept in whatever thing they are familiar with, and it's just going to fail because they don't have one. The way I've been thinking about explaining it is - "Red has a data type called a word which takes the place of variables, and also things like keywords and operators in other languages". That way at least, it might be surprising enough to cause the mind to let go a bit and open up more. To me word is perfect already because (as a language term) it's a sort of an abstract building block which can change it's meaning depending on context and composition. It fits so well with how red is actually used.
05:34Separate topic, I recently heard about this [wasmer](https://github.com/wasmerio/wasmer) project, which is for running wasm outside the browser (I want to think node.js, but compiled to a widely adopted, standardized byte-code assemblies). It seems to be aiming for cross-platform application binaries via [WASI](https://hacks.mozilla.org/2019/03/standardizing-wasi-a-webassembly-system-interface/). They also just launched a package manager for it: [wapm](https://wapm.io/). It seems like this could make wasm a much more attractive target for Red, so I hope this is useful if it wasn't already on the radar. I don't have any ducks in that race, but I just get the feeling this has a lot of growth potential. Also, I think they might need a nice cross-platform GUI framework :wink: This [podcast](https://changelog.com/podcast/341) is where I heard about it if anyone is interested.
giesse
06:40@GiuseppeChillemi > How would you suggest calling it ?
17:34I hadn't seen wasmer @dander, so thanks for that. Keep an eye on it for us if you would. At a glance, seems like it requires both Rust and emscripten, but the main question is whether it will gain traction and make wasm a more valuable target.
dander
18:04@greggirwin I think those are just the tools they are using to build the runtime. Eventually I would expect to see native installers for each major platform, that woudn't require building it. I'm guessing they chose those to be fairly low-level, and Rust [seems to have good wasm output support](https://github.com/appcypher/awesome-wasm-langs), though I don't know if that is a prerequisite for building the runtime. Just one other point of note, Syrus from the podcast mentioned that they have enough interest from investors that they were able to pick the investor that fit the best for them.
06:16@GiuseppeChillemi I just love your REDBOL term (I didn't say word!).
06:18REDBOL is easily searchable, as Nick Antonaccio pointed out a long time ago about REBOL. I do regret that RED is just a pain in the neck to search through the internet...
06:20I'm facing a problem with a shebang in Red, and even though I Google using "red language", I get absolutely irrelevant results... It's a pity, in my humble opinion, especially for newcomers.
GiuseppeChillemi
08:59@PierreChTux_twitter I have written about this time ago. I find few results or no results on Google even using multiple words. It is a great problem as people will either think you, as RED, do not exists, or that few resources are available. Ultimately, they will leave the search frustrated abandoning the willingness of knowing more about RED.
09:00To me is a first class problem, a really serious one.
09:02 @GiuseppeChillemi I totally agree with your point of view: first class problem.
The more time it takes to solve it, the worse it will become.
pekr
09:03Maybe we should close the loop and rename RED to the term close to redbol - RedBall, borrowing a boing ball from Amiga fame :-) Joking aside, Redball is some game ....
PierreChTux_twitter
09:03 We had this discussion with @ldci, and he told me that the name "Red" initially came from "Reduce", which is a major philosophical point, concerning this family of languages. However, renaming "Red" to "Reduce" would be... réducteur... as we say in French... Not very appropriate.>
rcqls
09:04@PierreChTux_twitter Have you tried "red lang » as a google search. I’ll do the same for Julia (julia lang).
PierreChTux_twitter
09:04@rcqls oh yes I do systematically. And even though, I end up with irrelevant stuff.
09:14@rcqls I confirm. @PierreChTux_twitter experience. I receive a subset of the existing resources and I have to reshape the query at least a couple of time.
rcqls
09:18It is weird but maybe google (or ecosia) adapts the answers to previous requests. For red lang, the full received page contains only links about red language...
PierreChTux_twitter
09:18@rcqls , you must be lucky! On my side, a couple of weeks ago, I've battled endlessly to figure out a stupid shebang problem, I arrived on pages like this one: https://stackoverflow.com/questions/14732651/vim-red-highlight
09:20Thanks for pointing out ecosia, I didn't know this search engine...
9214
09:27> I'm facing a problem with a shebang in Red, and even though I Google using "red language", I get absolutely irrelevant results...
It puzzles me how people go at great trouble with search engines, but ignore information in readme file and on issue tracker.
> Note: Running the Red toolchain binary from a $PATH currently requires a wrapping shell script (see relevant tickets: #543 and #1547).
09:27It's true that duckducking "red lang" leads to relevant results.
https://duckduckgo.com/?q=red+lang&ia=web
(apart from ads I get for some telephone thing called "red" where I live)
However, if you encounter a problem, you search for a trick, then when you ask your search engine, you end up with weird things.
09:29If, say, I want to have syntax in my favourite editor for Red lang: https://duckduckgo.com/?q=red+lang+vim+syntax+highlighting&ia=qa
Oops. I'll soon be lost.
But if I want the same for Rebol: https://duckduckgo.com/?q=rebol+vim+syntax+highlighting&ia=software Relevant answers, straight away.
9214
09:29Perhaps this discussion should move elsewhere. I don't see any point in doing search engine comparison in the main development chat.
PierreChTux_twitter
09:30@9214 okay, sure. Where should this discussion happen, then?
9214
09:31In [/chit-chat](https://gitter.im/red/chit-chat), for instance.
PierreChTux_twitter
09:32? Wth... Thanks for the advice: I would never have imagined that this was a suitable place...
9214
09:33Well, this room's description is pretty much on point: > A place for the Red community to talk about whatever they want, to keep other rooms clean.
PierreChTux_twitter
09:39@9214 Thanks for pointing to these links. Note that there are also incredible amounts of very relevant information concerning Rebol and Red which are located outside of github, e.g. in blogs, forums, etc. Those places are searchable by... search engines...
But I rest my case. I'll start a discussion about that in the chit-chat thing. Sorry for the noise.
9214
09:40> Those places are searchable by... search engines...
... or by [Github wiki](https://github.com/red/red/wiki/[LINKS]-Learning-resources) which we organized.
PierreChTux_twitter
09:47@9214 In my very humble opinion, this room's description: "Red Programming Language main discussion room (mostly for questions about Red sources, *Red language design*, community organisation,...)." also seems appropriate for such an important and basic design issue, the very fundamental point concerning the use of such a common name as "Red".
The issue concerning the searchability of resources over the Internet comes as a corollary. That thing was very successful with Rebol, and not so much with Red, as Nick pointed out several times.
GiuseppeChillemi
10:00@PierreChTux_twitter +1. Chit Chat is perceived as a generic text chat not related to RED, so it is very low priority and rarely read. I kindly ask @9214 the permission to continue this thread here. It is very important and relevant.
PierreChTux_twitter
10:02@GiuseppeChillemi ah.... Okay, I hadn't started chatting on chit-chat, just reading quickly what was happening there.
I totally agree with you that it is an important, relevant and fundamental issue. It may just frighten many newcomers.
9214
10:26Sorry, SEO is not an "important, relevant, fundamental first-class language design issue", it's a matter of time and resourcefulness. E.g., Go's success and adoption spared it from confusion with ancient board game, searching for Rust now gives you language resources, not only articles about videogame or oxidation of iron. Even Pony gives something other than MLP pictures.
If you have any sensible proposals on this "issue" (which do not hurt project's identity by changing it's name in the midst of development or by using questionable acronyms and compounds) - bring them on and collect in a dedicated wiki page, start a *constructive* discussion around it, prepare hard numbers and palpable facts which we can use with advantage to Red.
Alas, instead of dedicating your time and effort to this problem (which you both strongly consider being very serious and important), you decided to argue with me and to derail this room, which, I remind you, is a public-facing chat, where newcomers and outsiders come in to ask deep questions about language design and roadmap, and where all project announcements are made.
If it is truly an important issue, then discussing and solving it in real-time chat (esp. with crappy search engine that Gitter has) is counterproductive. So, either reconsider your approach, or, if you cannot do that, move to chit-chat. End of discussion.
hiiamboris
10:30I would add that anyone can contribute by starting a searchable catalog of Red-related sites and writing a simple web-crawler that will find the candidates to review and list there. Especially if he's having a hard time with google.
rebolek
10:39There much less searchable names than Red. Like C# or .net.
raster-bar
10:43"redlang" seems to work really well with google
GiuseppeChillemi
12:07@hiiamboris I have started programming.red with this problem and purpose in mind. Time permitting I have some ideas to evolve it I will work on the nexxt weeks. Also, we can conduct and arrange a test about this problem with search engines and find a solution @raster-bar Testing it. @9214 Vladimir have you investigated why so many people are not perceiving this chat as the place as you intend it to be and you must explain each time to move elsewhere ? Don't you read a continuous flow of wrong topics here ? It's people or there is something in the chat which is driving unintended behaviour ?
PierreChTux_twitter
13:39@raster-bar I agree. This is how I renamed the Red executable, so that I (and the rest of my systems) can still use red (a default shell script on GNU/Linux):
# pierre@latitude: ~ < 2019_04_26__12:46:56 >
which red
/bin/red
# pierre@latitude: ~ < 2019_04_26__12:47:04 >
man red | head
ED(1) User Commands ED(1)
NAME
ed - line-oriented text editor
SYNOPSIS
ed [options] [file]
DESCRIPTION
GNU ed is a line-oriented text editor. It is used to create, display,
# pierre@latitude: ~ < 2019_04_26__12:47:08 >
which redlang
/usr/bin/redlang
# pierre@latitude: ~ < 2019_04_26__12:47:12 >
redlang
--== Red 0.6.4 ==--
Type HELP for starting information.
>>
13:39(ugly look: sorry about this; I intended to quote my terminal within ` : I obviously missed something...)
13:43@Oldes yes, I'll try to modify it. Sorry for the mess...
greggirwin
18:46IMO this room is fine for chat about problems searching for Red resources. All suggestions are welcome, but the name of the language isn't likely to change for that reason.
18:54/chit-chat is appropriate for non-technical chat.
raster-bar
19:36Just to clarify: I didn't mean Red should be renamed, I meant Google searches for it just fine - just use redlang, so there's no point to rename it. Sorry for offtopic, that was my last comment about it.
16:19I am pulling them from remote urls, with a read request
16:19is there a way to make the read do that for me, and run it in red?
greggirwin
16:20Reading just gives you the data. Modify that once you get it. Don't modify read.
addos
16:21yeah, I mean, I guess, it would be nice to be able to have a read function that does that for me, since there is so much legacy rebol code out there already
PierreChTux_twitter
16:21@addos I ran into that problem before. I'd suggest to
replace whatyougot {[Rebol]} {[Red]}
or something similar.
addos
16:22@PierreChTux_twitter I will have to test that
greggirwin
16:22@addos since Red is a different language, the best way to do it is with a wrapper. We're highly compatible, but not 100%.
PierreChTux_twitter
16:22@addos I agree, it would be handy. Maybe it could just give us a warning, saying that we should rather forget about that old Rebol codebase, but still allowing it.
16:22@greggirwin Yes, there are cases when Rebol code is just not operating at all in Red.
addos
16:24I noticed that if I compile code that uses ask, the code doesn't compile
16:34@greggirwin Yes, well, praying never hurts. And porting code can be a pain in the neck, especially if the mental state of the original writer is unknown. Rebol code can be fantastic to read and modify; it can also be horribly complicated to domesticate. Even if you are the original author... Another way, after pray, would be to accomodate Red so that it is more compatible with some existing code bases. Maybe it would be easier that way?
greggirwin
16:37Compatibility is a slippery slope, and taken seriously. If you want to argue for a specific compatibility change, it needs to be just that, *specific*. But making Red the best language it can be is more important than compatibility. We need to look forward, not back.
PierreChTux_twitter
16:38Yes, you're very right. Rebol had (has) a few serious drawbacks...
16:44@addos as a person, he has nearly zero impact on the project. But his ideas and work will live with us through ages.
rgtk
21:28I stumlbed upon this project couple of months ago and now want to create a small utility GUI for Linux with Red. Unfortunately support for Linux GUI is missing. Does anybody know what is the status of it?
21:40@rgtk it's not finished, but has gotten quite far along. Also check out this wiki page: https://github.com/red/red/wiki/%5BNOTES%5D-Gtk-Bindings-Development
13:35I will be hosting a Rebol Developers Conference in Philadelphia this summer (July 6th-7th). I've a great location lined up just around the corner from the Independence Mall (across the street from Ben Franklin's Post Office) and some interesting talks lined up.
I'll have registration up shortly, for now I've a wee questionnaire to get an idea of what kind of interest there is. Note that this is not a Red-specific conference but I'd encourage anyone in the region with an interest in Red to step up and talk about things they're working on—just get in touch!
If you're in the northeastern US, Philly is very accessible (great rail/bus access) about 90mins from NYC and DC. If not, it's a culturally rich city that is very much worth a visit even without a Rebol conference as an excuse, and we'll be here for July 4th at the very location where July 4th became a thing. Our hosts will provide co-working space on July 5th for any conference participant arriving from out of town.
16:27The scope is the Rebol language family. There may be divergent threads, but the core Rebol principles are ones we all care about: fighting software complexity through language!
16:34There isn't at this stage any featured talk on Red though. There will not be any official Red representation either (at this time), however as a primarily regional play—if anyone from this part of the 'States would like to present a talk on Red or their Red projects, I would very much encourage them to get in touch.
RayMPerry
02:04Hello. How would one go about making a web server in Red?
17:03@raster-bar [here it is](https://gitlab.com/snippets/1855154). It's just a parser and viewer, not a player (yet :smile: ).
raster-bar
19:41Thank you very much! Too bad I don't have a shell right now where it looks just as good as on your screenshot, but it definitely works. I didn't expect a player, of course, given that we don't have a standard audio output.
19:44Ouch, I didn't realise it was not a screenshot
rebolek
04:58@raster-bar adding some view-based viewer shouldn't be that hard, but I prefer to work in console, it's much faster than GUI, which can always be added later.
raster-bar
13:57@rebolek what font do you use in your console?
rebolek
16:17@raster-bar [Iosevka](https://github.com/be5invis/iosevka), but this is not a screenshot, just copy pasted output.
BuilderGuy1
16:52Just read an article about a Garbage Collection Co-Processor that offloads the CPU for doing any Garbage Collection. Perhaps in the future Red will need to be flexible enough to have GC on the CPU or not. Here is the link to the article: https://spectrum.ieee.org/tech-talk/computing/hardware/this-little-device-relieves-a-cpu-from-its-garbage-collection-duties
moliad
17:54@endo64 yep, the mod will be written in Rebol 2as well as a handler for it, and it will just Offload the processing to redlib (the red.dll)
17:56so if it finds a .red file (or any other extension you want to configure) then it runs Red in a sort of fast-cgi mode. the exact details are not yet fixed, but it should at least allow us to use any normal Red script and generate a response.
18:17I already use Red over cheyenne by calling a command-line but its not as optimal.
greggirwin
18:20@BuilderGuy1 that sounds like it's not a near term issue, as it's hardware based.
18:39Hey, all you Reducers out there. We now have 700 people in this room. I don't like crowds, but this is great. Be sure to check out the other Red rooms, like /gui-branch and /sandbox, where fun things come up. And while it's not a popularity contest, when someone posts a gist or link to a repo with something cool, please consider either giving them some recognition of what you like, or star their work.
Open source is often its own reward, and our community is filled with wonderful people, though we are still working on the RED tokenomics rewards side (thank you for your patience), and we can reward people with crypto as well. Don't think something has to be big to be useful, or inspire others. @toomasv posted a really cool color picker in red/gui-branch just recently, and it's only about 50 lines, but *so cool!*
Believe me, we know everyone's time is valuable and in short supply. That's one of the reasons Red exists, to save you time and effort. Even in its Alpha state, Red can do a lot of useful things. Tinker, have fun, write tools for yourself, open your mind and it can help you use other tools more effectively as well. Red is a great tool for thinking, which is what we do if our job is to develop software.
Happy Reducing!
18:41Oh yeah, @planetsizecpu keeps posting updates to his cave game in red/gui-branch as well, if you need a small break to watch criminals, guards, spiders, and elevators.
endo64
21:17700 people in this room! That's something! And here some other statistics:
For the main repo:
361 forks
3798 stars
235 watchers
9997 commits (who's going to make 10'000th commit?)
43 contributors
-o-
281 GitHub projects with language set to Red
512 gists
Most starred Red project is redCV (https://github.com/ldci/redCV)
And the second one is https://github.com/rebolek/red-tools
07:29Yes, we are a few! good news @greggirwin @endo64
PierreChTux_twitter
09:34> Hey, all you Reducers out there. We now have 700 people in this room. I don't like crowds, but this is great. Be sure to check out the other Red rooms, like /gui-branch and /sandbox, where fun things come up. And while it's not a popularity contest, when someone posts a gist or link to a repo with something cool, please consider either giving them some recognition of what you like, or star their work. > > Open source is often its own reward, and our community is filled with wonderful people, though we are still working on the RED tokenomics rewards side (thank you for your patience), and we can reward people with crypto as well. Don't think something has to be big to be useful, or inspire others. @toomasv posted a really cool color picker in red/gui-branch just recently, and it's only about 50 lines, but *so cool!* > > Believe me, we know everyone's time is valuable and in short supply. That's one of the reasons Red exists, to save you time and effort. Even in its Alpha state, Red can do a lot of useful things. Tinker, have fun, write tools for yourself, open your mind and it can help you use other tools more effectively as well. Red is a great tool for thinking, which is what we do if our job is to develop software. > > Happy Reducing!
Great message, heartwarming, thanks!
GiuseppeChillemi
17:42It will be difficult when we will be 70.000, but until now everything is fine.
raster-bar
20:32The Feature-Wars page on the Red Wiki lists a few language features but has no content for any of them. Does it mean that the team was pestered often enough to remember this particular requests but no discussion is actually documented? If it matters I'm interested in immutability only
20:46@raster-bar as far as I know, the most up-to-date public roadmap is https://trello.com/b/FlQ6pzdB/red-tasks-overview, and doesn't include immutability, but maybe you'd be interested in checking out this experiment by @numberjay https://gist.github.com/numberjay/3df8f13044145c6dde1918ea2cdfe3b8
raster-bar
21:13Thank you very much! It's an excellent food for thought
21:28I have only recently discovered Red. It looks very interesting but also very different.
I come from a Pharo (Smalltalk) and Python background. I have played around with Red most of today. It can be kind of challenging to put together sufficient information to learn and do things. Not quite a cohesive whole at the moment. I understood this going in.
However, I have managed to discover enough to put together a program that does something that is very necessary to my application in order to test Red and its current usability for me.
I need to read text csv files (lots of them) and parse them into proper values and perform calculations on the values.
Red [Title: "Reads a gain csv file. Parses and does calculations."]
stime: now/precise
print stime
;http://ratedata.gaincapital.com/2018/12%20December/EUR_USD_Week1.zip
csvlines: read/lines %/home/jimmie/data/EUR_USD_Week1.txt
remove csvlines 1
count: 0
pips: 0.0
psum: 0.0
psumsum: 0.0
pasize: length? csvlines ; 337588 ; length? csvlines
slice_size: 2500
parray: make vector! [float! 64 337588]
foreach line csvlines [
count: count + 1
price: to float! (last (split line ","))
parray/:count: ((price * price) * (count / pasize))
pips: pips + price
psum: sum parray
psumsum: psumsum + psum
]
etime: now/precise
print etime
print [count pips psum psumsum (difference etime stime)]
The above code may be quite naive as I am just learning. But so far it is still running and on course to take 6+ hours to do what Python/Numpy is doing in 50 seconds.
I am eager to know am I doing something egregiously wrong? Or is Red just not there yet?
Even pure Python using its array.array for the array is only 18x slower than Numpy.
Any help greatly appreciated.
21:38Due to my inexperience with Gitter and accidentally hitting enter, I have not expressed what I want to express.
I truly admire the goals of Red. I truly love the idea of a full stack language. I really look forward to these goals being met.
While the Red code looked very foreign to me. Once I started learning small parts of it. I found certain aspects quite beautiful. Once you learn some of the vocabulary the foreignness lessens, and beauty appears, simplicity appears.
Can my code above be improved and optimized? Can it at least come closer to the ballpark of Python/Numpy?
I don't require that it beat Numpy? Only that the cost be acceptable. Their are benefits to beautiful code from a full stack language. And I would think that it could possibly be improved by dropping down to Red/System? for some parts?
Just some naive thinking out loud.
Anyway, thanks for the opportunity to explore this very interesting language.
greggirwin
22:07@jlhouchin_gitlab welcome! I'll try to look at your code more in a bit and profile, but @rebolek has some CSV tools in the works, which will inform the design for our CSV codec when we add it.
The first thing I notice is that you're using split (which is fine) and then taking the last item from the line. Since you only need the last value, you could save a lot of parsing and allocation overhead by doing this:
Because you don't care about any of the other fields.
What I don't know is why on earth it would take 6 hours to do this. Need to pull the data from your sample URL and look into it.
22:08@raster-bar that wiki page is kind of a placeholder, to remind us we need to discuss Red's design choices, what we might do, how, and what is not planned.
22:10@jlhouchin_gitlab ask all the questions you want. We have a red/help room, and a /welcome room for newcomers. Some things will indeed be foreign from a Smalltalk background, so thanks for judging Red on its own merits, knowing that it's different.
hiiamboris
22:17@jlhouchin_gitlab the obvious bottleneck is sum parray which does a lot of unnecessary work and on Red level. Why don't you sum it one item at a time? You're changing only the last item anyway.
Announcing the (pre-)release of the [Red-ODBC binding](https://github.com/gurzgri/odbc-red). Connect to your databases with Red, finally.
PierreChTux_twitter
22:27@jlhouchin_gitlab Welcome in our marvelous world! I think you've got the idea; when you say "The above code may be quite naive", it struck me. Very often, I end up typing thoughts, totally naively, in my interpreter, and the code just runs... It sometimes feels like a kind of miracle, a bit like telepathy: Rebol and Red are quite surprising, from this point of view.
22:28@jlhouchin_gitlab I do the kind of coding that you showed quite often: parsing text files, getting stuff out of a URL, putting it into a database, in .csv files... I never noticed anything significantly slow, and I've noticed better performances than using python for similar tasks.
GiuseppeChillemi
22:30@gurzgri What a surprise ! I have used munge3.r form dobeash. I will try your code soon on Microsoft SQLServer.
22:31@gurzgri Great news! ODBC, it's been a while since I've heard of it...
GiuseppeChillemi
22:33Just a note: on https://github.com/gurzgri/odbc-red#inserting-statements-retrieving-results , I see "ÄÖÜßäöü" in the last line of the first data block. Is it correct ?
greggirwin
22:45Nice to see you @gurzgri. Thanks for posting!
23:38@jlhouchin_gitlab, @hiiamboris nailed it as usual. I didn't notice that you're summing your entire array on every line. It would be much faster in Red/System, but I agree that the best thing to do is not sum it every time. Please try the code below, and make sure the results are correct. Let us know how it performs. Does pretty well here (no spoilers ;^).
Red [Title: "Reads a gain csv file. Parses and does calculations."]
;-------------------------------------------------------------------------------
every: func [size value body /local interval] [
if zero? value // size [
interval: value / size
do bind/copy body 'interval
]
]
;comment {
; repeat i 50 [every 5 i [print [i interval]]]
;}
;-------------------------------------------------------------------------------
stime: now/precise
print stime
;write/binary %EUR_USD_Week1.zip read/binary http://ratedata.gaincapital.com/2018/12%20December/EUR_USD_Week1.zip
;halt
;http://ratedata.gaincapital.com/2018/12%20December/EUR_USD_Week1.zip
csvlines: read/lines %"EUR_USD_Week1.csv" ;%/home/jimmie/data/EUR_USD_Week1.txt
;csvlines: read/lines %"EUR_USD_Week1 small.csv" ;%/home/jimmie/data/EUR_USD_Week1.txt
remove csvlines 1
;print ["Read/lines time:" difference stime now/precise]
count: 0
pips: 0.0
psum: 0.0
psumsum: 0.0
pasize: length? csvlines ; 337588 ; length? csvlines
slice_size: 2500
parray: make vector! compose [float! 64 (pasize)]
foreach line csvlines [
count: count + 1
;every 10'000 count [print ['. 10'000 * interval]]
;if count > 1000 [break]
;price: to float! (last (split line ","))
price: to float! find/last/tail line ","
parray/:count: last-val: ((price * price) * (count / pasize))
pips: pips + price
;psum: sum parray
psum: psum + last-val
psumsum: psumsum + psum
]
etime: now/precise
print etime
print [count pips psum psumsum (difference etime stime)]
23:39You'll need to adjust the data file name for your system.
23:56And The Great Red Optimizer might kick in to see how cleverly it can be approached. Because your lines are all exactly the same length, with fixed width fields, there are a couple ways that could be attacked, rather than treating it as CSV.
greggirwin
00:11I stand corrected. After line 47207 there are some lines where a value is rounded, and those lines are shorter.
00:15If not for that, this should work to extract the numbers you want:
data: read %"EUR_USD_Week1.csv" ;%/home/jimmie/data/EUR_USD_Week1.txt
;data: read %"EUR_USD_Week1 small.csv" ;%/home/jimmie/data/EUR_USD_Week1.txt
header-size: 56 + 2 ; +2 for CRLF
ignore-size: 60
number-size: 8 ; LF only after numbers
data: at data header-size
nums: parse data [
collect [
some [
ignore-size skip mark: copy num 8 skip keep (to float! num) lf
]
]
]
00:26Ah, you may also want to check your results, because / currently does an integer divide if both args are ints, which is the case with count and pasize.
00:26Coercing pasize to a float before your loop will fix that.
00:30Here's how you can approach something like this, where you want the last part of a line, but lines vary in length. If your last field is a fixed length, it's easy. Just scan to each lf, mark that position, then copy the data that came before it.
header-size: 56 + 2 ; +2 for CRLF
ignore-size: 60
number-size: 8 ; LF only after numbers
data: at data header-size
nums: parse data [
collect [
some [
to lf mark: keep (to float! copy/part mark negate number-size) lf
]
]
]
00:36Just a quick explanation of some why I am doing what I am doing.
I understand it might not make sense. It is simply an example stress test of things that I commonly do in my app. The summing of the entire array is just a stress test of summing a large number of items over and over. In the actual app I will doing summing, moving average over slices (strides) of the array which array which will change every iteration.
So while some of it might not seem practical or how to really solve the problem. It is simply a stress test that can easily be reproduced in a variety of languages and examine how they handle array access, summing of arrays, reading lots of reasonable large files, etc. I will be reading thousands of files running a variety of tests over and over.
In this particular file which I did not clean up. For these purposes I only wanted one value. In the real files I will be reading and use all the values which normally would consist of datetime, open, high, low, close values. It is a trading app as is knowable from the url I provided. Backtesting can be very resource intensive.
Hopefully this will help explain what might not make sense. It doesn't make my code any less naive. :)
greggirwin
00:39In that case, you probably *do* want to look at how to incorporate red/system for those aspects. It will be much more performant.
00:40As an example, look at %mandelbrot.red vs %mandelbrot-fast.red in https://github.com/red/code/tree/master/Scripts/. It's doing image manipulation, but will give you the idea.
00:52A key difference, which may not be obvious, is that Red has no fixed size array type. Even vectors.
jlhouchin_gitlab
00:57I will have to hopefully spend some time on studying what you all have written on Sunday. It is time to spend some time with the family.
Part of my struggle so far has been working through learning Red. The documentation and learning resources have been a struggle to discover what I am looking for. If there is a simple path from beginner to a reasonable basic understanding I haven't found it yet.
My primary goal of the experiment today was to see if I could learn enough about Red the language to see if I enjoy working with it. And then also to see if there was hope that it would perform adequately. Inadequate performance is why I am not using Pharo at the moment.
I read the goals and the desired features of Red and I like them a lot. If I can demonstrate to my self that it can perform adequately then I could spend the time in the journey to learn Red sufficiently. Even if it would be app v2.0. I would be viewing Red as the language I want to use for the long term should I enjoy the language and it performs adequately. It doesn't have to be the performance winner. Just that the performance not completely rule it out. Part of the purpose of my test. I can look at the time, and the results and somewhat say what I did came to the same results as in the other implementations. Therefore it did the same thing ultimately. Whether it did it right, or idiomatically or to the best of the language is why I posted. I don't want to rule out a language with the potential of Red due to poorly performing naive, non-idiomatic code from a cursory examination of the documentation. I want to give Red the opportunity to put its best foot forward. I value the values Red has. I don't have a problem with small communities and non-mainstream languages.
Back Sunday morning, work permitting.
Thanks to all who are helping enlighten me on my Red journey.
greggirwin
02:10The Rebol Core Guide is a good reference, until we do our own. Reference docs are at https://doc.red-lang.org/ if you haven't found those already. Our best resource is our community, but you seem to understand that Red is quite different, and time and experience are good teachers. We can help you over hurdles early on though. Things like https://github.com/red/red/wiki/%5BDOC%5D-Why-you-have-to-copy-series-values and other wiki pages can give you deeper insight as well.
02:11Red/System comes very close to C performance, so you should never hit a limit you can't solve with that. The trick is to leverage Red as much as possible, for productivity.
For your question about performance in this specific script, as pointed out by others, you are relying on sum, which is a high-level function only meant for convenience, not performance. In Python, when you are using array.array or Numpy, you are calling highly optimized C code libraries. In order to get similar performances out of Red, no need to install a C toolchain, you can just add a Red/System short function in your Red script for doing a fast summation (and then compile your script). Though, such function manipulating Red datatypes at low-level, requires the use of the internal datatypes API, which is currently not documented (though easily discoverable in the codebase, people can give you pointers for that if you need it).
12:38> But so far it is still running and on course to take 6+ hours to do what Python/Numpy is doing in 50 seconds.
There's definitely something else going on there, it looks like the execution froze or went into an infinite loop. Could you please provide us with the sample CSV file so we can try to reproduce it locally?
GiuseppeChillemi
13:25@dockimbel It is encoded as comment [here](https://gitter.im/red/red?at=5cd60b6e5d48a24fd0a86223)
This is the link: http://ratedata.gaincapital.com/2018/12%20December/EUR_USD_Week1.zip
15:44@jlhouchin_gitlab @greggirwin With replacing split with find/last/tail and rewriting the sum function in Red/System, the scripts completes in 274 seconds here. Giving that you get 50 seconds using Numpy, it's an excellent result for Red, as it boils down to C vs R/S speed difference, which will disappear once we get an optimizing backend.
Here's the sum version as a R/S routine (specialized for vector of floats):
sum-floats: routine [vec [vector!] return: [float!] /local slot tail sum][
slot: as float-ptr! vector/rs-head vec
tail: as float-ptr! vector/rs-tail vec
sum: 0.0
while [slot < tail][
sum: sum + slot/value
slot: slot + 1
]
sum
]
15:47As a rule of thumb, if you are looking for pure speed, avoid using any mezz function (support functions written in Red itself), stick to natives and use routines for performance-critical parts.
greggirwin
17:36@jlhouchin_gitlab perhaps @BeardPower will chime in, as he's working in similar areas. We have some experimental aggregator ideas floating around, though no sliding window or moving average ones yet.
Where Red will let you think differently about how you solve this is when you get more experienced (give it some time) and look at writing a dialect to express your domain needs more clearly. With Red's macro capabilities (and this is one of the rare times you'll see me promote them ;^), you may be able to preprocess your data, simply load it, and make a lot of things easier. Since you have historical data, you could batch process those and save them in Red format, so all other tools don't have to *re*-process textual CSV data.
rebolek
17:48@greggirwin > no sliding window or moving average ones yet.
That's not entirely true, how do you think 7-day and 30-day smoothing in [Stats](https://rebolek.com/stats/) is done?
greggirwin
19:07I stand happily corrected! Are you re-summing all the time or keeping totals and counts, so just need to recalc based on new input? The latter is what I meant for aggregators.
rebolek
06:33Currently I'm re-summing, the number of datapoints is low enough, so I haven't done any optimizations (calculating chart data is instant compared to downloading info).
BeardPower
11:14@jlhouchin_gitlab Even with zero-otimizations compiled Red has good performance (10-30x slower than optimized C). If you need bare-to-the-metal performance implementing your code with Red/System would be the solution. It's a lot like C and you are mainly doing pointer-arithmetic. Speed is about 3-4x slower than optimized C but once we have an optimizing compiler it should be on par with optimized C. If you want to do system programming, Red/System is a must because it exposes the hardware (CPU registers, memory managment etc.). Series data is ideal for Red/System and pointer arithmetic as you can easily loop through your data (if the data points are of the same size) and create data aggregator functions as function pointers.
Red [File: %adapter.red]
#include %red-github/environment/console/CLI/input.red
arg-str: ask ""
print to binary! arg-str
and
Red [File: %run.red]
adapter: switch/default system/platform [Windows [%adapter.exe]] [%./adapter]
out: copy ""
call/wait/input/output adapter "test" out
print "out" probe out
Running in Linux red-25mar19 run.red:
out
"#{74657374}^/"
and in wine: wine console-view.exe run.red:
out
"#{7400650073007400}^/"
but in Windows it fails red-01may19-8d712e4b.exe run.red:
out
{^/*** Runtime Error 1: access violation^/*** at: 0041F70Dh^/}
It seems that in Windows it does not pass *"test"* string to stdin of adapter.exe, because running adapter.exe straight from command line also results in crash, same as running ./adapter in Linux without providing stdin input. Does anybody has any experience with passing things to stdin in Windows? How would you suggest to fix the script? Has anyone used call/input under Windows with success?
hiiamboris
12:49@loziniak Please narrow down the stdin problem and open an issue for it. It crashes for me on W7 too, on a null pointer as usual.
jlhouchin_gitlab
02:38 Thanks for the education and suggestions. I will continue to investigate. My little program finished in 7h:39m. And it did not give the correct results. The summing did not sum. I don't know what it spent the time doing.
I added the above sum-floats routine and added a print [count pips psum psumsum] to the loop.
The psum prints 0.0 every iteration. It does however finish in about 6 minutes.
03:13I have seen the documentation mentioned. I have not found any documentation on Red/System.
The other potential issue I may have at this point is that I require an http client to access a REST api. It seems I have read that IO is not until 0.7.0. I am not certain if I understand correctly if that means that there is no http client functionality.
Thanks for your patience in my inquiries into Red.
03:50@jlhouchin_gitlab did you see my note about integer divides? Also, there's no need to run tests on the entire dataset, if you're doing basic profiling and validation of results.
You can easily make REST calls with Red today, you just don't have low level access to the TCP port to do more detailed things, like writing a web server.
Yes it is profiling. But it is a comparison of how well a language or implementation does array access and calculations like sum. In this particular test the data isn't changing significantly and we can do the wonderful ideas that are being suggested. However, how does the language do when I do not have that knowledge. When I have a set of data which has come over the wire of which I only know it is a series of floats. Then there are other calculations over the array for exponential weighted moving averages, and such. I am not a math guy and do not know how such would be done with accumulators and such. So this is simply a test. No it isn't necessarily real world. But it isn't far off of something that is actually done over and over. This particular data set is only for 5 days and for 1 instrument. What if I am backtesting over 700 of these sets and over a few dozen instruments. This is why the test.
Now that said. I am going back to my code and in my other implementations going to rewrite some of the summing to use an accumulator. I will need to subtract what gets popped off, and add what is pushed. But it should be amazingly fast. And the bigger the set the bigger the win.
Regarding the integer divide. Yes, I saw what you said. I went and manually changed everything to floats. It crashes on me every time. I find debugging in Red to be much, much more challenging than I am used to.
Thanks for your pushing me. I will continue my learning. Red is different and will take a little time.
13:09I really did not ever intend on going down this trail of performance testing. Then I started backtesting my Python app. I timed each backtest. I calculated the lapsed time and the projected time remaining. I began to run the test and it said I would be testing 1500 combinations. (Not the real number) As the test ran I watched the projected time. And it was like 48 hours. And I thought. I have to find a better way. Thus began my journey.
rebolek
13:10Red is 1) different, but also 2) alpha. So it's not optimized for most task. That's why some things require more work to be efficient.
Also, debugging in Red may seem challenging, but it can be very easy, once you know how. probe is your friend.
@dockimbel @greggirwin I can't access the wonderful article about debugging, probably wrong link? https://github.com/red/red/wiki/%5BDOC%5D-Guru-Meditations#debugging
13:37@dockimbel https://github.com/red/red/wiki/Debugging opens Create new page for me.
dockimbel
13:38@jlhouchin_gitlab > I find debugging in Red to be much, much more challenging than I am used to.
It's still quite rough, as we haven't yet incorporated any user-friendly debugging feature. Though, that should come quickly as I have started prototyping on debugging hooks in the interpreter earlier this year.
14:51I've fixed the link in https://github.com/red/red/wiki/%5BDOC%5D-Guru-Meditations#debugging to https://github.com/red/red/wiki/%5BDOC%5D-Debugging now it works.
19:19@jlhouchin_gitlab if you can create small sample scripts that crash, those are very helpful. The kind of work you're doing is something we'd like Red to do well, and we'll try to ease your pain as a guinea pig in this area. :^)
19:30An interesting idea, and teaser, is that we could write a dialect for numeric processing. Already discussed in the past, and Red can add more types, like matrix! to optimize things in that area. What hasn't been discussed, AFAIK, is that we can write routines, which may be very simple, as @dockimbel's example to sum floats shows and *then* use reflection to dispatch to R/S routines based on, e.g., vector type.
Vectors don't support reflection yet, but we can parse the molded value for experimentation purposes.
jlhouchin_gitlab
19:39So far while I have experienced some pain in this process. I am quite pleased that I could do what I have done in as little time as I have spent trying to get it to work.
I see a lot of beauty in Red and in Red the language. And with its ability to create DSL dialects. I don't see why this can't be a beautiful solution to most any problem.
My ultimate choice in language does not have to be the ultimate performance champion. What I am looking for is something that works with my brain. I have seen so many languages and I go, my brain does not work that way. I want something that I can learn to think in, think well. Something that allows me to do as much as I can within the one language. I am not a professional programmer. So to a certain extent I may be a part of your target. :)
Fortunately I have the liberty to choose what I want to implement and with what to implement it in. I only have so much time and I don't want to become expert in low level, machine level programming. I don't necessarily mind pointers and such, but am not a hardware guy. But I don't mind learning lower levels of the language.
I am very used to mailing lists. And I know this makes me sound old, but also Usenet Newsgroups. :) I do thing this Gitter is nice for potential immediacy of interaction. But it seems to not have the searchable lasting effects I like in a mailing list. Just one old guys opinion.
Regardless of that opinion. I would like to know which forum you would have preferred me to post my original question. And is this where you would prefer it to continue?
19:42I don't mind being a guinea pig. :) I believe I have seen enough in Red to persist in learning. I do believe the performance issues will be addressed by proper algorithms, rewriting certain functionality in Red/System, and Red in general as it matures.
How exactly do you want these scripts? Just post the content here? A different forum? What is the desired flow for such interactions?
greggirwin
19:48> What I am looking for is something that works with my brain.
Me too. I feel very luck that I found Rebol so many years ago.
We have a lot of old guys here, myself included.
Gitter search is terrible. What year is it again?
Red/Help may be best, so people have context, and prep their minds for writing bits to test and offer up.
Small bits of code are fine in chat, gists (snippets on github) are good for small to medium scripts. Once you get to many files, a github repo is best; but gists should do all you need for now.
For flow, post a question or problem, include or link to source examples for context (in your case, datasets help too), and let the fun begin. You may get widely varied suggestions, but will happily explain advanced code when needed.
raster-bar
19:56@greggirwin what other existing math library is most likely to resemble the future Red math library?
greggirwin
20:01There isn't one. :^) Clearly NumPy/SciPy are on a lot of radars, but we have some Julia and array programming fans in the community as well. And Frink. In designing the format dialect, I looked at a lot of Wolfram stuff, along with older systems. Our goal is not to aim for compatibility, but to learn about the strengths and goals of different systems, and design something that fits well in Red, while also looking ahead, so we can go beyond what's been done before.
20:21I think where Red can really shine in some of these areas. Is that for those of us who need nicely performing apps, but don't need the entire tool chain of Numpy or Julia, etc. The ability to accomplish what you want to accomplish and deploy something nice, small, fast and efficient. I sincerely love the idea of not having to deploy the whole of the Numpy stack simply for nicely performing arrays. But the whole of the Python community accepts it as normal and acceptable. :(
I remember a few years ago while exploring Clojure discussions about memory use. And most people who loved Clojure had no problem with it consuming 100s of MBs or even GBs of memory. Simply running the REPL for a hello world consumed over 300+MBs on my x86-64 Ubuntu laptop. Ugh! Kind of made me ill.
20:31I believe I found what I did that cause the crash. I mistakenly changed the count to a float. count was being used to access the parray/:count. I would imagine that is expecting an integer.
greggirwin
20:34Yes, but it shouldn't crash. If we don't have a ticket for that, we should open one.
20:37Red does aim for small and light. We hate bloat, but realize we may have to add a --bloat switch, like PowerBASIC did, to be taken seriously. :^) Another benefit people see, when doing processing work, is that they can also use Red for simple GUIs to go with it. We have a couple people working on a charting lib design now.
jlhouchin_gitlab
21:52Right or wrong I submitted an issued. Assigning value to vector/:float: causes crash #3876
Let me know if there is a way you would have preferred.
dander
22:07@jlhouchin_gitlab for search, if you don't mind fiddling around a bit, @rebolek's [gitter tools](https://github.com/rebolek/gritter/blob/master/gitter-tools.red) can download the complete gitter chat history, and you can use any decent local file search tool on it. The major limitation of it currently is that you need to look up usernames against ids, but I've found it to be pretty handy from time to time
jlhouchin_gitlab
22:24@greggirwin I have not yet explored the GUI tools yet. But is in in the plans. I do have things that I would love a GUI for. Currently my project is purely server side. However, there could be some nice wins for a dialect which understands the domain. Some GUI code to explore the tools and arguments for backtesting. Possibly some visualization of results. There is a lot of stuff that is hands on, in person before deployment to a server occurs. Some of that might be nice with a simple GUI. Unfortunately I don't think that is ready yet for Linux.
greggirwin
02:32@jlhouchin_gitlab I commented on your ticket. Thanks for submitting it.
@rcqls is doing amazing work on the GTK branch, so it's darn close to ready (no pressure @rcqls ;^). Certainly testable. Check out the Red/GTK room for more info. It's a huge effort, and I'm sure he'll appreciate more testers.
rcqls
04:08@greggirwin Working hard on camera for linux/GTK… hope to be not so far after long reading and experiments….
dander
05:32@rcqls great! keep pushing! By the way, I think the reason I failed to get your vagrant setup to work is that I have Hyper-V installed, and I think there is a conflict between it and VBox
rcqls
05:36@dander Thanks for your support. BTW, I have a new vagrantfile with xserver inside the box without the needs of using ssh It was required to test my camera…. I’ll share that ASAP… when I have a first prototype for camera.
dockimbel
10:22@jlhouchin_gitlab > So far while I have experienced some pain in this process.
If you can find time to document those pains, even in short form, that would help us improve that.
jlhouchin_gitlab
10:50@dockimbel Will do > @jlhouchin_gitlab > > So far while I have experienced some pain in this process. > > If you can find time to document those pains, even in short form, that would help us improve that.
jlhouchin_gitlab
12:34@greggirwin > Ah, you may also want to check your results, because / currently does an integer divide if both args are ints, which is the case with count and pasize.
You are correct that caused a problem. The results were incorrect. Sums were 0.0. I went back and made the change to coerce to float!. Now the results are correct.
The default 'sum vector! took over 7 hours. The new 'sum-floats vector! took 6 minutes. Huge improvement but still far behind. But as has been said, Red's compiler isn't optimizing as it will in the future. I am okay with that. For most of what I will do changing the algorithm will be the big win.
An oddity with the 'sum-floats vector! was its memory use. I like to watch the task manager to view memory and cpu of my apps. While running the app with the normal 'sum it was a constant ~50MB. While running the app with the 'sum-floats it grew continually until reaching 200MBs when the program completed and exited.
Just wanted to report back. Time to continue reading the docs. :)
dockimbel
13:07@jlhouchin_gitlab The sum-floats function consumes no heap memory at all, so cannot be the culprit there.
14:08@jlhouchin_gitlab > An oddity with the 'sum-floats vector! was its memory use. I like to watch the task manager to view memory and cpu of my apps. While running the app with the normal 'sum it was a constant ~50MB. While running the app with the 'sum-floats it grew continually until reaching 200MBs when the program completed and exited.
Memory here using sum-floats version is stable at ~50MB.
jlhouchin_gitlab
14:39I don't know how you are testing the routine, but in the small app I wrote, it grows. It could easily be my code has something that causes the memory growth. I have a lot to learn about Red. I have learned while reading the docs and also from the lesson above about integer / float division. That Red has some gotchas that might not exist in other languages. As I learn I will ask about those. But that might be the red/help gitter.
What I just learned is that both sum and sum-floats grow in my code. I didn't notice it in the sum version because it takes 450 minutes to do what the sum-floats does in 6. I just didn't watch long enough.
So it is not the sum-floats.
Red [Title: "Reads a gain csv file. Parses and does calculations."]
sum-floats: routine [vec [vector!] return: [float!] /local slot tail sum][
slot: as float-ptr! vector/rs-head vec
tail: as float-ptr! vector/rs-tail vec
sum: 0.0
while [slot < tail][
sum: sum + slot/value
slot: slot + 1
]
sum
]
stime: now/precise
print stime
;http://ratedata.gaincapital.com/2018/12%20December/EUR_USD_Week1.zip
csvlines: read/lines %/home/jimmie/data/EUR_USD_Week1.txt
remove csvlines 1
count: 0
pips: 0.0
psum: 0.0
psumsum: 0.0
pasize: to float! (length? csvlines)
slice_size: 2500
parray: make vector! [float! 64 337588]
pasize: to float! pasize
foreach line csvlines [
count: count + 1
price: to float! (last (split line #","))
parray/:count: ((price * price) * (count / (to float! pasize)))
pips: pips + price
psum: sum parray ;or sum-floats parray
psumsum: psumsum + psum
;print [count pips psum psumsum]
]
etime: now/precise
print etime
print [count pips psum psumsum (difference etime stime)]
14:54Feel free to let me know of any of my inquiries would be better in another forum. I am still feeling my way around which forum is appropriate for what.
I just learned in the gitter settings to the right that I can switch from chat mode to keyboard mode. This helped my gitter experience. :)
I mentioned earlier that I need to access a REST API. The api prefers persistent connections and restricts new connections to 2 per second. Does Red support persistent connections? Also they have a streaming api? Does Red support http streaming?
Thanks.
[From the OANDA docs](http://developer.oanda.com/rest-live-v20/pricing-ep/)
15:21@jlhouchin_gitlab As mentioned above by Gregg and me, split is a performance and memory killer and should be replaced in your code by find/last/tail:
price: to float! find/last/tail line ","
That said, the GC should still compensate (at the expense of the running time) for the huge number of extra allocations done by split in your code...
I think you can move this discussion to red/help room as it is more appropriate.
16:57The way people tend to use Red for "big" data extraction and crunching inspired me (just a quick idea for now) an improvement to Parse to better address such needs that are increasingly more common. Please let me know your comments.
:custom-loader in this case would be a R/S routine that takes a head and tail pointers as argument, and returns a Red datatype.
*Advantages*:
* directly call fast low-level type-specific tokenizers in R/S (integer, float and tuple already [implemented](https://github.com/red/red/blob/master/runtime/tokenizer.reds)) * zero memory overhead (no extra memory allocation involved) * ability to pipe the output to other rules (set, keep)
17:07Though, the final load implementation in Red might be fast enough to not require direct calls to low-level per-type tokenizers.
17:09Another advantage of having a keyword for that, is avoiding the use of temporary words to point to beginning and end of each token, which would then be passed to a load/part in a paren expression.
17:14I am not sure if this would be a good idea in this proposed form, maybe there is a better interface for such feature with a broader usage scope.
hiiamboris
17:46If I'm correct, another advantage is that it will be able to load numeric formats not supported by Red. This keyword however is useless in (and isn't meant for) the block parsing mode.
9214
17:46@dockimbel I think fine-grained tokenizer API is a good idea, and its broader usage might be custom loaders for different data formats (both textual and binary), but there a a few disadvantages: * the onus of using R/S for custom loaders, which might be hard for people without appropriate skillset (i.e. major part of the community); * it makes little sense without stream-based parsing and port!s; if you can put whole string! buffer into memory prior to parsing, you might as well load it; * your proposal addresses only scalar values, but ignores composite data, which I might want to tokenize as a single entity; e.g., in my practice, I often work with 2 or 3 channel signals (separate rows/columns, or even data in separate files, one per channel), which I might want to put into a single pair! or block!; * it's not clear how to tokenize missing or corrupted values (either treat them as nulls or ignore); in other words, there need to be some kind of a fall-back mechanism if tokenizer fails; * (corollary to the above) I don't think that Parse can handle tabular parsing effectively, esp. column-wise, but it's a common need in data crunching and numerical tasks.
In my experience, the major bottleneck in data-processing with Red is mezzanine implementation of load and lack of first-class datatypes to handle tabular data; also, lack of dedicated NumPy / APL-like dialect and somewhat non-existent scientific / DSP stack (i.e. packages and libraries, or at least R / Python FFI).
jlhouchin_gitlab
17:47I do not currently understand Parse or load. Nor do I know whether what I am working on qualifies as Big Data. However, for a single instrument in the current format that I care about, is about 3GB of csv text. I have 697 files for each week from 01-01-2006 for each instrument I am currently interested in. My current format for that pricing data is simple. >datetime,price >2019-05-05T22:00:00Z,1.118
In the future when I am parsing true tick values as in the above csv file. The date and time will have milliseconds.
Candles as I use them have them are like: >datetime,open,high,low,close >2019-05-05T22:00:00.000000000Z,1.118,1.11814,1.118,1.11808
But the way they are in common usage it will be more like: >datetime,bidopen,bidhigh,bidlow,bidclose,askopen,askhigh,asklow,askclose,volume
I don't care about the volume or the spread so I average the bid/ask.
I don't know about your Parse scheme above, but these values do come in as a timeseries. All the values are associated with a particular point in time. So they would have to be processed in such a way that the association is preserved.
Thanks for your time in helping provide a great solution for this problem. I hope to learn much.
greggirwin
18:26> Another advantage of having a keyword for that, is avoiding the use of temporary words to point to beginning and end of each token, which would then be passed to a load/part in a paren expression.
That's a nice shortcut, but the other points raised are important. We don't know if it would be a win, so I'd put it on a back burner to think about. If the solution is in your head @dockimbel, and easy to try, it could be an experiment. I do think we want to emphasize using Red/Ren format as the easy solution long term, and making load do the heavy lifting. Where performance really matters, Redbin will be available as well.
For many people, just getting started will be huge, so I'm anxious for the JSON and CSV codecs.
18:28@9214 on tabular data, you mean stuff that is visually aligned with spaces, not delimited by tabs, correct?
18:28If so, I'll see if I can find an old experiment I did many years ago.
9214
18:35@greggirwin usually it's delimiter-separated formats.
15:47is the internal format of the data is the DATA instruct RED how to consider the source DATA using existing red types is custom loader for the DATA
16:05@greggirwin CSV loading and saving is currently handled by Munge.
16:44@GiuseppeChillemi The discussion above is about a load keyword in Parse. The regular load already has a /as refinement. Moreover the load function arity does not match your description.
GiuseppeChillemi
16:52@dockimbel Thank you Nenad for teaching me to not speed read topics with the masters ;-)
greggirwin
17:39@GiuseppeChillemi @rebolek also has a CSV loader, and there's some other great old work by Brian Hawley. Munge, and @Dobeash are the most complete, time-tested in heavy business use that I know of. System/codecs, and Red's approach to this, makes extending things easy, even for custom formats.
jlhouchin_gitlab
17:46Is there JSON parsing, or loading? The REST api I subscribe to is all JSON.
greggirwin
17:51We have some in the works, pending some decisions before getting them into mainline.
- https://github.com/giesse/red-json
The readme there will point you to some others as well.
20:25@jlhouchin_gitlab my HTTP-tools come with JSON encoder/decoder.
meijeru
08:48I have published a request-date function [here](https://gist.github.com/meijeru/c56d0aa547180ed5d6a7630d5c09674a).
GalenIvanov
13:46@meijeru Very nice! Maybe I'll try to make my own (just for the sake of learning) before examining yours.
meijeru
14:52It is not difficult at all, just provide 6 lines of weekdays, because 31 days in a month can indeeed span 6 lines. Red's date arithmetic makes it more easy than with other languages.
08:31I think pull requests are not possible with gist, people can fork and work on their own versions and keep the revisions history, but cannot contribute back to yours. No?
planetsizecpu
11:25@meijeru Good job, requesters are ever useful!, I would add some colours anyway.
JacobGood1
02:59When is the next news post, it has been months.
13:39@9214 @hiiamboris FYI, I am looking into reimplementing infix support in the interpreter, so we can better handle edge cases with left operand lit-argument calls.
hiiamboris
14:50@dockimbel Great! And an interesting design problem the way I see it: In a b c d expression, should we evaluate a? It may be that b is an operator taking a literally. However to know that we should evaluate b. But we can't - what if a is a function that takes b literally? Or c is an operator that takes b literally?☻ With a,b,c,d being words it looks trivial enough - peek enough times behind words bindings and there's a solution. But then these may be paren-expressions or function literals or (omg) paths with parens inside... I recall there was an issue about operator not working when referred to by a path.
14:52There's a recent related discovery of mine - https://github.com/red/red/issues/3883. I hope we can achieve decent compiler support as well.
dockimbel
15:11@hiiamboris It's a non-trivial design problem indeed. The interpreter needs to look ahead to make a proper decision, though such lookaheads are expensive.
9214
15:35@dockimbel are you not satisfied with my proposal or the op! handling code itself is in a desperate need of major revamp? Don't forget about https://github.com/red/red/issues/3344 and https://github.com/red/red/issues/3585.
15:44I also wonder if op!s can support [dirty 'argument [any-value!] hack](https://github.com/red/red/wiki/[DOC]-Guru-Meditations#variadic-function) - that would make *postfix* operators possible :neckbeard:
21:03@dockimbel turns out it isn't mine, but from some mysterious 9410 guy https://github.com/red/red/commit/ff1ad4fb4701c9603a78cfc9175948178fa5d764 :smirk:
beenotung
06:21the binary of hello world program in Red 0.6.4 is 40KB on linux, it is much larger than those even-more-complex demo shown on the website, is the red team aware of this? The example I'm using is print "hello"
07:39Oh, I remember wrongly, it was rebol program being that small http://www.rebol.com/pre-view.html
07:39but I suspect it's talking about the source file size, not the binary file size
rebolek
08:16@beenotung certainly, Rebol wasn't compilable, so it's source file size.
rishavs
08:52Hi folks. quick question. What are the chops of Red in the area of 2d gamedev? I am looking to make simple 2d management games. Is Red's current stage of development good for me to start with? Or should I look elsewhere?
PierreChTux_twitter
08:54Hi @rishavs , there have been a few successful games written in Rebol, in the past, and Red has now (from my perception of things) reached the point where it is usable to do such stuff.
rishavs
08:55Thanks Pierre. Are there any repos/articles/libraries of note that I should look into?
PierreChTux_twitter
08:56I'm trying to remember one of those games... It was a good one (I'm not a gamer myself, I just took for granted the opinion of others...).
rebolek
08:57There are no game-related libraries, AFAIK. @planetsizecpu is developing nice 2D game, see https://gitter.im/red/red/gui-branch for details
PierreChTux_twitter
09:00http://machinarium.net <= I cannot access this page right now (firewall at work...), but this is that game that I was thinking about.
09:01https://www.softinnov.org/rebol/rebox.shtml And I let you guess who was (is?) ininvolved in SoftInnov...
rebolek
09:02@PierreChTux_twitter Amanita games are technically not in Rebol, they use different engine. @Oldes wrote Rebol dialect to emit required bytecode.
PierreChTux_twitter
09:03Read from https://notamonadtutorial.com/interview-with-nenad-rakocevic-about-red-a-rebol-inspired-programming-language-681133e3fd1c : "Once we reach 1.0 (next year), Red will also be very good for: webapps programming servers creation 2D games robotics "
09:03@rebolek oh, I thought the game was written in Rebol. Sorry for confusion.
rebolek
09:05@PierreChTux_twitter @Oldes can give us details
PierreChTux_twitter
09:07@rishavs you can have a look here: it's relatively old Rebol stuff, but I bet most of this code can be Reddized quite easily (hopefully). It should give you an idea of what has already been done in the Glorious past of Redbol world! http://www.rebol.org/st-topic-details.r?tag=type//game
Oldes
09:09The latest game I was working on was made in Flash (Adobe Animate CC) and Rebol was used to parse the SWF files with animations and convert it to custom binary format suitable for payback using Adobe's AIR.
PierreChTux_twitter
09:10@Oldes okay; thanks for clarification, and sorry again for confusion!
10:57@Oldes You work with Amanita? Machinarium is one of my favorite games!
planetsizecpu
11:33@rebolek thanks for the compliment @rishavs I hope you find it useful
rishavs
15:21I have actually played Machinarium and loved its quirkiness. Nice to know that its in rebol.
pekr
15:37Not done in Rebol. Rebol just generates the code.
Respectech
17:33Hmm. I followed the game link above to rebol.org and tried to play Galaga.r, but it had a problem with 'rebcode. I'm using REBOL/View 2.7.8.3.1 1-Jan-2011, and galaga.r was written in 2007. I remember something about 'rebcode. Did it get deprecated?
pekr
18:24Yes, was experimental and later either removed, or at least was not part of R3, due to the change of overal architecture ...
greggirwin
19:00@rishavs as others noted, we don't have high level support or libs to make game dev easy yet. Input form game devs, on what features they most want and need, and what type of games they write, is *very* welcome.
jfrew
02:11Hi there! Brand new to Red, I'm having a couple issues with setup. Would anyone mind being tech support for me for a second?
beenotung
02:46I wonder if I can compile from the red console (instead of switching between red console and shell)
jfrew
02:55I've downloaded Red and it's secure in its own folder. I'm on Mint, so I installed that extra library. I then did the whole chmod u+x red-064 thing.
02:56Now, when I type Red in the term, it starts a process.
02:56But any input I type and hit enter on gives me a '?' in a new line
02:57I wrote up the hello world and attempted to load it and the output was "Newline appended" and then a newline with "50"
02:57So something's not right here, or I've messed something up.
03:01Alright, I've built the console, so I can operate the repl, but I'm still getting the Newline appended 50 when I run hello world
greggirwin
03:43@beenotung not currently. We do want to support that feature. In the near future, we're planning to make the console the download, and it will download the compiler on demand, if needed.
beenotung
03:45 Isn't the console and compiler bundled in the same binary already ?
03:47When you first run the compiler, it builds the console locally right now.
03:48@jfrew you may be seeing a recent issue that came up in the console, which should be fixed very soon. The GUI console is not affected, but it's not available on Linux yet. I don't see the issue here on Windows now, so you may have downloaded a glitched version where the problem existed.
14:29FYI, we have pushed new commits changing the behavior of map! datatype:
* We drop the concept of "virtual keys" in maps (from R3). * Now none values are accepted as possible values in maps. * Removing a key/value pair is now done by using remove/key map key. * find on maps now returns the first matched key instead of true.
Those changes are mostly motivated by the need to support JSON data in a convenient way in Red.
14:38We are also extending remove/key refinement to support series, replacing the following pattern:
remove/part find/case series key 2
9214
15:00@dockimbel and map/non-existent-key still returns none?
dockimbel
15:04It returns an error when you are using a path accessor, and none when using select.
9214
15:12Hmph... the previous behavior was symmetrical (put with select or map/key: for insertion/deletion) and composable (I recall e.g. common pattern for memoized functions)
foo: func [arg][memory: #() memory/:arg: any [memory/:arg arg + 1]
So I don't really like this change. Although, I don't see any other way of keeping the old map! without introduction of new datatype or unset abusage.
hiiamboris
15:16What are the arguments against unset denoting an absent key?
dockimbel
15:16Well, this is the best trade-off we could come up with for now. Splitting map into two distinct types is an option for the future, though, it could be too confusing for most people.
15:17@hiiamboris Setting a key to unset is not really a good interface. Moreover, we want to reduce the reliance on unset, not extend it.
hiiamboris
15:21@dockimbel Will unset be banned from being permitted to be assigned as a value for map keys, or be left as it is?
dockimbel
15:23There are no more restrictions on the values in maps, so you can store unset values if you want:
>> make map! append [a:] ()
== #(
a: unset
)
hiiamboris
15:24it was possible before as well, like m: #() m/key: ()
15:25My personal preference is having two map-like datatypes, though I am not sure that this is the best option.
15:32@9214 > Hmph... the previous behavior was symmetrical (put with select or map/key: for insertion/deletion) and composable (I recall e.g. common pattern for memoized functions) >
text
> foo: func [arg][memory: #() memory/:arg: any [memory/:arg arg + 1]
We could make the path accessor return `none` also on missing keys, but you couldn't then make the difference between that case and a key with a `none` value. If you want to force the old behavior, then you can use an asymetrical pattern:
15:33> but you couldn't make then the difference between that case and a key with a none value
But the same can be said about select returning none instead of erroring out.
dockimbel
15:34@9214 Yes, but you can choose which behavior you want using different accessors.
9214
15:38> My personal preference is having two map-like datatypes, though I am not sure that this is the best option.
That tingles my spider sense, the way proposed hex! (for Ethereum addresses) does - creating datatype for a narrow use-case which turns out to be way too specific, and cannot be used in general code (map! now has a lot more subleties, hex! has a mandatory minimal length to omit clash with pair!).
15:46Personally, I have never been a fan of map! introduction in R3, as a replacement for hash!. I still prefer using the much more versatile hash rather than map. The main reason I have added it in Red and even gave it a literal syntax, was to represent common datastructures used in JSON format and in other languages. Though, the R3 map model does not work well for that.
hiiamboris
15:48Personally I don't see how 2 maps is any better than abusing unset. Plus I suspect without unset or none there will be even more inelegance: like how I'm going to fetch the keys from a map with unknown contents? wrap each access in an error-try block? I've already shown in a ticket how ugly that block really is.
9214
15:48Well, I have an idea, but I wouldn't call it a "better" one. Like I said, if we want to keep the old map! behavior, it's either unset abusage or creation of new datatype (or maybe redesign of unset) - something that cannot be really stored, loaded or even represented, but can result only from "meaningless" computation. If you set word or path to it or put it somewhere - it either unsets a word or evaporates the key.
But that's just a wild thought, problem with map! can be tackled from many different directions.
dockimbel
15:49@hiiamboris Just use find. If you need all the keys, then keys-of.
hiiamboris
15:49But that will mean two lookups instead of one, no?
dockimbel
15:50Correct. But those are constant time lookups.
hiiamboris
15:51But very slow (from my experience in pure functional DSL) compared to other Red operations.
dockimbel
15:51It's a hashtable underneath, so it is bound by the hashing time, which should be very fast.
15:54BTW, we should add foreach [key value] map [...body...] support for processing maps with unknown content, in an efficient way (not requiring preliminary extraction of all the keys in a block).
hiiamboris
15:56It will be great to have (unordered) lookup-free iteration indeed.
9214
15:59The problem is that none is "storable" (it's a first-class value that you can put anywhere), but when it comes to map! it's suddently a "key evaporator" (in old behavior). Same with unset - it's storable too (albeit not very user-friendly), but when it comes to any-word! it's suddently a "word evaporator". To me this points a design question - should there be something non-storable that evaporates anything that it touches (keys, bindings, other values)? Like, I don't know, eraser!?
pekr
16:10I will not pick sides on the map itself, but at first sight, remove/key on series looks a bit strange, as series! type does not have any means of keys, no?
dockimbel
16:11@9214 Words don't evaporate in contexts in Red. A non-storable value is not a value in Redbol, therefore such construct cannot exist there.
16:12@pekr select and put are a key/value oriented API on series already. remove/key will also apply to series, @qtxie is currently implementing it.
16:13@dockimbel yes, they are just paired with unset value. That's why I said that it's a wild thought.
dockimbel
16:16@9214 I have no problem with none erasing a key/value pair when set in a map. That is just a datatype-specific semantic rule, and it's just a convention. And as you said, it gives an elegant symetrical access model. We could reuse such interface in future other non-series datatypes. The main issue is that such interface precludes maps from being used in some common use-cases.
9214
16:18Yeah, exactly. none is the closest synonym to null in other languages and data formats (including JSON), so, if you want to work with the outside world, you need to store it in map!, but then "none-deleting" convention no longer applies.
dockimbel
16:20So maybe the elegant solution would be to come up with a very different access interface for maps? But I don't see any good alternative for now.
9214
16:22And, like you said, we can harden map! for real-world even further (json-map! or something like that, which can store any value) and keep the second classic version for intra-language use (store everything except for none). But internally it's the same key/value structure, it's just that conventions (i.e. interfaces) are different and have opposing use-cases.
dockimbel
16:25That's precisely my plan, yes (codenames: map! for current one, and dict! for the none-less variant). Though, I still have to convince myself that there is no better alternative.
16:28I think we need to gather more data about real-world map! usages in Red before deciding. We'll see how things play once we get JSON supported natively (should be soon now that maps are compatible).
9214
16:31I'd widen the scope and considered all common data exchange formats + all abstract data structures that they implement (dictionaries, trees, tables, etc). IIRC some interesting article on this topic came up recently... ah, [here](https://vasters.com/blog/data-encodings-and-layout/) it is.
16:38@dockimbel I wonder if port!s and utype!s (and your idea of their unification) can help with separation of interfaces (JSON-like map! vs. classic map!) from implementation (key/value dictionary).
16:45@9214 > I'd widen the scope and considered all common data exchange formats + all abstract data structures that they implement (dictionaries, trees, tables, etc). IIRC some interesting article on this topic came up recently... ah, [here](https://vasters.com/blog/data-encodings-and-layout/) it is.
Well, block! is our basic building block (no pun intended), and we should be trying to stick with it (and its derived types) as much as possible.
16:48Given that perspective, making maps act more like series would make sense. That's the theory. In practice, some basic series actions like insert or remove (without /key) don't make sense. Then you can question if even index positions make sense in that case. Then the series model goes out of the window. Though, @greggirwin seems partisan of moving maps to the series model, maybe he has come up with some good trade-offs.
17:45Just thinking loud: one way to make sense of the series model on maps could be to make the key/value pair the basic series element, and keep a strong ordering...
giesse
18:03@dockimbel even if it's seen as just a series of keys, it would work. but, ideally, yes, a series of pairs. All you need to do is maintain order which you already do (and hash! has to do too). It's why it's my preferred approach instead of adding /key.
That being said, custom types and type classes would be even better, if we want to go there. :)
rebolek
18:29@dockimbel > find on maps now returns the first matched key instead of true.
Does that mean that the order of keys is now guaranteed?
dockimbel
18:39@rebolek It is with the current implementation, but that could change in the future.
hiiamboris
18:46What if we just make maps accept a typeset of values that's possible to hold in it, like we specify types for vectors? Then we'll both have normal maps, JSON maps, and typechecked maps where one wants to go strict. Most often used variants we can alias for accessibility, like we have face! and reactor! as kinds of objects.
rebolek
18:55@dockimbel wouldn't then returning true on find make more sense to be future-compatible?
dander
18:56For the map/key on non-existant keys, what if it continued to return none, and instead have a select/strict (or something) when you want to distinguish between a missing value or one that is explicitly set to nothing. My impression is that in the vast majority of cases, people won't care which one it is.
dockimbel
19:35@rebolek No, we need find to return the first matched key because it's case-insensitive matching by default. "first" means first found, whatever the storage order. Using that info, you can write code to remove all the keys from a map differing only on spelling:
while [k: find map key][remove/key map k]
19:42BTW, one future option is also to make map strictly case-sensitive.
19:45@hiiamboris > What if we just make maps accept a typeset of values that's possible to hold in it, like we specify types for vectors?
It's not just about the accepted values, but also about the accessing interface. none being treated as a special value by maps results in a nice interface. You can't switch to that behavior with just an extra typeset in map. Though, having a type-restriction on map values could eventually be useful. But then why not in objects too. ;-)
PierreChTux_twitter
19:49> But any input I type and hit enter on gives me a '?' in a new line
Hello, When you hit Ctrl-D, does it stop and go back to your shell prompt?
19:52If it is the case, it looks like you're invoking the red program, which, on a standard GNU/Linux system, is a script calling ed, a line-oriented text editor.
19:55It happened to me a number of times... My red (the marvelous language that we're talking about here) executable was in my $PATH, but if I changed the order of the $PATH, then all the other programs calling the standard red (located in /bin/) went mad...
19:56I solved the problem by renaming to redlang the Red language interpreter. That goes back to another subject that we discussed in real life with @ldci .
20:00> BTW, one future option is also to make map strictly case-sensitive.
How strictly? Even for word-keys?
hiiamboris
20:04@dockimbel My idea was that one working with json-map! would then use ugly shadowy practices, while one working with generic-map! would safely rely on select returning none. True though, a better interface is asking to be invented ☺
rebolek
20:12The problem with json-map! or whatever-map! is, that it would also need json-number!, json-string!, etc.
22:19And here I thought the map! battle was over. ;^)
We can write up more notes, and add to the map design wiki page, but know that a *lot* of discussion took place about this already, and this is the best option we could all agree on...for now.
It's an interesting problem, because Rebol's long gestation led to Carl *not* including a map type originally. Of course, it's not needed, because you can do it all with blocks (no performance arguments here please). And path syntax makes them good enough, but there are hard edges if you really need to treat data as key-value pairs. It requires /skip/part 2 2 or *-key wrappers (which is perfectly doable, if not as elegant).
Deleting via assignment is not a good interface, even if the symmetry is appealing. It can be fine, as long as you *never* care about whether a key exists, versus storing an empty value. For example, if you load JSON, and get a null value, the old model deleted the key from the map (or never set it). So you could not round-trip data, because your loader is lossy.
But it gets even more interesting, because we want specific types, with tailored behaviors, but we also want flexibility. It's lovely to think that you can just change from a block, to a map, to even an object, and the code using those targets won't even notice. But, oh, the wrinkles; the details; the tradeoffs. That's why there's no perfect solution. Do you prefer Lisp or Lua because they have a single data structure everything is built on? Or do you cringe at the limitations and overhead? We'll never get consensus on *that*. Now, consider that DCOM and various RMI approaches said "It's transparent! You don't need to care if an object is local or remote!" Except you do, sometimes. Or the beautiful part of MUMPS where maps and the DB share the same interface, and only a sigil tells you whether something is persistent or not. You could even work against a local map and then merge it to the DB. But where is the schema enforced, or is there a schema at all?
What we need to do is step back and look at the language as a whole. We have to balance ease of use, flexibility, PoLS, robustness, and clean consistent interfaces.
--- As a side note, I'm not partisan toward making maps series types. It will be convenient to iterate over them, but also imply ordering which may not be guaranteed. I'm good with mezz wrappers for that right now.
05:51especially map/non-existing-key -> error! will break lot of my code.
greggirwin
06:19@rebolek yes, I don't see my note about my preference for getting a none result in that case. Too many channels.
06:21I would like path access on a non-existing key in a map to return none, as with blocks, rather than an error, as with objects. Maps are dynamic structures by design.
06:35Yesterday Doc replied to me, that remove/key is OK even for series, as e.g. SELECT treats series in a map-like way. I still scratch my head a bit here though and proper documenting is going to be needed imo. Was it meant like SELECT providing a map like API to series, treating it in a key/value pair manner? Because - a series is still a series, right? :-)
06:36Btw - so far the help string to removedoes seem to say /key "Removes a key in map"
greggirwin
06:54remove/key on series doesn't currently use /skip 2 logic, which I think it should.
pekr
07:04I noticed the following examples: remove/key/part blk 'b 2 vs remove/key 'b - that's probably what you mean?
>> blk: [a b c d e f]
== [a b c d e f]
>> remove/key/part blk 'b 2
== [a e f]
In a strict key-value structure, b would be a value, not a key. /part is separate, and should probably be mutually exclusive to /key.
pekr
07:16maybe we need remove/value too, where remove/key would remove key and value, and remove/value would put none to the key value slot :-)
07:17But - I am the last one to see the consequences, to take me just easily :-)
dander
07:39So the map/non-existing-key -> error! change is just because having maps able to store none values means that we need a way to distinguish between literal none, and a missing key/value pair. Do I have that correct, or are there other reasons besides that? The point I wanted to make before was that I think for the common case, I wouldn't expect people to actually care which situation it is (none vs missing). In the case of needing to robustly round-trip the map, there can be more careful functions to do that. It seems similar to me how string comparison is case-insensitive by default - I assume this is because it makes the common case easier.
rebolek
07:59@dander I understand the rationale behind the need for distinguishing between none value and missing value, but as @greggirwin rightly pointed, block! still has the same behaviour:
11:42We will do some adjustments to the map API, and will relax the path access on non-existent keys to return none instead of an error, for sake of consistency with blocks, rather than with objects, as maps are more dynamic by nature as pointed out above.
11:44@greggirwin I love the "feature wars" wiki page. :+1: ;-)
11:45@dander > Do I have that correct, or are there other reasons besides that?
Yes, that's the main reason. Also, it would have emphasized that we are throwing out the "virtual keys" concept, but that's a very minor reason.
11:49@planetsizecpu Please post a bug report to red/bug rather than here. Also, please provide enough information for readers to be able to reproduce the issue. EDIT: it's probably related to map changes, so wait for the new map fixes before submitting that report.
planetsizecpu
12:42@dockimbel I already guessed it was due to map! now it is already fixed with the new update: Red 0.6.4 for Windows built 24-May-2019/13: 56: 13 + 02: 00 commit # d56d840 thx
dockimbel
13:07@greggirwin Blocks are not enforcing a strick key/value model by default. select matches any value in the block, and "keys" can have duplicates. So remove/key has also a relaxed matching on series (with an implicit simple find internally). remove/key/part allows to remove several values with the matched key, so that we cover virtual records case in blocks. I think that is as far as we should go for it. A proper record-oriented API, superceeding /skip mode, should come with slices.
raster-bar
16:04does anyone know if these diagrams are outdated? if yes is there a more up-to-date version? http://www.learningred.com/blog/2013/12/24/visual-guides-to-red/
9214
16:11@raster-bar they don't look outdated to me (on a quick glance), word! memory layout is correct, but memory allocator have changed a bit (e.g. garbage collection); the most up-to-date version is runtime code itself.
16:15@dockimbel when we do the blog article, we can include some example mezzanines, showing how to use blocks as strict key-value structures, so your above message can be part of the design rationale there as well.
18:29@dockimbel > We will do some adjustments to the map API, and will relax the path access on non-existent keys to return none instead of an error
So, to check if a key exists, we'll need to use find map key rather than map/key, which may return none both if key is present (and holds none value) or absent?
18:31In such case, perhaps exists? should be extended to handle map!s? Not very useful, but a convenient shortcut, and returns logic! rather than key value.
18:33@greggirwin worth to note that in the upcoming blog post and in docs (@gltewalt).
18:40@BeardPower you mean in? That's a tough call, which again boils down to map! being partially block! and paritally object!. in is used exclusively for any-object! values.
greggirwin
18:41Exists? would then change arity, unless you make it take a path to a map, which we want to avoid.
18:42Rebol has a found? func, which just casts to logic, if that's needed, e.g. for pick usage.
18:45I've sometimes brought up a "key existence" func idea, as it seems sound. But I've found that I didn't use found? with find when finding if a key exists very often. Find by itself is *just* convenient *enough*.
giesse
21:54@9214 find returns the key not the value, so it's pretty safe to use as it is.
9214
22:20@giesse I'm not sure why you telling me this. I've never said neither that find returns (or should return) value from key/value pair, nor that it's "unsafe".
jfrew
22:42@greggirwin Thanks for the info! I was beating my head against the wall trying to figure out what I was doing wrong. I'll keep my eye out for a new version. Might download the windows version and give it a spin on wine.
22:56Yeah, most recent nightly still has that problem.
BeardPower
23:07@9214 Yes. Some languages like python use it. Nim has
contains
.
giesse
03:28@9214 > In such case, perhaps exists? should be extended to handle map!s? Not very useful, but a convenient shortcut, and returns logic! rather than key value.
I may have misinterpreted that.
pekr
04:51"find returns the key not the value" .... IIRC, findreturns whatever it finds, key, or the value and that's the problem with series. If you want to treat it in an key/value manner, you have to use find/skip, no?
In your example, find m 'a returns one of the m's keys, which is a *value* a: of type set-word!.
dockimbel
10:13find should probably return a word! value there instead of a set-word!.
giesse
18:37@9214 since generally they are called "key value pairs", the expression "key value" is ambiguous. I don't know why you are telling me that a: is a value.
18:38@dockimbel well, if internally word keys are converted to set-words, then it makes sense the way it is, though it could be confusing for new people. OTOH new people would be confused by find vs select anyway.
greggirwin
19:02Can anyone else confirm the issue @jfrew reported [here](https://gitter.im/red/red?at=5ce60bb80ac9852a9524bdbf)?
giesse
19:19@greggirwin I just re-downloaded the binary from https://static.red-lang.org/dl/linux/red-064 to confirm, I'm not seeing any issues on Ubuntu.
19:20I suspect that, as others mentioned, they are running ed instead of the Red REPL
13:24Okay. I like the way one can simply read a webpage as print read http://example.com which is useful for backend projects.
13:25Maybe for converting to javascript one can use emscipten?
13:26but that only works if Red can be converted to LLVM bitcode..
9214
13:26@MyIsaak JS and WASM are of low priority for now. Emscripten needs LLVM bitecode, whereas Red and Red/System have their own separate toolchains, which emit machine code directly.
MyIsaak
13:28Okay. So what is high priority at the moment?
9214
13:29Consult the [roadmap](https://trello.com/b/FlQ6pzdB/red-tasks-overview).
greggirwin
14:04@realTopXeQ_twitter you can check out some experimental formatting work [here](https://github.com/greggirwin/red-formatting).
pekr
14:16It would be nice though, if some blog update would be on the horizon, as I can see such questions being repeated here from time to time ....
03:24And this question? https://stackoverflow.com/questions/56371208/why-post-in-red-language-change-the-first-character-of-parameters-to-upper-case
Oldes
15:34pick accepts logic! as an _index_ value, but not none!, what about to allow none too and deal with it as a false?
hiiamboris
15:56I thought about that too recently. Problem is, when you pick with an integer you expect it to fail when it gets a none for some reason. If we accept none, it will never fail and bugs will propagate.
raster-bar
16:00just curious why none should result in a second item and not none ? seems counter-intuitive
hiiamboris
16:04@raster-bar Yeah that too. The use case is that when you have an f: func [/ref flag [logic!]] [...] you just wanna write pick [1 2] flag. But that fails on none so you write pick [1 2] yes = flag instead. No big deal, but raises this question.
16:53@realTopXeQ_twitter we also have red/code and red/community repos.
17:04Pick with a logic value has always caused my brain to stutter. I have to think about it, even after many years of Reducing. I understand the design, but don't think it's a good one. I would fight to remove it, but I don't know how much Red code would be affected. (listen for the parse-based scanners to start running).
While I understand that it seems like a nice shortcut, small word, less blocks than either, etc. a fundamental problem I have is that logic values have no inherent ordering. For sorting purposes we can impose one, but the sort order is the *reverse* of the index order in a pick block. Pick matches the order, as either would, so it makes sense, but these little discontinuities mess with my head somehow, so you will rarely seem me use pick+logic. It makes me think.
17:07@greggirwin We could change sort on logic values to be consistent with conditional expressions order. I don't think that would break anyone's code anyway. Though, none is nothing, so "less" than true which is something, so sort ordering on such values could become very hard to guess. So, I am not annoyed by sort having rules that make more sense in a sorting context.
greggirwin
17:09Sort shouldn't break things, I agree, but I don't think that solves the problem for me. The current sort order actually makes sense (feels right at a glance). It's the intersection of these two concepts that's tricky.
17:11It's a question of whether pick+logic is conducive to writing clearer, more correct code. For some people, it may very well be. As with most things, it's a rule to learn.
dockimbel
17:12pick with a logic index provides a cheap ternary operator (as in C's condition ? value_if_true : value_if_false). We could come up with a specific new native function for that, but isn't less more in this case?
greggirwin
17:14As noted above, I get that, but either is just much clearer to me. I never liked ?: in C, but I *love* either.
dockimbel
17:15either implies an evaluation of the chosen block, pick just extracts the chosen value from a series. So those are not totally equivalent options.
pick "12" true
vs
either true [#"1"][#"2"]
hiiamboris
17:18To me, pick logic looked weird only a few first times. Then I realized it's true-then-false and it sorta feels natural ever since to me. I often use it to avoid double brackets of either [[]][[]].
greggirwin
17:18Again, understood. I get the efficiency win, and more if you want *not* to evaluate something. That does get uglier with either. It's the mapping of a logic to an index that has just never set well with me, even though I understand it. And I've tried, but (this is just my personal experience, and we know my brain is funny), I get the order wrong quite often when using pick with logic, so I tend to avoid it.
dockimbel
17:18@hiiamboris I also tend to switch to pick in those double bracketing cases.
17:20@greggirwin If we rename the second pick argument to something else (like selector, or anything better), would that make it easier? index is the argument name, because in most use-cases, it's an index.
greggirwin
17:21And I get that it's clear for some people. Just not me. :^) And if "me" is not "only me", what % of users that are confused by it (this is a general language issue, and we have 1000 of these questions) should make us think: Hmmm, does this help or hurt us overall?
17:22Changing the arg name makes no difference. You only see that a couple times, then it's invisible. And index speaks to a location in the target series, which is good.
Oldes
17:24It definitely does not hurt. One don't have to use it. The question was if its ok not tu support none. But probably its ok how it is now.
nedzadarek
17:27> To me, pick logic looked weird only a few first times. Then I realized it's true-then-false and it sorta feels natural ever since to me. I often use it to avoid double brackets of either [[]][[]].
@hiiamboris would you still understand pick version after month(s) of not using the Red?
The problem with that is it leaves you open to anything. Constraints are helpful. If something is allowed, it will be used. Then we also weigh benefits. In a corporate world, you may have standards, to ease commodity programming (we are cogs), while a lone wolf can care only for their own efficiency and taste. In a FOSS world, unstoppable forces meet immovable objects. I'll let @dockimbel explain what happens after that. He's the physicist. ;^)
hiiamboris
17:28@greggirwin also is also not clear to some people. So what? I think it's brilliant. And today I saw it's source code and was simply amazed. Stroke of genius! ☻
@nedzadarek Absolutely.
greggirwin
17:28Sorry for all the English idioms @Oldes. I can rephrase is that isn't clear.
nedzadarek
17:29@hiiamboris good for you, but I'm only human, hence, I would forget.
Oldes
17:30@greggirwin no problem.. I understand you.. but don't agree:) Redbol was always about freedom of choices. That is why we have datatypes.
greggirwin
17:30Also is an *amazing* function. Truly brilliant. I almost hate it. :^) I actually hear my brain seizing up as it reorders the result. But, OMG, it's it brilliant. @giesse gets credit for that, IIRC.
17:33> Redbol was always about freedom of choices. That is why we have datatypes.
Noooo! :^) Datatypes are there to eliminate freedom of choice. Well, I get what you mean here, in that we can use and leverage them very creatively, to make intent clear, reduce code, etc. But (for those listeners not deep into Red yet), having a *larger* commonly agreed upon set of fundamental datatypes is perhaps our greatest empowering constraint.
17:38Then we get to argue about how to use them all. :^)
pekr
18:03IIRC, there was some webpage on rebol.com, dedicated to Rebol gotchas. General notion was to eventually remove those cases, but some of them were considered being a deep part of the language (like subobject sharing, etc.)
greggirwin
18:20Language design is interesting, because people are still involved. If we ever change that, languages can be very different, and consistent. The artificial language Lojban was designed to be unabmiguous. That makes it great for some things, but also makes it *very, very* hard to write poetry in it.
dander
18:35I wonder if people would be more receptive to using either as a ternary statement if it allowed any values, instead of just blocks. Would that twist its use case too much?
result: either selector 1 2
result: either wrap-block? reduce [value] value
either choice [do some stuff][do other stuff]
18:36@greggirwin, your comment about Lojban made me think about [Rockstar](https://github.com/RockstarLang/rockstar/blob/master/spec.md), which I recently found out about, and is hilarious and amazing
20:26@dander while we allude to Red Bull, I am now officially a Rockstar fan. Holy cow! Poetic literals, *and* the same issues we found with Dec64 (just ask @BeardPower about his missing hair).
> if you can't sing it, you can't have it.
We need a tagline this good.
draegtun
21:33@rebolek Yes it's a nice feature. In R3(-alpha) it did have restrictions...
>> either/only true {a} {b}
== "a"
>> either/only 1 2
** Script error: either is missing its false-branch argument
Later this was "fixed" (in Ren/C but perhaps before) with /ONLY refinement dropped (probably just in Ren/C)...
>> either true {a} {b}
== "a"
>> either true 1 2
== 1
but not surprising evaluation issues with this did occur :(
So this was (rightly) removed and i think the sweet spot found was QUOTEing the branches....
>> either true '{a} '{b}
== "a"
>> either true '1 '2
== 1
>> either true '[a] '[b]
== [a]
giesse
22:10The only sane way to do that, IMHO, is to take the implicit do out of either:
>> either*: func [cond tv fv] [either cond [tv] [fv]]
== func [cond tv fv][either cond [tv] [fv]]
>> either* true 1 2
== 1
>> either* false 1 2
== 2
>> either* true "a" "b"
== "a"
>> either* true 'a 'b
== a
>> either* true [1] [2]
== [1]
>> do either* true [1] [2]
== 1
However, I don't think anyone wants to write do either ... all the time. It would make sense though to go with something like:
>> either*: func [cond tv fv] [tv: either cond [tv] [fv] either block? :tv [do tv] [:tv]]
== func [cond tv fv][tv: either cond [tv] [fv] either block? :tv [do tv] [:tv]]
>> either* true 1 2
== 1
>> either* true [1] [2]
== 1
22:12Which makes me wonder, is there a name for a function that acts as the identity if a predicate does not match, but will pass it through another function if it does? It's kind of like a filter, but not quite.
22:14It may seem like a weird thing to think about, but the repetition in either something? :x [do-something-with :x] [:x] is bad.
22:17BTW @nedzadarek also was born out of the attempt to not have to have temporary words all the time, similarly to how you asked about filter functions in parse to avoid having to use a temporary word. ;)
greggirwin
22:44This is where a simple mezz is a great problem solver, IMO. @giesse's example, which I could call either' to denote literality, solves the problem elegantly, concisely, and explicitly. I admit that seeing things tacked on in other langs has often made me resist making this a blessed approach. e.g. the ! sigil in Ruby that denotes modification in place, IIRC.
Either evaluates, because, we can probably all agree, that's what you want most of the time. I daresay the *vast* majority of the time. And while free-ranging evaluation is a beautiful thing in many ways, I believe it's also necessarily balanced by the structural syntax Red has. This helps us break things into chunks for human mind processing (some of you don't have human minds, and can process anything without apparent difficulty :^).
22:46Having either support non-block args is seductive (my favorite word of late, it seems), but only makes the language different, not definitively better.
22:50"Seductive" may not be the perfect word, but I like it. It's alarming enough to raise caution, but not *always* a bad thing. What it says to me is that you may not know whether the result will be good or bad until some time later.
22:51@giesse's example is also key, because it shows how easy it is to prevent evaluation in Red, which makes it quite different from most languages.
22:52The fact that evaluation is such an important concept of Red would be greatly lessened were it not also for the control we have over it.
nedzadarek
23:10> the ! sigil in Ruby that denotes modification in place, IIRC.
Not exactly correct: [source by Matz - Ruby creator](https://www.ruby-forum.com/t/conventions-in-ruby-and-the-principle-of-least-surprise/158706#773946) > The bang (!) does not mean “destructive” nor lack of it mean non destructive either. The bang sign means “the bang version is more dangerous than its non bang counterpart; handle with care”. Since Ruby has a lot of “destructive” methods, if bang signs follow your opinion, every Ruby program would be full of bangs, thus ugly.
23:12@greggirwin make sense, thank you for the information.
greggirwin
23:23@giesse on the identity func question, is it like filter or a single value map-if? In either case, it's something to add to our HOF design notes. I've started getting organized on that. Talk about a fun and challenging design space. Yowza.
23:31@giesse you are applying some function only if the predicate holds so... maybe apply-if?
greggirwin
23:43@nedzadarek none that I know of. :^) I have a few *-if funcs but normal FP langs will chain funcs. e.g. map filter ... in this case.
23:44apply is a good word, which we'll get in general form at some point.
giesse
01:10@nedzadarek apply is what I thought of first, but, I don't know if generalizing this to any number of arguments makes any sense, so I don't know. But, it may be the best name we have.
01:11@greggirwin but map filter ... would filter out the values that don't match, no?
11:28> @nedzadarek none that I know of. :^) I have a few *-if funcs but normal FP langs will chain funcs. e.g. map filter ... in this case.
@greggirwin yes, chaining or using HOF is what I have been thinking about.
@giesse > generalizing this to any number of arguments makes any sense
If you mean - a HOF with 1 predicate, - list of values and - one "argument function"
then map instead of apply (so map-if like @greggirwin said) would be better. However, if you mean many predicates and/or many "argument functions" then it gets complicated. If there would be only one version of that HOF then we can come with some nice names. However if you want many version then we need to distinguish one from other. [The Factor's naming conventions](https://docs.factorcode.org/content/article-dataflow-combinators.html) might be helpful.
11:43> I don't like either allowing any values.. It may work in the pick situation, but may
@Oldes in my opinion either with any values would be readable. @toomasv I'm not sure if if should return none! or unset!. Both options have something "nice". I would add default case:
if': func [cond tv /default default-value][
either tv: if cond [:tv][either block? :tv [do tv][:tv]][either default [default-value][exit] ]
]
v1: if' false 42
; *** Script Error: v1: needs a value
; *** Where: v1
; *** Stack:
v2: if'/default false 42 1000
; 1000
draegtun
12:35@giesse @greggirwin - Using QUOTE-ing offers consistency, so no need for variations of IF, EITHER, CASE, etc
19:16@nedzadarek I'm only concerned with "how do we deal with the repetition in a relatively common case of either block? :x [do x] [:x]?" - therefore, there would be only one input value and the applied function would take only one argument. If we generalize too much, then we have to start asking what happens in all the other cases and I'm not sure that has enough practical usefulness.
19:17@nedzadarek what's the difference between if'/default and either'? :)
19:18@draegtun blocks are already un-evaluated by default. The non-quoted version would be paren!. I don't find that kind of "quoting" to be a sane solution, sorry.
20:14Also this "quoting" (paren!s) does help with complex COMPOSE contortions :)
nedzadarek
20:31@giesse > @nedzadarek what's the difference between if'/default and either'? :)
either' evaluates its false-block. My if'/default doesn't evaluate default value. It's very similar - you can achieve the same things with little change. It's just for some cases if is more readable than either.
> "how do we deal with the repetition in a relatively common case of either block? :x [do x] [:x]?"
In my opinion, some kind of [function composition](https://en.wikipedia.org/wiki/Function_composition) and/or [tacit programming](https://en.wikipedia.org/wiki/Tacit_programming) would be good for such problems. ps. in my opinion, it shouldn't be too complex as it would make code less readable.
20:34For bigger code I prefer to separate into lines and add some spaces/indentation:
21:27Quoting, to prevent evaluation, should be the rare exception, same as lit args. We have blocks, we are unevaluated by default, and funcs that evaluate them because that's the most useful thing to do *for those functions*.
We don't want to be more Lispy. Lit-word syntax is specific to words, not other values.
What we need to look at are real-world use cases, where you want to prevent evaluation, and compare those.
On compose and parens, that's indeed a tricky combination to make elegant. Ladislav Mecir came up with a func that used a couple keywords to control composition. He called it build, and I've thinkered on it quite a bit, calling it inject in my version (no Smalltalk naming conflict notes needed).
21:38@nedzadarek nothing in the Factor naming looks helpful to me. What am I missing?
nedzadarek
23:12@greggirwin The Factor has variants of the functions. For example, you have bi ( x p q ), 2bi( x y p q ) and 3bi ( x y z p q ). bi applies value x to p and q (something like p x and q x in the Red). 2bi applies x & y to p & q(p x y and q x y). 3bi applies x, y & z to the p & q (p x y z and q x y z). There are bi*( x y p q ) and 2bi* ( w x y z p q ). * signifies that instead of taking all input's values it applies nth input to the nth function. bi* applies p to x and q to y. 2bi* - applies p to w and x, then applies q to y and z. So, if someone want to make some variants of existing functions he/she can suffix/prefix words with something. The factor have done it a lot so someone might find similar case.
23:15about compose/reduce -> wouldn't a planned templating system makes it easy?
23:18ps. I had made my function with syntax like this foo [(1 + 2)__evaluate-this__ (1 + 2)] -> [(1 + 2) 3]
greggirwin
04:40Some things can definitely be done with elements in my format experiment. And compose is worst when parens are involved, which I haven't run into very often, so it's not a critical path item.
04:44I don't think I missed anything in Factor then. It doesn't strike me (as an outsider) as very human friendly. I have the same feeling about Erlang's calling syntax, though I imagine it feels natural once you're steeped in either language and do it daily. So I can't say it's a bad thing, just that they are constructs fitted for their host language, which may not fit well in Red. e.g., in Red, we would probably not create similarly named functions, but add refinements, or use a block for variable arity application, which lets the system figure out the details, and avoids calls going bad when you change the args or the function call name out of sync with each other.
giesse
06:43@draegtun I find this to be a case of "everything is a nail" syndrome. compose is not the right tool for the job in a lot of cases; we should create better tools instead of building another layer of complexity so we can just keep using compose out of its scope of usefulness. I'm not opposed to syntactic sugar in principle, but sugar is way more harmful than most people think. ;)
06:44@nedzadarek I think that R1 had if/else instead of either... I don't think anybody missed it. :P
>> ? if
USAGE:
IF condition then-block /else else-block
nedzadarek
12:06@greggirwin yes, the Factor (or [Concatenative programming language](https://en.wikipedia.org/wiki/Concatenative_programming_language) in general) is very different language so, as you said, we cannot blindly copy their conventions.
@giesse I haven't done any if/else in the Rebol but in general the Red/Rebol have "a small problem" with the order of the refinement/argument(s). So better wording like either is a good thing.
dockimbel
12:41@giesse > I find this to be a case of "everything is a nail" syndrome. compose is not the right tool for the job in a lot of cases; we should create better tools instead of building another layer of complexity so we can just keep using compose out of its scope of usefulness.
Exactly. Another function for selective evaluation is clearly a simpler option than resorting to new esoteric lexical forms.
greggirwin
14:54I was just going to say that @giesse's comment was very well said, and saw Nenad's comment. :^)
dockimbel
15:23@greggirwin Do you have a link to Ladislav's build function?
greggirwin
15:39This is my adaptation of it, with commentary: https://gist.github.com/greggirwin/29836d25de0c68eaba0e6dbd268a20f5
His original isn't online, but I can find it here and send it if you want.
16:26Googling I have found following (Redbol unrelated) article on Ladislav, related to Bitcoin :-) https://ethereumworldnews.com/ladislav-mecir-57-years-editor-bitcoin-wikipedia/
greggirwin
16:28That's great. But calling him "tech savvy" ...a bit of an understatement. :^)
pekr
16:33I have found an archived link to his Bindology article ( http://web.archive.org/web/20150218034208/http://www.rebol.net/wiki/Bindology), but not a Build function yet. Maybe @rebolek will have something in his archive?
dockimbel
19:37@pekr Thanks for the link about Ladislav. I didn't know he went that deep into that topic.
rebolek
19:48@pekr I'm surprised, but I do! I'll upload it in a minute.
21:29@nedzadarek the problem you mention is the reason why I went with a "weird" function call syntax in Topaz. It requires a lot of discipline to write good functions otherwise. (And, some of the built-ins are not great to that regard.)
21:35Of note, I've written a number of variations of this over the years: https://giesse.github.io/rebol-power-mezz/dialects/emit.html I do want to write a version for Red that I will be happy with, that will be compiled (so any performance related objection can be put aside), and that might also encompass format (in fact, it could just be called format in the end). It's getting close to the top of my list. :)
nedzadarek
23:26@giesse > "weird" function call syntax in Topaz
I think it looks normal. Or I'm looking at something different.
Passing map or named arguments would be nice.
giesse
01:34@nedzadarek see the comments here: https://github.com/giesse/Project-SnowBall/blob/master/topaz/types/function.topaz
01:38note that there is no refinement! type, and only logic! options are valid using a path! syntax like in REBOL and Red.
nedzadarek
22:57@giesse So, compared to the Red/Rebol refinement!s (to be precise path!) are used for simple true/false flags but in order to pass non-mandatory argument you have to use "options syntax", right?
12:41I can use object! as a template for new one: o1: context [a: 1 b: 2] make o1 [a: 3] -> make object! [a: 3 b:2] That's not possible with map!. m1: make map! [a: 1 b: 2] make m1 [a: 3] -> #(a: 3) Is there some specific reason why this doesn't work? And if not, can it be added?
dockimbel
15:20@rebolek I guess you meant #(a: 3 b: 2) as the result. You can achieve that using extend copy m1 [a: 3]. I am not sure it would be a good idea to allow make to act in that way on maps, as it would just confuse more people about the nature of maps vs objects wrt inheritance.
rebolek
15:53@dockimbel Thanks, extend is fine, I guess, I just forget about it :)
greggirwin
16:43Objects have always been a special case, and my gut reaction was that maps should not extend the prototype value when make is used. However, we also have construct for objects, with then requires /with to use a prototype, so it's not nearly as concise, and we don't have a better term than "construction syntax" ("serialized format" has come up in the past). I think Carl used that term to align with construct.
Another difference is that maps do *not* reduce their spec on creation. If we change that, and add map support to construct, you could still do both. Security is a big reason not to reduce by default, when you think of Red/Ren as JSON, where things get passed around. But if we allow objects, you're no safer. It comes down to understanding the rules. Being safe by default is a good thing though.
Consider use with config files, which Red is great for. something like:
test-mode?: on
buffer-size: (5 * 1048576) ; 5MB
Strings, words, numbers, all good. But logic values, which are very common in configs, will still be words if you use a map.
Time for some thinking.
rebolek
17:05@greggirwin construct converts standard words to logic values
greggirwin
17:06Yes, but doesn't work on maps. Thanks for clarifying though.
draegtun
14:06@nedzadarek - Yeah but it's still inefficient (visually and internally) because you need to provide two blocks each time :(
14:07@greggirwin - re: build.r - Yes I've used/played with Ladislav's build before. However i don't think it worked with R3 (just tested and no). So perhaps time to relook at build.r and port it.
re: inject naming - It's an OK name :) NB. Dan Ingalls on purpose made the collection methods "rhyme" in Smalltalk (inspired by a song IIRC). Hence - INJECT, COLLECT, REJECT, DETECT, SELECT !! Always good to have a sane naming policy :)
re: Feature wars link - I don't think I'm asking for some feature from another language to be added to Red. Carl added IF/ONLY & EITHER/ONLY to R3. So this is more of an alternative (and future) suggestion for a possible unification of LIT (apostrophe) usage. And I'm not the first to make this suggestion either - https://gitter.im/red/red?at=5bb52f4fe65a6343367bed7d
Anyway lets see how it pans out in Ren/C branch. In meantime EITHER', IF', CASE' solution seems good way to move forward (i already have a CHOOSE function which does what CASE' would do)
14:10@pekr et al - Reminder that Rebol DocBase wiki is also on Github here - https://github.com/revault/rebol-wiki/wiki
nedzadarek
15:40@draegtun > @nedzadarek - Yeah but it's still inefficient (visually and internally) because you need to provide two blocks each time :(
As for this:
case [
false [ [1 3 5 7] ]
true [ [2 4 6 8] ]
]
Visually, maybe... but typing 2 more characters makes case simpler. It's "one less case" to remember. It may be less efficient in storing data (I think you could make "lit-block" having the same memory as normal block!) but it's "one more type to check". And that's when you interpret the code but compiled code **could** make [[1 2 3]] or '[1 2 3] into the same thing: [1 2 3].
15:41ps. next time quote the message, I don't remember things from few days before.
Pebaz
19:29I have a question about how Red works: How does print know that "Hello World!" belongs to length? and not the second argument to print? Example:
print length? "Hello World!" ;; Prints 12
Without digging through the source, I am inclined to think that this is because of Red being interpreted (meaning it can recursively find out which arguments belong to which function call). But when you compile Red, this can't be the case since it would need to be known which arguments belong to which function at compile time. Please enlighten me! :)
print has only one argument, and, in general, all functions have fixed arity, which can be optionally extended with refinements.
Pebaz
19:36That makes so much more sense! How does this work at compile time? Does the parser perform an initial pass on the ast (after it has been parsed) to pair functions with arguments (since it knows the built-in ones)? If so, how does it know how to treat a user-defined function? Wouldn't it have to evaluate the definition of that function in order to find out how many arguments it needs (as well as refinements)?
9214
19:43AFAIK compiler doesn't use any internal AST, and operates directly on loaded block of values (CST). Arity of any function can be inferred from its spec, e.g.:
arity-of: function [
'function [word! path!]
/local match
][
clean: [
any [remove [quote return: | not [any-word! | refinement!] skip] | skip] [fail]
| (table: make map! length? spec)
]
main: [copy match any any-word! (table/0: length? match)]
extra: [
any [
copy match [refinement! any any-word!](
unless /local == match/1 [
extend table reduce [to word! match/1 length? next match]
]
)
]
]
spec: copy/deep spec-of get first to path! function
parse spec [clean main extra]
either word? function [table/0][
arity: 0
add table/0 foreach refinement next function [
arity: arity + table/:refinement
]
]
]
Red compiler has the same functionality (see [here](https://github.com/red/red/blob/master/compiler.r#L1294)).
dockimbel
19:46@Pebaz The Red compiler does a single pass, and generates code on-the-fly. The compiler starts with a very small number of predefined intrinsics functions (handled internally by the compiler). Then it "learns" about the natives, actions and user-defined functions as it processes the standard library and user code. Functions arity being fixed, it can then generate the right calls, starting from nested expressions.
Pebaz
19:52This is fascinating. Thank you @9214 and @dockimbel for the explanation!
draegtun
09:41@nedzadarek > It may be less efficient in storing data (I think you could make "lit-block" having the same memory as normal block!) but it's "one more type to check". And that's when you interpret the code but compiled code **could** make [[1 2 3]] or '[1 2 3] into the same thing: [1 2 3].
Yes it would be interesting to see how it could be implemented in Red. I believe Moliad said he had engineers working on an implementation (experimental branch).
NB. Unfortunately i can't find (Moliad's) post or my replies to it on Gitter search :( So may have mixed up my recollection of it! What i can quote from Ren/C is... *"It's Faster and More Efficient - Quoting of up to three levels can be done a cell in place. So '[x] costs less storage (and has better locality with the surrounding cells) than [[x]]. Outside of the reduced storage, it's also lighter on the evaluator.".* So seems to be a win-win solution thus far.
Oldes
09:59@draegtun imho there is no win-win solution. And maybe I have too old Ren-C version, but in my version it does not work:
10:03Not to mention, that I don't like this in Ren-C (but I don't have the genial mind like HF, so it could be my fault):
>> type of first ['[1] '2]
== 'block!
>> type of second ['[1] '2]
== 'integer!
>> type of third ['[1] '2 3]
== integer!
rebolek
10:25@Oldes Don't worry, he'll change it next month anyway, so you don't need to care about it.
nedzadarek
11:10@draegtun First, what may works for Ren/C may not work for the Red. Secondly, it may be faster and have less storage but, in general, when you are introducing new datatype (2 if you want lit-paren!) you need to consider few things (I don't remember conversation about it).
If you think it's worth to introduce such datatype(s), maybe you should make a [proposal](https://github.com/red/rep).
Oldes
11:15@nedzadarek actually HF removed all lit-* datatypes and replaced them with something, which don't have a name (probably) as everything may be _lited_ in Ren-C.
nedzadarek
11:33@Oldes interestign but not sure where things like *lited* integer could be used... but the red/red is not place to talk about it... I guess.
giesse
19:15Programmers like Rube-Goldberg machines, and making everything bigger and more complicated, with more rules and more exceptions, because it's cool.
greggirwin
19:53I had a large, complicated response written. :^)
03:49It was syntactically correct, but the semantics may not have led to the desired result.
draegtun
13:03@Oldes - SWITCH is a different beast in Ren/C. Not fully on-board with this change to SWITCH at the moment but If SWITCH returned to Rebol2/3 semantics then your example would work.
13:03@nedzadarek >If you think it's worth to introduce such datatype(s), maybe you should make a proposal.
Actually I don't think it should be added to Red (at this time). But i'm happy that there are people experimenting on this.
13:04@nedzadarek >interestign but not sure where things like lited integer could be used
Can be useful in PARSE...
>> did parse [1 2] ['1 '2]
== true
Also there was an earlier example i gave with EITHER. However I'd prefer to use PICK there. Interesting this whole thread came about because of Gregg's dislike for using LOGIC! with PICK.
16:04Here's a question on '1 vs quote 1. How many times have you used it in real world code, and what are the use cases where it happened? I believe I've had exactly one use case, in almost 20 years of Redboling. And that was in R2, where parse didn't even support quote, and it was still not horrible to work around.
Oldes
17:27@greggirwin I'm not advocating this change, but it is for example used in replace/deep [tests](https://github.com/red/red/blob/master/tests/source/units/replace-test.red#L34-L39). I hardly remember I needed anything like that imho.
greggirwin
17:34Which is pretty much the same issue I had, in wanting to allow integers in templates used by a parse-based function.
In this case, it seems like replace should handle that automatically. If pattern is an integer, it should escape it.
17:34If others agree, we can open a ticket for that.
hiiamboris
17:47I'd separate /deep from replace-by-parse-pattern totally (using a separate refinement for the latter). This behavior is also not at all clear from the replace description.
dockimbel
18:33@hiiamboris The Parse rules mode needs to be more explicit, I agree.
18:39I think we need a general templating model for (dialects) code construction, using a new function along the lines of Ladislav's build.
hiiamboris
18:54I'll leave a note in replace-related REP then.
greggirwin
18:57It's tricky, because we want to allow parse rules, but also not imply that parse is *not* used otherwise, because that leaks implementation details. It's a separate issue from /deep.
hiiamboris
19:00Just /rule refinement if pattern is a rule, and compare it as it is otherwise.
20:13@greggirwin :point_up: [June 7, 2019 6:04 PM](https://gitter.im/red/red?at=5cfa8b20481ef4167be7ce5d) I couldn't find the code but I remember when I've been collecting some data that I wanted to put it into an object. I've been keeping both data and quoted code. I don't remember more details. I'm sorry. I don't remember any other serious code needing this.
12:30Hi, to some extent I followed some guides on building interpreter for LISP/Scheme, but I dont know how to build an interpreter for Red lang, for learning purpose I want to build a one, from where I can start?
12:36@greenmughal let's move to the [help room](https://gitter.im/red/help) as it's little off topic... I guess.
9214
12:58@greenmughal start by [learning the language itself](https://github.com/red/red/wiki/[LINKS]-Learning-resources) and understanding its fundamental pieces: values, datatypes, series, binding, homoiconicity, load and do phases, dialects; even though Red has some similarities with Lisp family, its design is fairly unique and deserves a thorough study.
Then dig through the sources and learn about internal data representation, cell layout, memory allocation, datatypes API, etc. I recommend to start with early versions (e.g. [0.3.2](https://github.com/red/red/tree/v0.3.2/red), which contains the first version of interpreter), for simplicity. Aim at a minimal subset, say, integer!, word!, block! and object! datatypes and a few natives for control flow with arithmetic/logic operations, no garbage collection, ASCII encoding. To implement a robust lexer, I'd recommend to learn Parse dialect and study [lexical scanner](https://github.com/red/red/blob/master/environment/lexer.red) in the main branch. If you prefer C, then study [Rebol3 codebase](https://github.com/rebol/rebol).
If you have an advanced knowledge of Lisp, you can also study the first version of [Rebol compiler](https://github.com/akavel/sherman), written in Scheme.
16:18@9214, that's a great answer. We should wikify it as a first step for those who want to do the same as @greenmughal .
endo64
19:14@greggirwin @9214 I've created a wiki page [[HOWTO] Build an interpreter for Red lang](https://github.com/red/red/wiki/%5BHOWTO%5D-Build-an-interpreter-for-Red-lang)
09:15@greggirwin > Here's a question on '1 vs quote 1. How many times have you used it in real world code, and what are the use cases where it happened?
I use it quite regularly. The most common case is building PARSE rules to filter/munge/pull data from LOADable datafiles (so some of the fields are often numeric codes). Most times this is done dynamically / programmatically, but sometimes i do some initial data exploration via the console.
Oldes
15:12I've found, how to get the URL requests from Google! Normally in Red it is like this:
15:12@dockimbel is it possible to add this header setting by default?
15:15Btw... I think that Google's behaviour is buggy, because without this header setting, Google suppose that result must be encoded as ISO-8859-1 and some chars, which are not in this set, are simply missing.
16:26Even when you would accept the invalid encoding, you would get invalid chars in this data. That is it. One must pretend, that is using real browser these days.
qtxie
16:28@Oldes Thanks. I'll add it as default header.
greggirwin
18:06@Oldes likely not a mistake on Google's part. If you aren't using a browser, they aren't able to serve ads, so they don't want people doing that.
18:08The fail is, that they are serving corrupted data... I understand, that they want to serve different content to old or not compatible browsers, but missing chars is an issue... which probably not many people will notice;-)
19:07One other point - Google *does* specify the encoding that they are returning, even if they are leaving parts out, it could be regarded as intentional. There could also be a fix on the Red side which looks at the encoding from the header and translates it. I started trying to figure out how hard it would be to do that, but realized I would need to find some solid hours to make any headway. Anyway, it would probably add a bit of robustness to how the response is handled (in addition to asking for the desired encoding in the request).
19:13@dander the thing is, that when you do what you did (without requesting utf-8 as I proposed above), you will get missing chars... believe me, I was experimenting with it quite a lot. You are just not affected, as your result does not contain international chars.
19:16I believe that it is because when charset is not specified, than default was ISO-8859-1 in HTTP1.1 (I think it was relaxed later)
giesse
19:17@dander I think that what @Oldes means is that the result is not really valid for the charset they specify. In any case, if you want to play with charsets, you may want to look at https://giesse.github.io/rebol-power-mezz/mezz/text-encoding.html , or use a library like https://en.wikipedia.org/wiki/Iconv
Oldes
19:17That they don't care about charset when you have unknown _user-agent_ is different story.
giesse
19:18@Oldes I think they don't care _in general_, meaning, so long as the average person can see their ads why do they care if it's technically correct or not.
19:20this is also why parsing HTML is such a pain, the stuff you find out there is totally insane. "it works in the browser" so it's fine to whoever put it together.
dander
19:21@Oldes I believe you, and I'm not arguing against using those headers in the request. I think both approaches are probably appropriate. @giesse the other option wouldn't really fix the problem by itself (which @Oldes suggestion does). But it would allow Red to properly handle the garbage Google sends back. Even if it is garbage, it seems like it's still better to be able to decode it than throw an error
Oldes
19:23The fix is, that @qtxie will add above request header values into default requests.
giesse
19:23@dander of course. My code linked above would replace invalid chars with a ? if I recall correctly.
16:50thank you very much! sorry for not actually looking into it - I've seen "simple mark&sweep gc implemented" announcement and have drawn conclusions I shouldn't have drawn
dockimbel
17:08@raster-bar No worries, we need to document the current GC properly in the wiki or in a blog article.
planetsizecpu
17:20I would like to ask the team for some code in my game script, I'm not comfortable by the ways I feel it maybe unsecure and not so proper, that is running code in object's prototype definition, such as: set 'o object [a: 1 b: 2 c: 0 if a < b [c: a + b]] It is clear it works, but rules may change?
9214
18:18Object's body is bound to a freshly created context and evaluated in it, this is pretty much the intended behavior. If you're uncomfortable with that, use construct, which was specifically created with security concerns in mind.
planetsizecpu
19:38Thx @9214 I will test construct next week to see how differs
dockimbel
18:44FYI, ARM backend has been fixed, all the unit tests are passing again (on armhf, we need to find an armsf platform to test the soft-float mode).
pekr
19:22Quite a lot of work on an ARM backend. Was that caused by the ARM distros moving forward, or just Red strenghtening its ARM support in general?
GiuseppeChillemi
19:28Would like a lot an advancement in the android version...
Respectech
20:21@dockimbel I believe the early versions of the Raspberry Pi were armsf (armel). https://www.raspberrypi.org/forums/viewtopic.php?p=987258
dockimbel
22:28@pekr Bug fixes and improvements to ARM backend. The ARM tests were not passing since many months due to many different issues, some related to the CI testing environment, some related to the increased usage of OS using armhf ABI (hard floats using the onboard FPU).
22:28@GiuseppeChillemi Android runs on the ARM backend.
22:29@Respectech Yes, the early Raspians are armel, not sure about the latest ones. We have several RPi boards here, I'll see tomorrow if I can set up an armel one.
22:38@Respectech BTW, do you know where to find a comprehensive list of the GPIO memory addresses for RPi2/3? I have looked into the WiringPi source code, but couldn't find an exhaustive list. I remember seeing a few years ago, a C include file for a Python module that contained all the relevant addresses with some docs, but can't find it anymore.
05:44@dockimbel > @Respectech Yes, the early Raspians are armel, not sure about the latest ones. We have several RPi boards here, I'll see tomorrow if I can set up an armel one.
As I understand, only the initial release of Raspberry Pis will run ARMel versions of Raspbian. I have a "first" run Model A on which I can run a version of Raspbian that uses ARMel.
05:53I can't find the link from where you can download a copy of the correct version of Raspbian so I've sent you a copy of the contents of the SD card that I use.
rebolek
06:25@dockimbel I have old Synology USB station 2, which uses Marvell 88F6180 (ARMv5TE) and I believe it may be soft-float ARM.
dockimbel
08:48@rebolek Nice, reminds me of my good old [SheevaPlug](https://en.wikipedia.org/wiki/SheevaPlug) I have bricked after first commits for ARM backend.
08:54@RnBrgn Thanks, that's a good start, though I understand (maybe incorrectly) that the GPIO addresses are remapped by the RPi differently in RPi 1 vs 2/3. So I also need the base address used for all RPi variants if static or a way to discover it dynamically.
rebolek
08:57@dockimbel I'll give it a try and let you know about results. It's useless currently, but with Red running on it, I can certainly find some purpose for it :)
Respectech
20:18@dockimbel If you need a Raspberry Pi 1, I have a few around that I could send you.
20:19@dockimbel I don't know if this helps, but in case it does: https://bob.cs.sonoma.edu/IntroCompOrg-RPi/sec-gpio-mem.html
dockimbel
20:51@Respectech Thanks Bo, we do have a RPi 1, 2 and 3 at the office here.
20:55@Respectech Very informative, thank you very much!
20:57I will make a R/S (and eventually Red) prototype in the next days for GPIO access. I have a few LEDs and sensors I need to try.
pekr
04:36Just curious - where's the Arudion ecosystem nowadays? I mean - are there still 8-bit, 16-bit, 32-bit options, or mostly 32-bit nowadays? And is there a chance Red (R/S), e.g. with its planned /Pro version, would support such targets with some kind of reduced functionality, e.g.?
greggirwin
04:50We had some private chat about that today. It's a low priority, with a couple ways to go about it.
dockimbel
15:42I would to hear the ideas about solving the notoriously complex overflow detection issue for system programming languages (R/S in this case). Here is how it currently works per target: https://github.com/red/red/wiki/Red-System-Overflow-handling
15:43As you can see, each CPU behaves differently, so the question is how to provide a consistent cross-platform behavior without hurting performances?
15:45Adding soft-checking just for division overflow on ARMv7+ costs quite a lot:
16:02Side note: the EQ condition on last 3 lines is not needed, just a left-over from copy-pasting code from division routine.
CodingFiend_twitter
17:32I used Modula-2 for years, it is very similar to Red/System in that it was a replacement for assembler. It had range checks, divide overflow checks, nil pointer checks, etc., all the things that just killed you in C. Adding all the runtime checks puffed up the final .EXE by about 30%; but a godsend during testing. I only turned them off at the very end for shipment of a final product. So i recommend you add a compiler pragma(s) for these checks, because there is no way even the same project would want it only one way.
dockimbel
17:35@CodingFiend_twitter Thanks for the feedback. One option we are considering is activating all the possible math checks generation when compiling in debug mode only.
CodingFiend_twitter
17:36In modula-2, there was a project build flag set in the IDE to turn it on or off globally, and there were pragmas to turn it on and off in a small range. Around selected performance critical loops, one might turn off runtime checks if one has confidence in the data, and to let the runtime checks be on for the regular less critical code. Many projects are more concerned with overall reliability than sheer performance. Most business products are not performance sensitive; after all most computers are idle 98% of the time, but when you do care, you care a lot about speed. The whole point is avoid assembler, because assembler takes 10x human precision of pretty much any high level language (which Red/System is IMHO)
9214
18:11@dockimbel perhaps you can utilize recently added #inline directive and create a dedicated macro which will inline overflow checking prolog at expansion site?
dockimbel
18:46@9214 Generating checks is not the issue, it's more about what the default behavior should be. Though, we could provide a pre-check system call as we do for post-checks. But again, you have to remember which math op requires a pre-check and which one a post-check...
9214
19:23Maybe you can provide pre/post condition check system (which can be generalized to invariant-based programming I guess), and then automagically insert such checks for math operators in debug mode? So, either one uses debug mode and everything is automated, or manually (and optionally) uses provided invariant system. Something like a micro-dialect embeded in R/S.
Or, if such system is too general, make it optional for math operators only via flag in R/S header; debug mode will set it automatically.
CodingFiend_twitter
19:24during development, one would normally prefer to have all possible checks running. For the "golden master" version one would typically turn off the checks. So you just gotta make it easy to toggle all of the checks with one click / pragma. Runtime checks is rather related to the target; you specify you want to emit a .EXE, and you say what set of runtime checks the compiler should emit. You might even consider having a preference file if you have so many. In many IDE's these checks are a big list, and i would imagine they should be off by default. Mean spirited people will be looking for the slightest flaw in Red, so let by default the early users marvel at the tiny executables, and more experienced people will be very glad to turn these on because it helps catch errors earlier.
19:26The more checks you can do pre-op and post-op the better. When I am debugging i would prefer the computer to give me all the help it can. Programming as a profession today requires superhuman levels of patience, and frankly there are lot of people with great ideas for improving life who can't build a product because the process is so frustrating for them.
dander
19:41This may be a naive question, but when the compiler moves to Red, would it be much of a step to also have a Red/System interpreter so that things could be tested without needing to compile, and errors caught at Red level?
dockimbel
19:47@dander We could write a R/S interpreter right now in Red, it's not dependent on the toolchain.
dander
19:49That's cool! I just thought they might share some components
dockimbel
19:50The linker would need to retrofit in reachable place of the executable, a full list of internal runtime library functions with specs and entry points, so you could call them from the interpreted R/S. Beyond that, I don't see any special dependency on the toolchain.
19:54@9214 It's really a low-level issue, basically, it boils down to what should x / 0 and -2147483648 / -1 do?
20:10The systematic (or not) low-level overflow checking is the other question to solve. It would make sense to have it all enabled in debug mode, but that could also cause a different behavior than in release mode, potentially generating heisenbugs...(the kind of bug you really don't want to have). So maybe forcing an exception with an exit on overflows could be a preferable way in debug mode.
9214
01:48@dockimbel right, I got carried away :neckbeard:
LucianU
11:59can you develop GUI apps in red in the style of the elm architecture? by this I mean having the state in a single place and functions just define the way to display the state
12:09ok, I found this https://doc.red-lang.org/en/reactivity.html
dockimbel
14:17FYI, we have split the ARM target on Travis (our CI backend) in ARMel (soft-float) and ARMhf (hard-float) targets, so we now have more badges to display on red/red home page:
07:04@luis-rj ARM is supported by Linux and that means only experimental GTK branch. However that branch is very usable and therefore it's possible to run View on hardware like rPi.
Updated web site for the Rebol [2019] developer conference. Includes some info on the talks, speakers and location and a link to the event registration. Be sure to register as soon as you can so I can get a close-to-accurate head count ahead of time.
Also on the registration site, I'm accepting donations to help offset some of the costs (it's unlikely registrations alone will cover everything--I've deliberately kept the registration fee down to encourage wider participation).
At this time, there is help available if accommodation is still needed. Just drop me a line.
Only a week away now, hope to see you there!
GiuseppeChillemi
12:44@rgchris do you accept donations via paypal ?
rgchris
23:34I can take them personally. I'll send you information in a few (I have your email from the pre-reg site. Thanks!
pekr
16:17wohooo - Red June update :-) https://www.red-lang.org/2019/06/june-2019-update.html
19:06Excellent! Cross-compilation from 32-bit platform to 64-bit by end of the year…. This is a lovely piece of news!
GaryMiller
19:14Is there an expected compiler speedup with that release too?
dander
19:22Thanks so much for the update 😁. Is console plugin support scheduled for any particular release?
9214
19:24@GaryMiller you're confusing Red/Pro and community version of the toolchain. The former will offer 64-bit support and optimized compiler, the latter requires some changes in existing codebase (there are a few options on how to proceed with that), using the same monolithic compiler (so, no speedups).
19:25@dander no ETA yet, though @dockimbel might elaborate.
19:43@dockimbel great, thanks for that info! I am interested to see if it will be possible to incorporate some of @toomasv's experiments with syntax highlighting, incremental execution, and things like @rebolek's values editor
pekr
06:10Is loading libraries still planned for 0.6.5, as mentioned in the Trello cards?
dockimbel
10:02@pekr I doubt we can find the time for that addition in 0.6.5.
GaryMiller
15:58Any additional scrollbar control words like scroll to the bottom in 6.5? I was helpd on here with a work around but it does not work when the lines are too long an wrap.
dockimbel
16:09The current scroller widget implementation is not satisfying, we'll see if we can improve it in 0.6.5.
GiuseppeChillemi
18:32Nice work. I still don't understand if there will be an Ios version for RED.
20:59Fantastic news in June update! Most of the updates are in scope of my last projects - Wallet, C3, GTK, Android, even shadows :-) Can't wait to manage my security token written in C3 with own wallet written in View/VID under Linux and Android :-)
21:01I dream of having functionality similar to VSCode plugin on Sublime Text, it's so cool on screenshots.
21:13@loziniak Sublime Text seems to be supporting LSP, so the Red plugin for VSCode should work for Sublime too with minimum changes. @bitbegin What do you think?
21:46@loziniak We have it since a while. https://github.com/bitbegin/redlangserver/wiki/demo-for-sublime-text
loziniak
23:10thanks! there's a missing image link at the end of document, should be: https://raw.githubusercontent.com/bitbegin/redlangserver/d9e1286753c6b7b883b48e1dbbfdeae2557159e3/goto-def.png
> Gregg, It is only crucial to a developer - who needs that feature - the difference between the best and the rest. Sound is important
That doesn't tell me why you think it's important. It has nothing to do with skill. It has to do with what kinds of apps require or benefit from sound as a feature. With a clear target, we can define a better sound feature into Red.
justjenny
23:50Gregg, the apps that are going to advertise Red are the ones that need sound, i think
23:55games - trivia - even serious ones need sound - a simple but good app can be turned into a great one with sound.
Respectech
00:10I'll chime in here - I wrote a Ukrainian language tutorial in Rebol a while back, and I used the sound feature. However, I suffered from not having the feature to pause/stop/restart a sound (like a sentence spoken in a different language). Also, the work that @planetsizecpu has been doing on his game would benefit from sound, I'm sure.
00:10But in any case, I think it should be possible to do sound through OS APIs presently, is it not?
justjenny
00:13yes, there's a few ways to get sound, but an integral sound option would be better - I can say now without a doubt, that there would be Red apps in the Windows Store, if there was integral sound - and i am probably saying to much - but it is true.
greggirwin
00:20We agree that sound will be great to have, but it is not holding Red back *at this time*. For games, we need other things in place as well, to make it a smooth experience. But we don't think games are our ticket to success at this point. We've considered it, know that. We consider all options and weigh their viability. We look at trends and surveys, adoption and competition. Making Red succeed is our full time job.
justjenny
00:28Red is the best - but it's not just about games, that was just an example. - Graphics and Sound are king.
Not so. They are important in some contexts, but not in others (e.g. data processing). The key here, for any feature request, is to be specific and concrete when justifying them.
justjenny
00:34Sorry Gregg, yes - I am just seeing the commercial opportunity - Selling Red to the public.
greggirwin
00:35That's why I'm pressing you to be specific. *What* is the commercial opportunity?
00:36Games are the obvious one, but the challenge there is a saturated market for specialized tools.
00:36We can't compete there without also having smooth animation, a physics engine, and *great* assets (images and sound) for demos.
justjenny
00:43Even simple apps into the 'app stores' would be great - As long as it is clear that Red was used to develop the apps
topcheese
00:51Wouldn't it be better to add Red as another scripting option to an existing game engine like Godot? At least that's what I was looking to try some day.
justjenny
00:52Royalties for the simple apps can mount up to a lot - Free to use, but pay if they are commercial.
pekr
04:50Everybody might have different priorities. From my point of view, it is important to get ports/schemes (IO), including databases, data grid widget for at least basic data processing and/or the ability to create custom styles. So, e.g. from my perspective, Red's plans are already in-line with my expectations. Our needs might surely vary ....
justjenny
10:11yes, of course, I got a bit carried away last night, to much wine. everyone wants something more.
rebolek
10:23@pekr the priorities are not that different, as ports are needed for sound anyway.
raster-bar
14:28Sorry for my confusion, will there be a community 64-bit version of Red and Red/System?
greggirwin
15:02As noted in the blog, more info will come this summer.
20:58Money datatype is my priority but I don't see it mentioned. Someone told me to not use float for financial calculations but if there is no other solution I don't know how to safely handle financial data.
greggirwin
21:33There is an experimental money! implementation ready for review. We have some hard decisions to make in that regard, and it also ties to 64-bit in some ways.
07:48yep PORTS!!! again got it. 7 will be good number to wait. also money! too
PeterWAWood
09:18@viayuve I don't think that it has ever been planned to include a money! datatype in the 0.7.0 release.
viayuve
10:23I am sorry I mean Wait for money! and ports @PeterWAWood
10:27ports are in 7 and recently i needed money! so added that part last. I don't know in which version it will come with red.
GiuseppeChillemi
17:05Just another few questions on android version: will be it possible to access GPS position and access some kind of map visualization ?
17:05Also, is it possible to interface to some component to read barcodes ?
BuilderGuy1
19:35@GiuseppeChillemi Sounds like you want to talk to some Serial devices! Me too! I'm eagerly awaiting Serial so I can talk to some microcontroller boards.
20:54@BuilderGuy1 I improperly expressed my needing. I wish to access some software components which read barcodes using the built in camera.
Respectech
21:33Android already has keyboard apps that have a barcode reading button. It automatically reads the barcode and returns input as if it was typed on the soft keyboard.
21:33If you want to read it directly with Red, you will have to parse the image from the camera.
GiuseppeChillemi
22:46thanks, so I imagine it is an additional input method, isn't it ?
22:48I have found a difference between Rebol and RED:
REBOL
>> foreach [val] [a 'b] [probe val]
a
b
== b
>>
RED
>> foreach [val] [a 'b] [probe val]
a
'b
== 'b
I suppose REBOL is the wrong one and buggy....
beenotung
03:35is it possible to run red from browser? e.g. for building PWA?
I've been trying to translate a little word game for kids from Python to Red.
I think it's almost... but I cannot figure out how to conclude it. Here's my (sample) code until now:
col1: ["Away, you","Come, you","Thou","You poor"]
col2: ["peevish" "grizzled" "greasy" "jaded" "waggish" "purpled" "rank" "saucy" "vacant" "yeasty"]
out: [random/only col1 random/only col2]
;-- This is the piece of code that I cannot figure out how to complete
view [size 750x100 title "Shakespeare insults generator" button "Insult me!" [print out]]
;-- If I write it this way it will open the window and on clicking the button I'll get the output on the shall
;-- but not on the window
view [size 750x100 title "Shakespeare insults generator" button "Insult me!" text [print out]]
;-- If I write it this way...
view [size 750x100 title "Shakespeare insults generator" button "Insult me!" text out]
:-- ... or this way, the window opens, but I get no output either on the shell or on the window, and no error messages.
I went through Red GUI short introduction (by Alan Brack) and tried to adapt my code to his example 18, but I couldn't make it work either.
I have no idea how to show on the window the text that the variable "out" gets from the execution of the two random commands. :(
9214
16:52@manuelcaeiro putting aside the fact that col1 shouldn't contain any commas between string elements...
view [size 750x100 title "Shakespeare insults generator" below button "Insult me!" [phrase/text: form reduce out] phrase: text]
16:53FYI, we have a [dedicated chat room](https://gitter.im/red/help) where you can ask for help with your code.
endo64
17:05@manuelcaeiro Welcome! Have a look other rooms, https://gitter.im/red/home Especially wecolme and help rooms are good for beginners. For additional learning materials look at the wiki: https://github.com/red/red/wiki/%5BLINKS%5D-Unofficial-Tutorials-and-Resources https://github.com/red/red/wiki/%5BLINKS%5D-Learning-resources And for the GUI: https://github.com/red/red/wiki/%5BLINKS%5D-GUI-Programming
manuelcaeiro
17:08@9214 Thank you, Vladimir Vasilyev. Actually, col1 does not have any commas on the red console... I must have copied it from the python code. Thanks for the reference to the dedicated chat room. (Now I'll just have to figure out how to get the text in one line only... LOL)
> Now I'll just have to figure out how to get the text in one line only
Don't hesitate to ask for help here or in other rooms if you feel stuck.
manuelcaeiro
21:55@dockimbel Thank you, Nenad Rakocevik. @9214 You make me feel really welcome, Vladimir Vasilyev. As soon as I can I'm going to try using a function to get the random words from the different lists (you call them series, right?). I like always to try first solving the difficulties by myself, but if after that I'm still not able to produce the text in one line on the GUI I will gladly accept your invitation and ask again for help.
23:54Here is the final code for the view, testing on the console - it works fine:
view [size 750x100 title "Shakespeare insults generator for kids" below center button "Insult me!" [phrase/text: form rejoin out] phrase: text 725x35 bold font-size 16]
I have also tested it on a file. Tomorrow I'll complete the code on the file and compile it. Thank you for your help.
manuelcaeiro
00:07@justjenny Hi Jenny (author of Jenny's blog, mentioned on the unofficial docs) :) Well.. What can I say? Vladimir Vassilyev was nice this time, was he not? I trust you to keep an eye on him, okay?
justjenny
00:09Not sure what you mean @manuelcaeiro - tell me more ....
dockimbel
00:10@justjenny This group is moderated, please refrain from direct personal attacks, and stay on-topic.
justjenny
00:13@dockimbel nenad, I am not making any personal attacks - I am defending myself
00:17@dockimbel sorry - I am not happy about some things on here ....
00:23@manuelcaeiro so what are you saying - please be more clear ....
00:33@justjenny @manuelcaeiro You are off-topic. I remind you that you are on a technical discussion group that is moderated. Please behave appropriately.
justjenny
00:38@dockimbel @manuelcaeiro - nenad - apologies - but love it - and yes I know - wont do it again.
dockimbel
00:42@justjenny Thank you, apologies accepted. It's 2:40am here, I would very much like to go sleep after a long day. ;-)
21:36@justjenny (excuse me @dockimbel, I won't write this privately but also it will be my unique message) Vladimir problem is being honest and direct in a world which prefers lies and hypocrisy. If you feel upset from his comments read them twice, or more, as there are good reasons when he fires his messages. Behind his words move values like promoting good quality chats and keeping them on topic; defending RED from ignorance and misinformations; spreading knowledge. Also he spends lot of time and resources answering to newcomers and pointing to the to the correct documentation or writing it ! Like those old fashioned coaches he won't sugarcoat the pill, also he won't say "good" when he want to say "bad". Rather he will give you a "punch in the stomach message": something that could sound like a direct attack but it isn't as it contains the (aforementioned) values that move him. Personally, I have received his punches a couple of times too (and that was not easy). I have then tried to read under the sound direct words make and: when I found I had good reasons I have defended my opinions; otherwhise I have accepted his one. So please, teach yourself to concentrate on the message underlying direct words and not on the sound they make in your head. When you will be good at this task, you will find yourself having 2 new skills: 1) "discuss without attacking personally anyone even under emotional pressure" 2) "Do not spread bad words of anyone to defend your ideas". Then you will thank having meet him and also you have found one of the best teachers for RED inner secrets.
23:00@justjenny ask yourself which is your worst fear talking with him and why and and the tempest inside yourself will calm. Goodnight!
justjenny
23:05@GiuseppeChillemi fear - not sure what you mean ?
23:18If we call it Red Wine Carl Sassenrath will appear. (Ok, leaving!!!)
justjenny
23:50There are pro and community versions of Red coming - what are likely to be the difference - think most of us will opt for the pro version - but just wondering
greggirwin
02:42@justjenny more info will come in future blog posts. We're still nailing things down, and once we announce Red/pro for real, and what it means, we expect people will hold us to it. Hence, we want to be careful, and will say up front that we'll do our best, but may not decide on all feature differences day one.
raster-bar
11:39@greggirwin Is there any deadline for that announcement?
9214
11:48@raster-bar no hard numbers, as we want to tread lightly and manage other's expectations with utmost care. Although, Red/Pro is one of the top priorities this year, as stated in the [latest announcement](https://www.red-lang.org/2019/06/june-2019-update.html).
raster-bar
11:58@9214 Red/Pro is expected to be announced when it's released, right?
9214
12:01@raster-bar I believe there might be a pre-release announcement, but don't take my word on that, because plans may change. Per blog post (last section):
> We plan to give more information about each of those big new additions to the Red family this summer.
12:06@raster-bar not to worry at all! You're welcome.
18:44@/all we've just rolled out [new RED Wallet release](https://www.red-lang.org/2019/07/red-wallet-040.html), which includes BTC and ERC-20 token support, with updated firmware for hardware keys.
Binary grew up to ~500KB because of the necessity to store token list inside the app itself - sorry about the bloat :wink:
16:01@Oldes thanks for the reminder. I cleaned some things up.
dockimbel
21:31The [last-commit.red](https://github.com/red/code/blob/master/Showcase/last-commits.red) script is not working anymore as Github changed his API. Does anyone know if this is fixable? If not we could find another popular online service where to scrap+display a list, or else trash that code?
10:24@dander @giesse Thanks, will add that as a new showcase script! I want to keep the original one to show how two different declarative DSL can be mixed up together to achieve great expressivity.
10:42@dander I put your name as author if you don't mind: https://github.com/red/code/blob/master/Showcase/last-commits2.red
18:34@dander Accept it with happyness, it's an honor !
dander
18:40@GiuseppeChillemi I do feel that way :smile:, and I appreciate the recognition. I guess my response was a bit more terse than it needed to be. So easy to lose emotion in text
15:12Having a single native sound API would bring Red’s potential unleashed.
15:13End developers would be capable of developing such applications like music players, video games w/ sound effects, etc.
9214
16:10@OneITI37 we've discussed this at some point in [/audio](https://gitter.im/red/audio) room, and started a [preliminary research](https://github.com/red/red/wiki/%5BDOC%5D-Audio-R&D) on available options. Though, audio support is not a high priority right now, so, if you want to see it pre-1.0, you ought to take the initiative and start contributing.
10:03I would like to ask something about gpio:// Xy years back, when I have tested my BeagleBone, I have found following article ( http://chiragnagpal.com/examples.html ) discussing difference between the /sysfs(slow) vs the /dev/mem (faster) aproach to gpio. But the article is from 2012, so not sure the question, which version Red's gpio:// uses, is relevant here? Looking into code briefly I can see usage of /dev/gpiomem....
10:05My second question goes towards some other boards support. I am not asking for one, just looking into gpio:// scheme, it contains modelsblock, which seems to be devoted to RPi models only? So - could the scheme be extended to some other boards in future too, or are others boards like Odroid, Beagle, etc. so different, it will require a separate scheme? Thanks.
dockimbel
11:39@pekr Red' gpio:// relies on /dev/gpiomem which is a more specialized version of /dev/mem, so that's the fastest direct access you can get.
11:42For other boards support, if a command-line tool like WiringPi's gpio can control it properly, then our gpio:// scheme can too. Otherwise extra specific support needs to be added, contributors are welcome. ;-)
11:44For Odroid, it is [not clear](https://forum.odroid.com/viewtopic.php?t=29628) how much hardware-compatible it is with RPi, @Respectech would know better than me.
pekr
12:49Thanks for your answers! Well, theoretically, if those other boards don't differ too much, it could be abstracted to avoid something like gpio:// gpio-bbb://. etc. In theory modelsblock could be extended. While contributors are welcomed, myself not being a good coder - is there a chance we can still donate/sponsor and coordinate with Red team, to work on certain features, which would have a change of being added to the official distro?
12:52gpio:// went on as a big surprise to me - did not see it coming. Glad it comes though! IIRC, @Respectech did gpio:// for R3 and Odroid boards. So I am sure some other boards will come too ....
Respectech
03:04Odroid is pretty close to RPi as far as GPIO compatibility. But I've only ever tried using sysfs.
15:16I see that CGI is possible for Red according to the documentation. How does Red read the CGI environment? I need to do pass the same information to Rebol 2, but am not sure exactly how to do it. I need to "fake" a webserver.
Softknobs
15:28Hi. After fiddling with Red for a while I managed to get my first project with Red done. It's a PoC that brings Midi IN capabilities in a Red program using bindings to the RtMidi library. The source is available here: [RedRtMidiPoC] (https://github.com/Softknobs/RedRtMidiPoC) Midi In is in my opinion the most difficult to handle since it requires the use of callback functions. I may expand this with Midi out at a later time. RtMidi binaries are provided for Windows and MacOS. Thanks to the Red community who answered my questions when I needed it!
13:37@greggirwin it's very simple. set up environment variables in your DOS shell that have the same names as these: http://www.zytrax.com/tech/web/env_var.htm. If you then start REBOL -cs in the same shell, system/options/cgi should automatically pick them up.
13:37I've been told also that one should not use rebol --cgi, but rather rebol -cs.
dockimbel
18:12FYI, the port-type branch was merged into master. It features the new port! type, but no additional IO or networking code. It was merged to master to facilitate the usage of two already implemented schemes: gpio:// and eth://.
18:49After I downloaded the newest exe, I observe that system/schemes is empty, and that open eth:// crashes... What is going on?
greggirwin
18:58Work is in progress, after the merge. eth:// has some special needs, and is also being updated to use the now-standard JSON codec.
dockimbel
19:31@meijeru GPIO scheme is not compiled by default yet. You can include it manually in your apps. For eth://, it is not released yet. BTW, I don't get any crash here on open eth:// from the console, just an error.
pekr
19:32what is eth:// supposed to do, send raw packets?
dockimbel
19:32@pekr No, interact with the Ethereum network.
pekr
19:33ah, that one. Too much spoiled by eth being an abbreviation for ethernet, sorry then, thought we went down to ethernet layer somehow :-)
15:07By the way, the current gpio-scheme exposes some more functions than only the operations defined as allowed on ports (I/O + series actions). Would there be a possibility of hiding these for the (clever) user?
That said, we can make things harder to access, to frustrate clever people, but that may also punish normal users, by making things more difficult to do, or for the author, who has to do extra work. But, ultimately, we can't make it impossible at the primary language level(s). A dialect could be written to do that though.
What we want to support, for those who need it, is more control that lets you specify intent and constraints such that the extra work done adds value, and acts as design documentation.
12:28@toomasv Excellent as usual and this time nothing to change to have it working on Linux.
toomasv
12:31Thanks @x8x , @rcqls ! Did you get it with red dot moving? I noticed that one recent change fixed red dot in center. Now corrected. Bravo for RedGTK!
rcqls
12:33@toomasv The same as your animation, the red dot is following the mouse.
12:38The only difference between Linux and macOS is that something happen on macOS even when mouse is out of the window. In linux, there is no change when the mouse is outside.
toomasv
12:41On Windows, when mouse moves out of the window, it recieves wrong coordinates. Seems to be connected to the coordinates of window, but negated, at least one dim. Thus it shows weird lighting (also in above demo).
13:06.05 is not good too! That's funny .08 is not perfect and indeed .09 seems to be perfect. I guess this cutoff could depend on the geometry of the lines....
toomasv
13:15I tried up to .0819, which still seems to be good. It is somehow connected to resolution between angles with difference in degrees smaller than that. If smaller then sorting goes nuts.
13:37Upgraded to [radial gradient light](https://toomasv.red/images/Animations/rays2.gif).
18:06Those numeric step notes would be good to note for testing and understanding.
teamtad_twitter
11:40I am trying to make a parser to convert some Prolog type code into another language. I am not very good at Parse; so I am trying out some baby steps. Can someone help me here? I am getting stuck at parsing something that could be a variable or a value. A variable is something that starts with a capital letter (upper case letter) and a value could be a number (like 1 or 1.5 or 2. ) or a string delimited by quotes e.g. "This is a string" I am getting stuck at parsing the string. Here is part of the parse rules
caps: charset [#"A" - #"Z"]
lowerc: charset[#"a" - #"z"]
letters: charset [#"A" - #"Z" #"a" - #"z"]
digit: charset "0123456789"
special: charset [#"_" #"-"]
ws: charset reduce [space tab cr lf]
chars: union union letters special digit
sentenceChar: union union chars ws charset "~!@#$%^&*()<>?/{}[]+="
sentence: [some sentenceChar]
anumber: [ some digit "." some digit
| some digit "."
| some digit
]
quote: {"}
variable: [
quote any ws sentence any ws quote
|
anumber
|
caps any chars
]
parse "Vaa" variable
(true)
parse "1.5" variable
(true)
parse "1" variable
(true)
...
but
parse {"This is a string"} variable
is false!
toomasv
12:51@teamtad_twitter quote is not suitable for a "var" because it is part of parse DSL and gets bound to special value despite your initial setting. Use something different, like quot or quote* ...
Consider this:
>> parse {"This is a string"} [quote #"^"" some sentenceChar quote #"^""]
== true
Although quote is not needed here. It is (usually?) used to match integers in block parsing.
16:23@toomasv quote is not bound, it's just treated differently inside Parse block. You can bind quote to whatever you want but it still will be recognized as a keyword which uses any value that follows it literally for matching input.
@teamtad_twitter FYI, Red has dbl-quote alias for " character.
07:03Hi, how do i capture key events for alt-down + Up and alt-down + down keys. In on-key, event/key only returns arrow keystrokes like up and down not alt or ctrl.
08:17event/flags returns empty string when alt key down is pressed simultaneously with up or down key. if alt key is pressed without any other key press, event/flags returns left-alt as value.
planetsizecpu
11:30@Softknobs MIDI will be a great step for the RED language, good job @ldci enjoy your break @TheRedTeam Good job on GPIO much encouragement @toomasv how interesting! It seems that you found the light, don't loose the focus and push hard
Here the cave is closed for this month, I hope to bring some news in September, mostly debugging some unwanted behaviors I noticed on the guards.
16:44Instead it is the correct one, as for a moment I thought I was making a mistake. 😉
greggirwin
17:43Why do you need to load a block? It's already Red values.
GiuseppeChillemi
19:22Gregg I have encountered that needing a couple of times but I don't remember the exact scenario. REBOL accepts any-block while RED does not, my curiosity triggered.
nholland94_gitlab
02:36Does RED support modules like in REBOL 3? If not, is there any other mechanism for limiting what values in a file are public?
09:53You can close content of the file in a context.
09:59Like for example [here](https://github.com/red/code/blob/f1bdba918ddd6c6107525e4d5bb7f302ed7e80f8/Library/Bass/bass.red#L796)
Oldes
08:12@nholland94_gitlab here is [another context like example](https://github.com/rgchris/Scripts/blob/master/red/clean.red). And I also like how @rgchris sometimes replaces the context to make it inaccessible like in [this script](https://github.com/rgchris/Scripts/blob/master/red/form-date.red)
meijeru
08:41With all due respect, the publicity that says "Red is 1MB" is becoming less truthful (currently it is 1.19 MB). Does anyone have a phrase to propose that is more truthful and still catchy?
10:16Does anyone use those still? They are no longer produced...
9214
10:23A bar graph with toolchain size comparison would be more informative and impressive (e.g. Red vs. Visual Studio); also pie chart with ratios of features (i.e. "our native cross-platform GUI engine takes X of total size").
pekr
12:04In 80ties, it would still fit on your disk. I can't see a problem with 1 vs 1.18MB claim. Still lives in a territory of cca 1MB size ....
15:18@9214 if you'd try to draw such a bar chart Red wouldn't even be visible on it :)
9214
15:22@TheHowdy_gitlab well, one can use a logaritmic scale (@BeardPower you hear that right?).
BeardPower
15:25@9214 Noted. I will look into some charts. The wallet comparison worked out with a linear scale.
TheHowdy_gitlab
15:25@9214 But should we? Or would that make Red unnecessarily big on the picture? ;)
9214
15:25@BeardPower > The wallet comparison worked out with a linear scale.
Yep, that's what I meant.
GaryMiller
15:28Those small sizes are a lot more critical now for the handheld devices IOS, Android, Raspberry Pi type boxes even though large apps on the PC can still be size/speed constrained. My 40K+ line AI app takes 6 seconds to Lex now before it throws up a console window and over 4 minutes to compile with -S if I want to take advantage of System code. Hoping the Pro version gives us some nice speed ups on compiles ad Lexing in console mode.
dander
16:54How big is encapped Rebol? The size will drop a bit when that is taken out too, right? Though I guess it will be replaced by Red compiler bits then...
18:17@nholland94_gitlab module design is in the works. It ties to lower and higher level elements (modular compilation and package systems for PitL), but we don't need those in place to put out a module design for use and comment.
@meijeru how is it not truthful? In exactness? Of course we'll get bigger and have to address this, when we get over 1.5M and it would round up. ;^) Effective visualizations would be welcome though.
18:21@dander correct, trading one for the other effectively.
18:24@GaryMiller, can you describe your large file? Until we have modular compilation, building things that don't change frequently into a custom runtime could save you significant time.
18:27Or splitting the R/S parts out into a DLL. Various ways to break things down. Until we have more tooling for it, though, it's a manual process.
GaryMiller
19:07Most of the code 99% is made up of over 9,000 patterns (growing daily) and kept alphabetically by pattern to aid in cut/paste and prevent duplication. Most section look something like this although some are more complex and reference knowledge stored in objects for their responses. CD: lev UserInput/text "Are you pregnant?"
if CD < ShortestDist [ShortestDist: CD
if AI/Gender = "male"
[AIResponse: copy "Me pregnant? Are you crazy? Guys can't get pregnant!"]
if AI/Gender = "female"
[AIResponse: copy "Me pregnant? No way! Where'd you get that idea?"]
AI/Memories: []]
19:14The last block AI/Memories can also contain inferences that I want the AI to remember from what it learned from that user input. I had thought about creating a separate dialect for these blocks but was not sure if that would speed up the Lex pass or slow it down more or worse yet add an extra evaluation to each pattern as it was looped through slowing down the execution time as well. Because I don't add these patterns sequentially and skip around a lot through the alphabetical pattern list and the list is all in one big loop then separate compilation sounds difficult and they would need to share the same objects to share state and stay in synch with the knowledge the other modules has learned.
19:25CD variable means Closest Distance lev is the Levenshtein function ShortestDist keeps track if this pattern's edit distance is shorter than any others looked at so far. And updates it if this pattern is has a shorter distance. So that no other pattern examined after this one will alter this patterns AIReposne or Memories unless it is a better match.
An interesting parse experiment would be to load files, profiling the time it takes, then parse the result, tallying counts for each datatype.
19:29I should hurry, or @toomasv will have it done before I post my next message.
GaryMiller
19:30Eventually I would hope to have one Main module be a controller and break the pattern list into multiple modules that I could send the UserInput/Test to each module on a different thread. Then each module would function in parallel and return their best match and distance. and the main module would pick the best response with the shortest distance from the module list to display.
19:37Although I do realize that the the multi-threading is probably a good ways down the time line.
loziniak
19:42@nholland94_gitlab @Oldes I use anonymous contexts in my "modules", got the idea from someone else's code:
context [
hidden-inner-value: ...
hidden-function: ...
set 'exported-global ... ;-- this can be a context, or function, or any other value. you can use hidden values from outer context here as well.
]
Red [
file: %load-time-type-tally.red
]
; from %profile.red
delta-time: function [
"Return the time it takes to evaluate a block"
code [block! word! function!] "Code to evaluate"
/count ct "Eval the code this many times, rather than once"
][
ct: any [ct 1]
t: now/time/precise
if word? :code [code: get code]
loop ct [do code]
now/time/precise - t
]
incr-type: func [type [word!]][
either results/:type [
results/:type: results/:type + 1
][results/:type: 1]
]
;-------------------------------------------------------------------------------
results: #()
type-tally-rule: [
some [
ahead block! (incr-type 'block!) into type-tally-rule
| set val any-type! (incr-type type?/word :val)
]
]
while [file: request-file/file/filter what-dir [%*.red]][
load-time: delta-time [blk: load file]
clear results
parse blk type-tally-rule
print ["File:" mold file "Time to load:" load-time]
print ["Contents:" mold results]
]
halt
20:11@loziniak, and anyone else interested, the basics of information hiding with anonymous contexts is pretty easy in Red (very easy actually), but having done quite a bit of re-reading on modules and package systems recently, finding the balance, and a good starting point that doesn't paint us into a corner, is much harder. Fortunately, all the suffering caused by other systems means a lot of people have written about their experiences, which we can learn from.
20:12Defining the targets is also vital. Structuring the code base for an app and importing a few function libraries is quite different from architecting a robust system over space and time.
22:11Cleaned up the PoC and added a few comments: https://gist.github.com/greggirwin/0305173d962224fbdf59144087b0fe98
nholland94_gitlab
23:35Is there a canonical way to both retrieve and move an element from a series in red with a single word? I can build something like func [s [series!] i [integer!] /local x y] [x: at s i y: first x remove x y], but I was curious if there was something else already built into the language that I'm missing.
23:36remove seems to always return the tail of the series after the first item is moved
dander
23:38@nholland94_gitlab there is take. If you want from a specific position, you can use at or find to adjust the position in the series
nholland94_gitlab
23:40ah, perfect, I think that was exactly what I was looking for
23:41The thing I find most useful for tracking down existing functions is passing a string! to help, like ? "series"
nholland94_gitlab
01:21Is reduce [a] the typical way to take an existing block (here a) and nest it in a second block? I often find myself wanting to compose blocks into other blocks while maintaining the reference. compose [[(a)]] obviously makes a new block since it unpacks the values in a, so I've been using compose [(reduce [a])] to maintain references.
>> a: [this is my block]
== [this is my block]
>> b: [this is my other block]
== [this is my other block]
>> c: compose/only [reduce a (b)]
== [reduce a [this is my other block]]
>> c: reduce [a]
== [[this is my block]]
>> d: compose/only [(b)]
== [[this is my other block]]
>> append a 'modified
== [this is my block modified]
>> append b 'modified
== [this is my other block modified]
>> c
== [[this is my block modified]]
>> d
== [[this is my other block modified]]
02:31Example included to make sure it does what you're after.
02:58Compose also has a /deep refinement, which can make some things easier.
02:59And if you want to look at another alternative, see https://gist.github.com/greggirwin/29836d25de0c68eaba0e6dbd268a20f5
Comments welcome.
nholland94_gitlab
05:54It appears as though deep-reactor! does not support is statements in nested blocks. I wanted to do something like make deep-reactor! [a: 1 b: [c: is [a < 4]]], but that doesn't work. Trying to nest another reactor! inside did not seem to work as I would have expected wrt the static analysis on reactive formulas. For instance, if I define an reactor like x: make reactor! [a: 1 b: make reactor! [c: is [a < 4]]], a reactive formula like react [face/enabled?: x/b/c] does not work. I'm guessing I would need to do something like react (bind [face/enabled?: b/c] x) in order to make it work.
dockimbel
11:46@nholland94_gitlab When you are writing b: [c: is [a < 4]]], you are not writing a reactive formula, but just makingb word refer to a block. The static analysis is done on reactive formulas only, so only inside the argument blocks to is and react. You could write it like this instead:
>> make deep-reactor! [a: 1 c: is [a < 4] b: is [c] ]
== make object! [
a: 1
c: true
b: true
]
Note that forward references using is formulas are not yet supported (though, there should be ways to workaround that).
11:49@nholland94_gitlab > Is reduce [a] the typical way to take an existing block (here a) and nest it in a second block?
Yes, it is. Another way is to use append/only to append a block into another block.
11:51@nholland94_gitlab compose [[(a)]] will not work, as compose is shallow by default, acting only on the parens found at root level. For deep parens evaluation, you need compose/deep.
12:06This works for forward references (though a bit inelegant):
>> make deep-reactor! [a: 1 b: is [all [value? 'c c]] c: is [a < 4]]
== make object! [
a: 1
b: true
c: true
]
12:07An explicit way to delay formula evaluation would be better.
>> x: make reactor! [a: 1 b: make reactor! [c: is [a < 4]]]
>> react [test: x/b/c]
== [test: x/b/c]
>> test
== true
>> x/b/c: not x/b/c
== false
>> test
== false
Since it doesn't for you, check what part is evaluated first in your program - react or make reactor!?
15:05@dockimbel >An explicit way to delay formula evaluation would be better.
There is one - using block ;) make deep-reactor! [a: 1 b: is [[none] c] c: is [a < 4]]
9214
15:40[This](https://github.com/red/red/blob/master/environment/reactivity.red#L220) ought to be documented in reactivity docs (@gltewalt, @greggirwin). Result of block's evaluation is used as an initial value, and the rest of a reactive formula is used in all subsequent reactions.
15:52And since we're spilling the beans about secret tricks of trade that barely anyone knows, I think "VID preprocessing" can be documented too (as in [last commit](https://github.com/red/code/blob/master/Showcase/last-commits.red) showcase; note how Parse is embedded inside the VID block).
This works for any Red expression which follows extra, data, draw or at VID keywords.
dockimbel
18:27@9214 I'll take care of updating the doc for that.
dockimbel
13:12@9214 Thanks for the reminder, I forgot about that feature with initial block processed as default expression.
15:34@9214 > And since we're spilling the beans about secret tricks of trade that barely anyone knows, I think "VID preprocessing" can be documented too (as in [last commit](https://github.com/red/code/blob/master/Showcase/last-commits.red) showcase; note how Parse is embedded inside the VID block).
That's already documented in VID doc, except for at keyword. Though, I'll making it more visible.
I'm a _complete_ Red newbie - but already fascinated by this wonderful programming language (no kidding)! So playing around with the data-as-code ideology of Red, I tried to implement a small-ish function which should allow the definition of a very simple precondition of some kind:
precond: func [spec-def] [
; example function call including 'spec-def': precond [ var: entry spec: [integer! float!] ]
unless parse spec-def [
set-word!
word!
set-word!
block!
][
print ["wrong spec format" mold spec]
]
code: "all ["
repeat idx (length? spec-def/spec) [
loop-var-value: (get 'spec-def/var)
cur-var-val: get loop-var-value
loop-spec-value: (get 'spec-def/spec)
print "<---M-A-R-K-E-R--->" ;-- poor man's debugging: so we can see how far the script runs before bumping into an error...
to-append: reduce [( (type? (cur-var-val/:idx)) = get (loop-spec-value/:idx) )]
append code " "
append code to-append
]
append code " ]"
probe mold code
do load code ;-- run the code after converting from string into data
]
So far, so good - even if the code looks like written by a newbie ;-) Running gives:
;-- works fine with a *single* data:
entry: [1 6.0]
print precond [ var: entry spec: [integer! float!] ]
;-- returns:
; <---M-A-R-K-E-R--->
; <---M-A-R-K-E-R--->
; {"all [ true true ]"}
; true
However - *and that's the thing I don't get at all!* - if I try to use the precond function somewhere else...
;-- does NOT work within a loop construct :-(
foreach [entry] [
[1 6.0]
[2 5.0]
] [
print precond [ var: entry spec: [integer! float!] ]
]
; returns:
; <---M-A-R-K-E-R--->
; <---M-A-R-K-E-R--->
; {"all [ true true ]"}
; true
; <---M-A-R-K-E-R--->
; <---M-A-R-K-E-R--->
; {"all [ true true ] true true ]"}
; *** Syntax Error: invalid value at "]"
; *** Where: do
; *** Stack: precond load
... crazy stuff happens (at least from my Red-newbie-perspective).
Would anyone from you be so kind to explain what's going on with the precond function in the last example? *Many thanks in advance!*
9214
16:50Hey @asemt, welcome! [This](https://github.com/red/red/wiki/%5BDOC%5D-Why-you-have-to-copy-series-values) should explain what's going on (and if it doesn't, drop by our [/help](https://gitter.im/red/help) room for guidance and walkthrough). Also, be sure to check out our [learning resources](https://github.com/red/red/wiki/%5BLINKS%5D-Learning-resources), to kickstart your learning process.
asemt
16:55@9214 **Thank you very much!** What a quick and meaningful response. Wonderful. Will look at the resource you provided as soon as possible (on the run right now)...
9214
16:58@asemt long story short, try to use code: copy "all [" instead.
asemt
17:00@9214 **Wow, you're fast!** And right - now it works :-)
17:22@asemt and here's a more-or-less idiomatic rewrite that preserves your original idea:
precond: function [spec-def][
unless parse spec-def [set-word! word! set-word! block!][
print ["wrong spec format" mold spec-def] break
]
var: get spec-def/var
spec: spec-def/spec
result: copy []
repeat i length? spec [
append result same? type? var/:i get spec/:i
]
reduce ['all result]
]
As you can see, string manipulations are reduntant in this case, as you can just aggregate block! directly.
There's also a typo in your original snippet: it should be either mold spec-def or mold spec-def/spec, and unless itself must halt the execution instead of just printing an error message.
00:18@asemt and since you're interested in "data-as-code", here's how you can fix my mistake :wink:
body: body-of :precond
body/5/3: 'exit
asemt
07:52@9214 Good morning - and: Thx for the "data-as-code" fix ;-) **And** ofc for your much more concise & clean version of what I had in mind! You guys are such a helpful and friendly pack - _awesome_.
gurzgri
13:52Hi @asemt: I totally may fail to see what problem you're trying to solve with your PRECOND function, but I have the gut feeling that you probably might not need it:
In both cases, the PARSE version w/o PRECOND seems to do the job and is shorter, too. But as I said, I might be on the wrong track ...
9214
14:00@gurzgri I think the point was to stretch the muscles and learn how homoiconicity works in Red - a perfectly fine excercise for a newcomer. Right now Parse indeed fits the bill, but precond might as well evolve into a dedicated DbC dialect (e.g. a function constructor that inserts pre- and post- conditions at the right places in function's body).
And, just FYI, end in your rules is reduntant.
gurzgri
14:58@9214 Thank you for pointing out that end in my rules is redundant indeed - I'm obviously still in regex mode doing a lot of /... $/ matching recently.
greggirwin
01:28@rebolek's dependent type experiments also apply as we think about DbC alternatives.
02:16Coming from the red/bugs group, where the return value of remove-each came up again, as an open design question. I closed with this:
> It's always a balancing act, between *potentially* useful things, and *commonly* useful things, weighed against adding too much stuff, making everything harder to use correctly. Include enough rich functionality that you don't *need* a lot of external bits, as with JS, but not so many that the built-in features are overwhelming and confusing.
I'm moving here to make a more general comment, in how this affects our thinking, as both users and designers. And how Redbol langs give us new ways to experiment, easily, to see what works.
As an example, we have the round function, which subsumes trunc ceil floor "banker's rounding" and scaled rounding. I fought hard for that design, but separate funcs *can* be useful as well. There's a lot to consider. For example, in R2, this is the entire code for round, for all supported types:
round: func [
{Returns the nearest integer. Halves round up (away from zero) by default.}
[catch]
n [number! money! time!] "The value to round"
/even "Halves round toward even results"
/down {Round toward zero, ignoring discarded digits. (truncate)}
/half-down "Halves round toward zero"
/floor "Round in negative direction"
/ceiling "Round in positive direction"
/half-ceiling "Halves round in positive direction"
/to "Return the nearest multiple of the scale parameter"
scale [number! money! time!] "Must be a non-zero value"
/local m
][
throw-on-error [
scale: abs any [scale 1]
any [number? n scale: make n scale]
make scale either any [even half-ceiling] [
m: 0.5 * scale + n
any [
all [
m = m: m - mod m scale
even
positive? m - n
m - mod m scale + scale
]
m
]
] [
any [
floor
ceiling
(ceiling: (found? half-down) xor negative? n down)
n: add n scale * pick [-0.5 0.5] ceiling
]
either ceiling [n + mod negate n scale] [n - mod n scale]
]
]
]
Ladislav Mecir deserves the credit for the elegant code above. The size belies how much is going on there, and one of the most beautiful pieces of Rebol ever written IMO.
In R3 and Red, it's an action for performance reasons, but that means more low level code, and sometimes a bit of duplication between types. Another approach would be to write native trunc ceil floor, etc., but a benefit of round as a name, is *meaning*, and using refinements to make it clear that you're still rounding, but in a more specific way. Not only that, if you do help round you get it all in one place. Making sure "round" is in all doc strings for separate funcs would be a workaround.
If you call round and it doesn't work as expected, you see the other options in context, concisely, rather than separate docs explaining things. This is not literate programming, but a way to leverage the fact that we can remember some things, but not all the details (or we shouldn't have to). With a little hint or reminder, it clicks into place. That's what doc strings are for, and why we keep them short.
It's all about leverage. But we have to choose which axis to apply it to. Every time.
Now, let's talk about split... Or maybe I'll copy this message and make a note for a future blog entry section.
xqlab
06:39split should be written in R/S for performance reasons
greggirwin
09:00@xqlab I want split to be like it is in R3, high level and dialected, but perhaps a fully dialected interface. The old /into design came about before the standard meaning for /into with series funcs, so it's a poor match now, and was always a little uncomfortable for me. I just couldn't come up with anything better at the time.
I actually feel that round would still be fine as a mezz, but understand the reasoning. With round the decision to keep it as a mezz, and not designate an action slot for it, would have made changing that decision later much more difficult. And you do get a big boost on numeric performance.
You will hear me push back on "performance reasons" a lot, because I really dislike premature optimization. :^) The way to convince me is with hard numbers. In the experimental design I have for split, the idea is to have specialized splitter funcs for each type of splitting. Then the main split function basically becomes a dispatcher to those. This will let us experiment and design at the high level, and once we have hard numbers, it would just be a matter of rewriting the specialized funcs as natives.
09:08If you have performance numbers for the current split, and a case where it's too slow, those would be great to see.
>> s: read-clipboard
== {-----------------------------------------------------------------------^M^/^M^/
>> length? s
== 125641
>> profile/show [[b: split s #" "]]
Count: 1
Time | Time (Per) | Memory | Code
0:00:00.05 | 0:00:00.05 | 2109224 | [b: split s #" "]
>> length? b
== 21058
09:16Something to keep in mind, even with the current, simple interface for split in Red, is that Red/System doesn't have a bitset! datatype.
xqlab
10:25the current split is based on parse rules and the simplest jobs take much longer than the old **parse some-string none**
10:28I have no hard data as I do this kind of jobs not anymore. But I remember significant differences when dealing with bigger log, protocol and data files. Maybe the real problem is parse
meijeru
12:15@greggirwin ... But Red/System _does_ have functions to test bits in a bitset!
pekr
12:17@xqlab I do remember some old Parse tests and getting slower results, but not sure what was the outcome. It might be related to parse implementation as well as fact, that Red compiled program does not run at native speed, but something like 3-4 times slower? But - don't get me for granted. It always depends upon many factors, so I have no hard data to back up .... just some old discussions I remember ....
17:33And parse will be slower in Red, not only because of @pekr's point, but because it also has tracing capability now, which has some overhead.
@xqlab the question for me is not that something is faster or slower, but is it fast *enough* for most cases, or is it unnecessarily fast, and more complex because of that. For example, I mentioned round, and if you're using it mainly for user-facing or interactive data, there is no win at all from making it native. None. If, however, you need to do rounding in loops, on large datasets, it will make a big difference.
dockimbel
21:06> the current split is based on parse rules and the simplest jobs take much longer than the old **parse some-string none**
Apples and oranges... In parse some-string none, there is no Parse dialect or Parse interpreter involved, it's a purely native implementation of split.
xqlab
07:03That's the reason why I vote for a native split. By the way the current implementation of split goes back to a suggestion of me. I vote for an additional library with useful parse rules including special split rules. This library should be a standard part of Red.
asemt
09:31@9214 > Right now Parse indeed fits the bill, but precond might as well evolve into a dedicated DbC dialect (e.g. a function constructor that inserts pre- and post- conditions at the right places in function's body).
Exactly, that was the initial idea! Actually precond was "designed" as a macro in the first place - however I was unable to get it working, probably due to my profoundly small noob-knowledge of Red's syntax and semantics. Also what made it really hard for me to implement this precondition thingy as a macro was the "debug-ability" or better: the lack of it...
While I'm here, some questions ;-) Are there any ways to expand a macro to see it's outcome during development time (or any other tools in this regard)? And another metaprogramming-related question: Is there a way for a function to be aware of it's surrounding function in the case a function gets evaluated as part of the body definition of an "outer"/surrounding function? Thx for any help - as always!
> Are there any ways to expand a macro to see it's outcome during development time
If we're talking about Red macros, then [this](https://www.red-lang.org/2016/12/entering-world-of-macros.html) and [this](https://doc.red-lang.org/en/preprocessor.html) should cover you well. If we're talking about code transformations that you did with precond - these are not macros, all metaprogramming in Red can be achieved with regular functions; it's as simple as
In reality, macros (i.e. Red preprocessor directives) cover a very specific need (generating boatload of boilerplate for compilation-intensive apps), and you certainly do not need them. "Seeing outcome during development time" can be done, once again, with regular functions like print or probe.
> Is there a way for a function to be aware of it's surrounding function in the case a function gets evaluated as part of the body definition of an "outer"/surrounding function?
So you want to mimick dynamic scoping? This is possible to some extent in pure Red, but requires ad-hoc trickery.
>> foo: has [marker][bar 'marker]
== func [/local marker][bar 'marker]
>> bar: func [argument][print ["called by" mold context? argument]]
== func [argument][print ["called by" mold context? argument]]
>> foo
called by func [/local marker][bar 'marker]
Another way is to implement a Red/System routine that would examine call stack and fetch caller for you, but that's non-trivial, not very newbie-friendly and requires a mandatory compilation.
asemt
10:55@9214 Thank you for the pointers and examples!
toomasv
10:56@asemt In addition to what @9214 wrote it is also possible to use reflection:
set-mole: func [:f][probe f insert body-of get f reduce ['spy to-get-word f]]
remove-mole: function [:f][if 'spy = first body: body-of get f [remove/part body 2]]
set-mole f1
f1 2 3
;spec/values: [a: 2 b: 3]
;body: [a + b]
;== 5
remove-mole f1
;>> [a + b]
asemt
11:50@toomasv What a clever mole! :thumbsup: Thank you very much.
toomasv
12:05@asemt You are most welcome! It was pure fun!
asemt
12:08@toomasv Yes, I thought so ;-) May I ask, how long (roughly) you're already into Red/Rebol programming?
13:45@greggirwin Thanks for the gists! However, I'm afraid this is beyond my current Red/Rebol understanding...
9214
14:56@greggirwin I'm aware of them; unfortunately, neither of the two has anything to do with @asemt's original question (how callee can examine its caller). Same goes for @toomasv's examples.
> Is there a way for a function to be aware of it's surrounding function in the case a function gets evaluated as part of the body definition of an "outer"/surrounding function?
The question "how callee can examine its caller?" is one interpretation of the original question.
greggirwin
00:13@9214 you mentioned dynamic scoping, which brought that work to mind.
meijeru
10:31@dockimbel Is the work on ports implementation on-going? I have some remarks on the coding of ports.redswhich I can send you if you wish.
dockimbel
13:18@meijeru It is still on-going. You can send them.
11:57Number of issues has descended under 400! Work is speeding up. I notice that there are still a number with status built but not yet closed. So more progress to be expected.
12:06As I wrote this, another issue (contributed by me) was resolved. Keep on going!
12:13Still, 23 issues have status.built and are open.
12:14A number of them could be closed, but there are also some that have been re-opened because the solution was unsatisfactory...
dockimbel
13:15@meijeru Thanks! Yes, those status.built one are a bit annoying, we should try to get them close asap.
GiuseppeChillemi
15:22Could I ask if user defined types have will be implemented? The more I work on RED, the more I need to have them.
15:50@GiuseppeChillemi User-defined types (UDT) are planned, but they are mostly for library writers. Red is not a OOP language and won't become one.
greggirwin
16:44@GiuseppeChillemi what do you need them for? I ask because I've used Redbol langs since 2001 and never *needed* them. They might have been helpful at times, but never a showstopper.
GiuseppeChillemi
17:53@greggirwin the simplest use is finding and selecting for an item in a block. Actually you can select for a specific filename in a block but if you have a custom structure you have to use many functions to navigate the layers of words and blocks of your structure for simple operations.
greggirwin
18:10Please provide a concrete example. Finding and selecting in structures should be very easy. If we can see what your data looks like, and how you're doing it now, we may be able to offer advice.
REBOL []
random/seed pick sig: copy {B aRt hcJnetrhuEOkL!eraso} 21 probe random sig
;=="Just another REBOL hacker!"
halt
Red surprise-message.red
Red []
random/seed pick sig: copy {B aRt hcJnetrhuEOkL!eraso} 21 probe random sig
;=="LO !khrsEJR cBaet utoanher"
If you are interested how it works (at least in Rebol):
REBOL []
sig: copy "B aRt hcJnetrhuEOkL!eraso"
random/seed 33 ; = 21e character of sig, you could use: random/seed sig/21
probe random sig
;=="Just another REBOL hacker!"
halt
I believe R2 and Red use different sources of randomness.
greggirwin
19:06We aim for a high degree of compatibility, but the random number generator is not the same.
Rebol2Red
19:10I see, so what is the way to make something similar? No wait, let me think about it for while and do it myself. If i succeed where should i post the code. Over here?
greggirwin
19:12I started writing ideas, but glad you want to try yourself. :^) Post here, yes.
; randomize a text with a seed
random/seed 33
text: random "Just another REBOL hacker!"
probe text
;=="hLsa EkrOh ntJtc uBa!eeorR"
; some testing
print to-integer text/21
;==!
probe to-integer pick text 21
;==33
; Now using the text from above
; I thought this should work
random/seed to-integer (pick sig: copy text 21)
probe random sig
;=="aus!Bter h kOhaetLcERo rnJ"
; But unfortunately it does not :(
Do i need to use the inverse of random/seed?
Here is a simple example: I have created a strucutre where I store either queries or tables with data. The data block for queries is initialized to [] and filled with data when the query is run.
If the data source is already a table will be either pre-stored and loaded with the whole data-sources set, or loaded at runtime when first accessed using the local-cache filename.
data-sources:
[
get-openorders
[
description {description here}
data-type 'sql-query
local-cache %get-openorders.query-result
ambient 'ARCA
server-name 'MYSERVER
sourcedb []
data-source {
SELECT
dotes.Cd_Do,
dotes.NumeroDoc,
cf.cd_cf,
cf.descrizione,
dorig.cd_ar,
dorig.descrizione,
dorig.Qta,
dorig.QtaEvasa,
dorig.Cd_ARMisura,
dorig.FattoreToUM1,
Dorig.ID_DoRig
FROM DORig
inner join ar on ar.cd_ar=dorig.cd_ar
inner join dotes on dotes.Id_DoTes=dorig.Id_DOTes
inner join CF on dorig.cd_cf=cf.cd_cf
where dorig.Cd_DO in (&&&DOCUMENTS&&&) and dorig.evasa=0 and dorig.QtaEvadibile > 0
}
query-args []
columns [
Cd_Do
NumeroDoc
cd_cf
Cliente
cd_ar
Articolo
Qta
QtaEvasa
Cd_ARMisura
FattoreToUM1
IDR
]
conversions [NumeroDoc [ctype 'map name 'map-name] Articolo [ctype 'rule name 'rule-name]]
filters [documents {'OW','OC','A1','A2','A3'}]
data-block []
]
estrai_AR [
description {}
data-type 'sql-query
ambient 'ARCA
server-name 'MYSERVER
sourcedb []
data-source {
select
CD_AR,
Descrizione
from ar
}
query-args []
columns [CD_AR Descrizione]
conversions [NumeroDoc [ctype 'map name 'map-name] Articolo [ctype 'rule name 'rule-name]]
filters []
data-block []
]
]
When data source is a TABLEdata-type has TABLE insted of SQL-QUERY.
A simple operation would be to find a block whose name is ESTRAI_AR and dataype is SQL-QUERY (currently all are SQL-QUERY but as I said, another option is TABLE)
greggirwin
21:01Thanks @GiuseppeChillemi. While I digest this, what would a UDT solution look like for this, in your perfect world? That is, how do you see a UDT version solving your problem?
21:19If your data structure is consistent, or at least always shallow, you should be able to generalize lookups pretty easily (remember, I'm coming from the outside, so don't know details that may complicate things).
This is an and/all match for attrs, returning all results that match.
dockimbel
21:20@Rebol2Red Couldn't resist making a generator in Red for such hidden messages: https://gist.github.com/dockimbel/f6c90a135b7ef96c8ef693ce014cbc99
>> gen-hack "Just another Red hacker!"
random/seed pick sig: copy "onr!hhca tRete s Jkerdua" 5 random sig
>> random/seed pick sig: copy "onr!hhca tRete s Jkerdua" 5 random sig
== "Just another Red hacker!"
21:30@qtxie I am wondering if we should not allow setting the seed for random *and* randomizing the argument series at the same time as Rebol does... but Red's way might be more clear...
21:32@greggirwin I'm pretty sure there should be a shorter algorithm for generating the encrypted message than the one I've used (using a single table instead of two).
greggirwin
21:41I didn't do random seed generation, just picked one:
text: "Just another REBOL hacker!"
blk: collect [repeat i length? text [keep i]]
random/seed 33
r-blk: random copy blk
r-text: " "
repeat i length? text [poke r-text r-blk/:i pick text i]
random/seed 33
print mold copy random r-text
21:44I think the design is OK, unless you want a separate randomize func, so random always returns a value.
dockimbel
21:47I've simplified my version with a single table too.
GiuseppeChillemi
21:49@greggirwin thanks, I will digest your idea tomorrow as here is very late. Also, the answer about "how should UDT" work, there are various strings of ideas in my mind. The first answer is: the actions of adding, deleting, moving into the structure, modifying, searching should be delegated to user defined code while maintaining the simple wording of current RED istructions. Then anything would maintain the actual simple way of doing things while having even complex data types.
21:52The middle layers of actions should be extendable in some way in R/S.
gen-hack: function [secret [string!]][
;-- First build a list of integers from 1 to the last index of the secret string
table: collect [repeat i len: length? secret [keep i]]
;-- Pick a seed from the secret itself
random/seed s: pick secret random len
;-- Shuffle the integers list with that seed. This results in a table of decoding indexes.
table: random table
;-- Encrypt the message by selecting each character using that table
collect/into [repeat i len [keep pick secret index? find table i]] masked: copy ""
;-- Find the index of the selected seed character in the encrypted message
i: index? find masked s
;-- Generate the line of code with the encrypted secret
oneliner: mold/only compose [random/seed pick sig: copy (masked) (i) random sig print sig]
]
oneliner: gen-hack "Just another Red hacker!"
print oneliner
do oneliner
dockimbel
22:05@Rebol2Red You're welcome. I've put it in a Gist to avoid flooding this chat...
toomasv
09:33Yet another [gen-hack2](https://gist.github.com/toomasv/ad30d5b9f7f6699fe83dc72ea723b97e), combined from Gregg's and Doc's with some additions.
>> do gen-hack2 "Just another Red hacker!"
[random/seed 2 random "uhJts trnckoe!e rRha dea"]
== "Just another Red hacker!"
>> as url! do gen-hack2 http://some.domain.com
[random/seed 7 random "s:dm..o/n/ceoaomthpitm"]
== http://some.domain.com
>> to-path do gen-hack2 'randomizing/blocky/things/too
[random/seed 3 random [too blocky things randomizing]]
== randomizing/blocky/things/too
>> do gen-hack2 #{DEAD0123BEEF}
[random/seed 6 random #{DE23AD01EFBE}]
== #{DEAD0123BEEF}
Keeps selecting random seeds.
greggirwin
17:12Nice. :^) Could use a doc string to let people know it creates a self extractor.
20:21@greggirwin Today I have tried to write some ideas about UDT, I admit ist not easy to write it down for such audience. Also ideas keep flowining and organizing. It is really not an easy task !
meijeru
19:06I have a suggestion to enrich the GUI console with a facility to check for updates to the Red executable: add a new menu item just below About: "Check for updates" check-updates add an item to the body of the on-menu actor:
17:37Thanks for the idea @meijeru. If you're running it from the console, it could just print and ask rather than popping up a modal window.
@JacobGood1 other internal features have a higher priority right now.
meijeru
17:42@greggirwin While testing, I had some problems printing. Ask was a convenient alternative. Both variables installed-date and latest-sha are used only once and can be substituted. Alternatively, the test can be on latest-sha vs installed-sha which is system/build/git/commit (of type issue!).
endo64
18:56@meijeru load https://api.github.com/repos/red/red/commits/master will load the latest commit only, otherwise it will load whole commits which is too big.
meijeru
19:08That is not my experience. With /master I get 11 commits, without, I get 30 commits. Both fit conveniently.
19:24Anyhow, I got this from @dockimbel (see this [gist](https://github.com/red/code/commit/f1bdba918ddd6c6107525e4d5bb7f302ed7e80f8)).
endo64
20:36No actually lenght? load https://api.github.com/repos/red/red/commits returns 11, but it is the number of keys in the returned map.
>> s: load https://api.github.com/repos/red/red/commits/master
>> length? s
== 11
>> ? s
S is a map! with the following words and values:
sha string! "6993e8d55501505101f5381b6598cd03407ba ...
node_id string! {MDY6Q29tbWl0MTQ0OTc3Mzo2OTkzZThkN ...
commit map! [author committer message tree url ...
url string! {https://api.github.com/repos/red/red/ ...
html_url string! {https://github.com/red/red/commi ...
comments_url string! {https://api.github.com/repos ...
author map! [login id node_id avatar_url gravat ...
committer map! [login id node_id avatar_url gra ...
parents block! length: 1 [#(sha: "c84a5615fcead6 ...
stats map! [total additions deletions]
files block! length: 1 [#(sha: "ac2daa52cb095bf0 ...
20:40https://api.github.com/repos/red/red/commits returns the last 30 commits (one page)
meijeru
22:00Understood. It remains true that it is not too big.
endo64
09:37Threads are coming! :) https://github.com/red/red/pull/3998
dockimbel
10:31@endo64 Just low-level support for now. Though, we have a solution for implementing a (heavy) task! type, but it's not a priority right now.
pekr
14:42@dockimbel Don't worry. What you just wrote already sounds much more robust than what R3 provided re tasks 😀
dockimbel
15:51@pekr Is there any doc describing R3 tasks? Are they thread-safe by design?
pekr
16:00I don't think there were tasks properly implemented. I did some tests in console only back then. By making task in console it behaved in a non blocking manner, but there was no proper interface of how to work with tasks IIRC. We would have to look into sources. I doubt it was a finished work at all. My remark wa smostly a joke ....
12:49Those of you who look at the specs document occasionally, will have noticed that I have been able to remove references to at least 10 issues that I had noted - because they were resolved, obviously. Keep up the good work, Red team! The overall number of open issues has gone down by about 50 recently. Will it hit zero, ever?
05:41For us uneducated, what is please Atomic branch about? Better target / cpu support?
dockimbel
08:59@pekr Support for atomic operations at CPU level allowing the implementation of concurrent lock-free algorithms and datastructures in R/S. We need that for implementing a lock-free queue for async I/O in a multithreaded environment (some I/O devices require one or more threads to operate asynchronously).
pekr
10:45Nice, thanks. Is that a temporary solution, or does it mean, you've already decided about the architecture of final implementation?
dockimbel
11:22The lock-free queue is the low-level datastructure for async I/O that we currently need. If it works as well as planned, we'll keep it.
ldci
16:14Hi, you can play with ffmpeg from Red: https://github.com/ldci/ffmpeg
ldci
11:34New samples and doc for ffmpeg and Red: https://github.com/ldci/ffmpeg.
BeardPower
15:40A lock-free queue is so good, you want to lick it ;-)
13:23as I did not know anything about such architecture, found some old article, which explained some things. Did not read it all though, too long and I felt lost after some time. Interesting stuff indeed :-) https://www.linuxjournal.com/content/lock-free-multi-producer-multi-consumer-queue-ring-buffer
13:23I've you eventually got some resources for us to read, feel free to post a link. I know that real gurus are OK with jus the source code of particular implementation :-)
9214
13:45@pekr if you're asking about concurrency in general, then I can wholeheartily recommend [OSTEP book](http://pages.cs.wisc.edu/~remzi/OSTEP/). [Little book of semaphores](http://greenteapress.com/semaphores/LittleBookOfSemaphores.pdf) is also frequently suggested, but I haven't read it yet. Though, none of the two is a light read, and both require at least a basic understanding of computer architecture with C and assembly-level programming, so, you might want to google illustrated examples instead, like e.g. [Jeff Preshing's semaphores](https://preshing.com/20150316/semaphores-are-surprisingly-versatile/).
13:48But if you're interested in parallelism and want to beat @greggirwin in arm-wrestling at some point in your life, then your secret weapon are Tuplespaces and Linda.
pekr
14:19Thanks - interested in an architecute Red is eventually going to be using ....
greggirwin
21:25@9214 that semaphore book is new to me. Looks great at a glance.
spTorin
09:14Not a specialist in LISP (In RED too). Why is the compiled LISP program so fast? Are the functions in LISP always fully compiled and are analogs of the routines in RED? Are macros in LISP an analog of functions in RED and is it possible to change the macro/function body in runtime and execute it in the internal interpreter?
9214
09:50@spTorin questions about Lisp should go in a [dedicated room](https://gitter.im/red/red/lisp).
> Why is the compiled LISP program so fast?
You ought to be a bit more specific here - there are many dialects of Lisp, each with its own implementation. Mammoths like SBCL expose incremental compiler which you can use at runtime with different optimisations, home-brewed Schemes can run on top of bytecode VM (e.g. Guile) or run in interpreter only.
> Are the functions in LISP always fully compiled and are analogs of the routines in RED?
Red routines are a bridge between Red and Red/System, so, no, it's not like Lisp functions. But then again, it depends on Lisp implementation: I'm pretty sure you can write machine code or assembly in Common Lisp, but it's not the same as using a dedicated DSL for system-level programming and runtime interaction, the way Red does with Red/System. The closest I can think of is Shen which compiles to bare-bones platform-independend Scheme called klambda.
> Are macros in LISP an analog of functions in RED
Lisp macros are not the same as Red functions, they operate in a separate expansion phase and, for hygenic macros, have a dedicated namespace. In Red, all code transformations can be achieved at runtime.
> is it possible to change the macro/function body in runtime and execute it in the internal interpreter?
Are we talking about Lisp or Red here? In Red - yes, you can change body of a function! and it will affect its subsequent runs, but altering spec won't change anything (because it's just a copy that function! keeps for reflection purposes). With Lisp it should be the same, due to homoiconicity - functions are just lists, you can do whatever you want with them. Not sure what you mean by "internal interpreter" though.
spTorin
11:41@9214 Tnx for answer. I just wanted to find out if RED in the future (with optimizations) could be as fast as SBCL without using low level DSL red/systems.
9214
11:46@spTorin there's a hard cap in interpreter's speed (not just in Red but any other interpreted language), which can be bypassed by just-in-time compilation techniques - they are in the plans for post-1.0 roadmap. Current static compiler serves only as a throw-away platform for bootstrapping and has no optimization layers, same goes for interpreter. Squeezing out perfomance is not the point (yet).
15:07@spTorin the most important thing here is having concrete examples and hard numbers. What are you doing in SBCL, what does the code look like, and what does your equivalent Red code look like?
15:19There are always tradeoffs, and comparisons have to be contextual.
On the first point, SBCL is much bigger. Optimized code can be larger, but we also have to look at architectural differences. Red is 1/25 the size of SBCL. While missing some features, Red includes a cross platform reactive GUI system, drawing dialect, and parse. This is just to say that our priorities may be different, and our strengths lie in areas other than raw performance.
To the second point, SBCL is based on CMUCL, so there is a massive difference in maturity and man-hours behind them. It's a similar situation when people want to compare Red to Racket.
dockimbel
15:44What is the best example of meta-programming in Red you can think about, that we could post on this [Rosetta page](https://rosettacode.org/wiki/Metaprogramming)?
15:47BTW, if you want to help Red spread around, filling the Rosetta pages with Red examples would be a great start. ;-)
pekr
15:53Are DSLs a meta programming? Some nice code, also in the past liked some SQL example and what was ultimate was an Alien dialect, but a bit crazy indeed ....
9214
16:17@dockimbel I would go the same route you usually walk when introducing Red: incrementally showing how to construct blocks dynamically, series, datatypes, how words and binding works, etc; culminating in something compact that features compose, bind, parse and whatnot; including comparison with traditional Lisp-like macro approach.
greggirwin
16:19@dockimbel we have an [Advocacy](https://github.com/red/red/wiki/Advocacy) page where people can see places to fill in Red examples.
16:54That RC page is pretty funny. So many examples hedge their inclusion in the list ("doesn't support 'true' meta-programming", "This is not really metaprogramming", "could be considered meta-programming")or rely on external elements (C's preprocessor or Visual Studio tools in the C# entry). True that metaprogramming can take many forms, including external ones, but that falls outside language support for it, which makes the page intent vague.
The "competition" is basically CL, Forth, Racket, and notably Rascal.
Really, this deserves its own article, but we can start with some examples on RC, pull those for an article, then feed improvements back to RC. @9214 would be a great author for that IMO.
My reasoning is that there is no "best" example in Red, because you can do things in so many different ways. Being able to choose the best metapproach for a given purpose or scenario is the killer feature of Red in this area.
GiuseppeChillemi
21:15Reading you chat and trying to understand and learn what metaprogramming is I have encontered this page: https://en.wikipedia.org/wiki/Metaprogramming REBOL is mentioned there but RED isn't. I think it could be included in the article but I don't want to modify it. I suggest someone with better skill on computer science, RED and english language could do the change, add (if needed) more information and keep looking at the page (@9214 ?, @greggirwin ?).
mikeparr
07:29@GiuseppeChillemi - re the metaprogramming page, REBOL only gets a mention because of its homoiconicity. On the wikipedia discussion page, there is some debate on what metaprogramming actually is.
GiuseppeChillemi
08:36@mikeparr without entering into metaprogramming definition, if RED is entitled to be mentioned on that page I think RED is entitled too and we should add it.
mikeparr
10:42@GiuseppeChillemi - I agree (you meant REBOL?). Should we simply alter it to REBOL/Red ? There is also the 'Macro Systems' section, which includes Nim - maybe Red should be there?
9214
11:12@mikeparr Red doesn't have any macro system, ditto Rebol. Calling existing "preprocessing directives" macros is a misnomer, as it implies use-cases (metaprogramming, DSL, code reuse, language extension) for which traditional block manipulations and Parse are far more suitable.
greggirwin
17:41The issue is...words and names. Metaprogramming and Macros are very general terms that many languages want to say they support, so the definitions are bent and stretched. @9214, this is another area where your knowledge and understanding can be brought to bear. Under the banner of Advanced Concepts, we have these, HOFs, and some other elements/features/paradigms that Red puts a new spin on. We need to set things in context for those familiar with them, note how Red is different, and select the best name in Red's context *or* see if there's a better one. The latter is tricky of course, but think of block versus list.
avitkauskas
19:20Hi. Red Language Server could not be started on my VSCode (ver: 1.37.1 on Mac OS). Connection to server got closed. Server will restart. Connection to server got closed. Server will not be restarted.
14:10@loziniak Thanks for maintaining that GTK page! :+1:
dockimbel
17:10Is it me or the AV issue [got](https://www.virustotal.com/gui/file/7ed3e9f45b1a814b8c45cfac1efd1dbf02045b0bee3036edba594337e16a2d48/detection) [better](https://www.virustotal.com/gui/file/bc79b8e7323067b0f324188f399c5b40a713c701da22bf2d11da56d76f53ac31/detection) recently? Only Avira and F-Secure remain problematic, and a few other unknown ones.
17:36Strangely, the --no-compress option seems to make [no difference](https://www.virustotal.com/gui/file/723423b362433d152abbdae0dbf56a3ae6f3a649b7cf38e4e47341158a06b666/detection) on the false detection of the remaining ones.
pekr
17:41 Did they got better, or did Red changed some low level bits, so they no longer complain?
dockimbel
18:47It's not Red's doing, so I guess most of them fixed/improved their engines. Though my testing is done only using VirusTotal (we don't use any AV on our machines), the behavior of AV installed on end-users machines could differ.
18:50I've submitted a false-positive report to F-Secure. I gave up on Avira a while ago, after sending many reports without getting any feedback.
dander
19:12Have you considered using a code signing certificate? It does cost some money, but I think some AV tools will begin to trust the certificate over time. I'm not sure if there would be a problem with on-the-fly compiled components being unsigned, but those are at least generated locally, rather than from the internet, so they may be more trusted
dockimbel
19:44@dander Sure, we did. First, it's hard to obtain, as you have to go through many online and offline hurdles (being based in China for many years was one of the show-stoppers). Second, it's only for the Red binaries we distribute, not for user-generated ones. For the on-the-fly components, we should replace some of them with precompiled ones in the 0.6.5 release.
10:41I notice that type info has been added to all local variables in hashtable.reds. This is worthwhile from a documentation point of view but I guess that to extend this to the whole toolchain would usurp precious manpower. What is the policy to be?
dockimbel
11:16@meijeru The Red runtime library functions should have type descriptions for locals to avoid compiler falling back to 64-bit stack slots for local variables. Not only that wastes stack space, but also creates "holes" where garbage data from previous calls can remain, creating undefined behaviors for the GC.
meijeru
06:31I see. Still, it is a tall order to do that for all of them...
dockimbel
11:16@meijeru It is not necessary for "all of them", just for the function that can be on the call stack when the GC is invoked. Anyway, it's a temporary measure that will be superseded by some upcoming new R/S features.
hiiamboris
07:59@dockimbel speaking of R/S features, using Red stack from R/S feels like holding a blade by it's edge :) It's filled manually item by item in various parts of code, sometimes recursive code, then gets modified by the many functions you call from that code (and the functions called by those functions). So basically it's impossible to predict what will happen to the stack by just looking at the source. As an example if anybody will be able to follow how the stack works inside [do-print](https://github.com/red/red/blob/6cfcfe9dd98c79b48d8cf641c3634eb37e952202/runtime/natives.reds#L678) in less than 2 hours, I'll applaud him :)
So, can you add a (debug-mode) feature that would check the Red stack (or any data referred to by another pointer) layout declaratively and report if anything's amiss?
(the above would check that stack/top is at least 3 slots above the arguments, and compare it's contents with the provided constants, then call the some-func* that relies on this specific layout)
avitkauskas
20:30Hi. Could you please share what is the current status with 64-bit Red? Mac OS Cataline is round the corner. Does that mean I will not be able to run Red apps on my Mac soon?
greggirwin
20:36@avitkauskas Catalina is a big issue for us, and we've outlined the 64-bit plan, though things can always change. Mac comes first, with some key changes being needed in deep internals (e.g. 64-bit pointers and a decision on cell size), but we can cross compile from 32-bit, which is how we'll bootstrap the move. We need Mach-O 64-bit file format and x64 generation from R/S. Those are the first big pieces. Then all tests have to be updated, then the View engine.
avitkauskas
20:44Yea, I imagine how big thing it is to change to 64-bit. What disturbes me is that the talks about the necessity of 64-bit was going around from at leat 2016 (if not much earlier), but still it seems that everyone is caught by surpise. I am totaly new to Red, and I like it very much, I like the idea! But it looks so much endagered by this 64-bit issue. I understand that the core team is really small, so this puts additional presure on the matter. I could only wish you strenght and optimism to deal with that.
greggirwin
20:47Thanks for the support. It is a big challenge, and we're not caught by surprise so much as having the issue forced. With other big design elements in the works, it's a distraction from that. With these changes, there may be things R/S community members can do to help. If Nenad and Qingtian lay out chunks of "grunt work" or tasks they feel safe in delegating to a couple trusted members, that will help a lot.
20:48And we have to weigh the importance of Catalina users compared to everything else.
dander
21:10I'm not a Mac user, but it made me curious about the rate of adoption. [this chart](https://gs.statcounter.com/macos-version-market-share/desktop/worldwide) seems to show last year's release getting to around 50% market share over the course of a year. I would expect that to be a faster rate for developers than typical users. Also, though MacOS [overall market share](https://gs.statcounter.com/os-market-share) appears to be somewhere around 5%, for developers it's [much higher](https://insights.stackoverflow.com/survey/2019#technology-_-developers-primary-operating-systems) ~26%. This is just a from a very brief search, and I have no idea how closely it would reflect the potential Red user pool, so take it for what it is
avitkauskas
21:22Yes, that's true, Mac OS newest version adoption rate is always high, and for developers the market share of Macs is really significant, no doubt about that. I am now learning Red and Red/System with the great interest, but - beeing a Mac user - I have to admit having some taste of sand between my teeth because of this 64-bit question :(
greggirwin
21:31Thanks @dander. Making Red sustainable is a necessary priority, and we're working on plans for that.
BuilderGuy1
21:56That 5%-ish Mac market share is a "global" number. if you look at smaller regions or groups such as Country or State/Prov then the numbers can be MUCH higher (as you have noted)
21:59I just upgraded my 2008 Mac Pro to Majove (10.14) so I will keep it there for the foreseeable future. I want to keep it "Red-capable" ;-) My 2005 MacBook Pro will also stay at Mojave for awhile so I can use Red and other 32-bit applications (that likely will never see a 64bit version)
22:15@BuilderGuy1 I have moved your [NetMarket link here](https://netmarketshare.com/operating-system-market-share.aspx?options=%7B%22filter%22%3A%7B%22%24and%22%3A%5B%7B%22deviceType%22%3A%7B%22%24in%22%3A%5B%22Desktop%2Flaptop%22%5D%7D%7D%5D%7D%2C%22dateLabel%22%3A%22Trend%22%2C%22attributes%22%3A%22share%22%2C%22group%22%3A%22platform%22%2C%22sort%22%3A%7B%22share%22%3A-1%7D%2C%22id%22%3A%22platformsDesktop%22%2C%22dateInterval%22%3A%22Monthly%22%2C%22dateStart%22%3A%222018-09%22%2C%22dateEnd%22%3A%222019-08%22%2C%22segments%22%3A%22-1000%22%7D), as it was spanning over many lines... Please use embedded links in such cases.
22:17@avitkauskas Don't expect the 64-bit support for macOS before the end of the year. In the meantime, you can still use virtualization tools to run Red on macOS after upgrading to 10.15. And we are aware of that change since a long time, but as Gregg said, ensuring sustainability of the whole project takes precedence.
22:19@dander If we consider the red-lang.org visitors, we have Windows: 52%, macOS: 18%, Linux: 10%.
22:20@hiiamboris There is an issue with your commit https://github.com/red/red/commit/375b15f2c7551e58597eda701a947c97dfb71dd2. See my embedded comments. Basically, in its current form, the commit has no effect on the code. So, let me know if you want to change it or if I can roll it back.
dander
23:55Congrats for reaching 4k stars on the Red repo! @dockimbel did you get the 4000th star? 😋
19:55Thanks, in the name of all the contributors! :100:
20:05This morning, I stumbled upon an old [blog entry](http://www.rebol.net/cgi-bin/r3blog.r?view=0139) from Carl about redefining find on objects. In a nutshell, there's a duplication betweenin and find when used with objects. Carl proposed to repurpose find to search among the values instead of the object's words. That sounds like a useful feature to have, so I made a prototype implementation in Red:
obj: object [a: 4 b: "hi" c: 'hello d: 4]
find obj 4
== a
find obj 'hello
== c
The /part refinement is supported, to start the search from a different word/value pair than the first one, allowing to find all the occurrences of the same value within an object:
i: index? find obj 4
== 1
find/part obj 4 i + 1
== d
index? in Red can be used on words, to return the index of the word in a context. As findreturns a word that is bound to the object, we can extract its index that way, increment it, then use it as argument to find/part to start after c in the object. Extra features: /case and /same refinements are supported also.
What do you think about it? Should I merge it in master?
hiiamboris
20:23I guess it's more informative/useful than just returning true/false given a word.
dockimbel
20:28We currently don't have any direct way to do this search on values within an object. We can use reflectors (words-of and values-of), but they create intermediary blocks, that can become a significant overhead when searching through a tree of objects. OTOH, if we add support for foreach on objects, browsing objects becomes much lighter, though, such searching operation would be way slower than having find handle it at low-level. So it looks like this could be a sweet spot.
Oldes
21:49_How many MBs it adds?_ I like it, although I have no idea for which purpose I could use it now.
21:49The _part_ related part is a little bit more difficult to understand.. one have to read it twice. Maybe because I never noticed that index? works with words in Red.
toomasv
03:10@dockimbel Can at be used instead of part like in series, where part restricts length, at restricts start?
greggirwin
03:45I do like the idea of find searching values, so it's not redundant with in, though the intent can be different, which still has value. As far as ordered searches, that makes objects more series like, which is convenient in some ways, but as soon as people rely on that it can never, ever change. I can see a lot of possibilities for this behavior, so it's very tempting.
What about map!? Find searches only keys there, which will make it inconsistent with objects (its nearest cousin). Maps are not ordered, so that will still be inconsistent even if changed to match the new object+find behavior.
pekr
04:49If we are about to break from what Rebol does here, I would like to point out one other (very short) Carl's article, describing the plan to introduce object specs. Would anyone find it useful? Apart from modules and/or field typing, I am not sure I would use it much .... http://www.rebol.net/r3blogs/0350.html
06:25For index? and find/part, It depends on how we define object. If it's defined as an array of key-value pairs has its own context. Then it makes sense to return the index.
meijeru
07:29@qtxie :+1: "it's defined as an array of key-value pairs which has its own context" that is indeed the way objects are best explained
07:35Question: who has relied on the original definition of find in one of their programs? I haven't.
07:36I suppose that is mainly because objects are consciously defined by the user to have a certain, well-known, set of fields.
xqlab
07:43@dockimbel @toomasv I would prefer */skip* instead of */part* or */at*. That's also more like *find* is using it
meijeru
08:28/skip implies jumping over a number of items every time, which has a different effect from /part or /at, as I see it.
planetsizecpu
09:45I 'm not going to argue in the syntax or refinements, but I think is useful. In ordered key-values I see better to look for the value, and return the index as @qtxie says, but in objects you already know the fields, then you may want to look for values.
Just on the fly, I think would be useful on games, for example if some object has some other else, like this:
foreach-face f [
if find face/extra 'wbarrow1 [
... we found some object has the barrow ...
]
]
xqlab
09:55@meijeru Then use */seek* as used in *read/seek*
Oldes
10:08You must use refinements which are already present in find action. If you add a new one, you would have to figure out, what it should do with the rest of supported types.
endo64
10:31Between searching keys and values, I prefer values. But still I can't see much value on this. i have a value and I'm searching its key in an object.. Do we have good uses cases? The only useful use case I see is using /same to find out if that object have a reference to an object or a series.
greggirwin
18:17@meijeru I don't remember using find on objects, and my guess is that little to no code will break with this change.
@endo64 I have used reverse lookups in blocks, but not often. I would have to dig into old code to remember what it was for, but I do remember doing it. I also agree that objects and /same are the first thing I thought of, creating or navigating graphs.
@Oldes has a point, asking about how "expensive" it is compare to value it provides.
I see this as an advanced feature. You deep Reducers out there, put on your thinking caps and see what concrete use cases come to mind. It's not something I've ever wished for, or think many people will use, but sometimes you don't know you wanted something until you have it.
- Reactive scene graphs? - In-memory associative DBs? - Live module change detection in running apps?
Note that we can take a first step and deprecate find on objects. If it's redundant, and we don't see value in the different meaning two words provide. That way we'll also see if anyone complains, because they're using it now.
18:44@toomasv @xqlab Extending find with new refinements is inconvenient in many ways, we need to pick up from the existing ones.
18:44@greggirwin We cannot change find on maps, because there is no in support for maps, so find is the only direct way to [check for a key](https://doc.red-lang.org/en/datatypes/map.html#_reflection) (including its specific spelling using /case). Also, maps are currently ordered in Red, we just don't guarantee that it will always be the case.
18:44@pekr Implementing some of Carl's propositions is not breaking from Rebol. ;-)
18:44@meijeru > Question: who has relied on the original definition of find <object> in one of their programs? I haven't.
I always use in to check for word definition in an object context, both in Rebol and Red.
18:44@xqlab I picked up /part for this usage, as there are precedents where that refinement was already repurposed for special cases. Otherwise, /skip is a better choice, I agree. It is not really an exception from its common usage, as objects are not series.
18:44@greggirwin > Note that we can take a first step and deprecate find on objects.
Yes, that's a valid alternative option.
18:47The "implied index" in /part is still annoying though, I don't like it either, as it introduces an extra concept in objects. The only alternative I see when multiple words refer to the same value, is to return a block of all the words. Though that means find could return a single word or a block of words, your code always need then an extra check for the type of the returned value, and process it accordingly.
greggirwin
18:50@dockimbel map!, right. :^\ We'd have to add map support to in and reword the doc string a bit.
dockimbel
18:53==== On a different topic, we are planning to make some changes in the red/red repo. We want to move the View code into a different repo, but keep it linked to the same place as now using Git's submodules. As View module grew quite big, it's more convenient to manage the related commits, PR, issues, branches,... in a separate repo. Other future modules should also be submodules. As such change has many impacts, we plan to schedule the change on Monday, we should post some extra info tomorrow, so that the concerned contributors get ready for the change.
@greggirwin @bitbegin @rcqls
18:59Other possibility for find on objects: return a block of matched word(s) by default, and return only the first match as word! when /only refinement is used. That way the returned type is then predictable.
dander
19:04Or the inverse /all or /many to keep searching and return all results. Would that be useful for other types?
19:08In that original thread a bunch of people were asking about find/deep too. I've found myself looking for that before
dockimbel
19:18@dander In this case, we need to rely only on the existing find refinements. The /deep addition sounds appealing until you start digging into the details about which datastructure to support and in which way... My personal inclination on that topic goes towards a new search native to cover the many needs of a "deep find" and avoid overloading the already cluttered find.
greggirwin
19:48Returning multiple results is outside the purview of find IMO. That's where HOFs and other helpers come in. Red needs to focus on the basic elements needed to build on top of.
19:49At the same time, some specific features need to be complete. Always choices.
qtxie
19:56> Other possibility for find on objects: return a block of matched word(s) by default, and return only the first match as word! when /only refinement is used. That way the returned type is then predictable.
Looks better than using index? and find/part. So we can avoid forcing object has order.
obj: object [
a: 1
b: 2
c: 1
]
find obj 1
== [a c]
find obj 2
== [b]
find/only obj 1
== a or c depends on the underlying implementaion?
pekr
20:00As for /skip, I mostly perceive it as a skip of certain number of values in a sense of records ....
qtxie
20:01Still is there a good use case? If not, maybe we can make it as a REP for now.
greggirwin
20:16Without concrete use cases, it seems like a premature optimization (even if a cheap one). We can create the behavior with words-of/values-of and replace that later if the need arises. I vote to deprecate find on objects, unless @dockimbel wants to also add in support for maps, for consistency, but this chat has led to a lot of design questions that seem to create more divergent and potentially confusing behavior.
If we rule it out, for now, need need to make a design note ref'ing this chat to remember why.
dockimbel
20:38I'm fine with removing find on objects for now. About in, its primary purpose is binding a word to a context (and testing if it is defined in that context as added value), maps don't have context (and we don't want to make people think otherwise) and keys can be of many different types than words. Moreover, it's not an action, so extending its usages won't work with future user-defined types.
greggirwin
21:20We have the existing meaning, related to binding, but just returning the key if found in a map is a soft parallel to that, usable for chained operations. Unfortunately, it also opens up more design questions, because of a ripple effect. e.g. get expects a bound word, and I agree that's a big complication we don't want. I'm also fine with not having all things work on all types. We have types to provide constraints, meaning, and intent.
21:59@pekr object specs are a deep design topic, and comes back to the difference between interface and instance. Redbol langs are prototype based, not class based (though @moliad built a system to do that), so there is never a reference template the system tracks; it's up to you to do that. This also leads down the path of defining any kind of constraint on values, what trendy devs call Dependent Types. That is, a value that is of a specific type, but *also* has to meet certain criteria, which have to be enforced. For example, an integer value that is positive, or between 1 and 10. Is that a new datatype? A parameterized datatype? Something we enforce as part of a spec, which can be applied to objects, function specs, or even in dialects and messages? I like the latter, because then we generally have a constraints or requirements dialect, which is generally applicable, and is processed by a vetting engine. Then the trick is figuring out how to tie it into other pieces so it's optional, and works naturally.
22:01@rebolek has a nice example [here](http://rebol.qyz.cz/dependent-types.html).
dockimbel
22:30It's often tricky to decide how far to go into polymorphism. Avoiding to break common idioms like get in could be a good guideline.
Oldes
11:19@dockimbel is it really good idea to remove the view part from the main repo?
dockimbel
11:31@Oldes It's not removed, it will still be there as a submodule. That works a bit like symbolic links in a filesystem.
Oldes
11:33Ok... when you are in making changes in the structure, I would recommend not to have source directly in the repository root (in multiple directories). Because as it is now, I cannot use file search without also searching the .git folder, which is big and full of files.
11:36So I would prefer to have in the root folder src and all the folder like environment, modules, runtime ... there
qtxie
11:37@Oldes Can you exclude some folders when searching? I never has problem with file search in the repository.
Oldes
11:38I'm used to Total Commander and I cannot exclude folders
11:40Above search is also done on all files inside .git folder, which is wasting time.
11:41Problem is, that once you will add submodules, it will be same situation as the module will have own .git folder :/
11:48@qtxie I can search inside each folders separately, but not everybody have same knowledge where to expect what like you most probably have.
qtxie
11:52I use the search feature very often in my editor. I think it also search all the folders, but it's very fast. So I didn't notice the problem.
Oldes
11:54It is just that you are touching the structure of repository. I think that some more cleanup would be nice too, for example all the Rebol files in many folders... like /, build/, utils/, system/utils/ etc.
11:56Moving just the modules/view folder to separate repository is just strange. Especially that content is very small in comparison with projects having GB of files/data.
12:04Not mentioning that you will have to update the submodule making commits in the main repo.
GiuseppeChillemi
12:05@greggirwin >> Redbol langs are prototype based, not class based (though @moliad built a system to do that)
Where is the @moliad project ?
dockimbel
12:48@Oldes Like Qingtian, I use the search feature of my code editor and it's extremely fast. I use a filter on *.red *.reds *.r files, so that non-source files are not processed.
12:52@Oldes We are *not* changing anything in the structure of the red/red repository with the creation of the View submodule. Maybe you misunderstood what Git submodules are.
12:52> for example all the Rebol files in many folders... like /, build/, utils/, system/utils/ etc.
What's the problem with that?
12:54> Moving just the modules/view folder to separate repository is just strange. Especially that content is very small in comparison with projects having GB of files/data.
It's not about the absolute size of the files. I mentioned some reasons in my first post: "As View module grew quite big, it's more convenient to manage the related commits, PR, issues, branches,... in a separate repo."
12:55Just the issues management alone would be enough to justify that change.
Oldes
12:55Looks a little bit messy. I just wanted to say my opinion. The same thing like with the submodule. Maybe I'm just different.
dockimbel
12:57I don't understand how putting together files that relate to each other is being messy... Maybe our organizing rules just differ.
13:38I am not against a refactoring of the repo by principle. If there's a better structure, it needs to provide substantial gains, because such change would be costly.
pekr
14:12I am not sure how far are we from eventual 0.6.5 release, nor if it will already introduce the reverted mode, where the console is a base, but I have one question towards the console experience. I think I brought it up in the past too, but don't remember the outcome. It is related to printing/emitting to console and its refresh:
repeat n 1'000 [print n]
Now - I know it is quite minor disturbance, but what I am seeing, is a flashing scroller bar, no console movement and then the result appears in the end.
14:13As I said - I don't want to upset you guys with such minor concerns. It is just that I do remember some memorie towards Smalltalk (pre-rebol days) and Amiga consoles, color codes, etc., and if I am not wrong, Red plans on console plugins or even allowing some advanced stuff to make it kind of a code editor?
22:12Thinking about having AI in RED since a couple of months. What about a NEURON datatype ? It's intenal elements and connections to other nodes could be rapresented as custom series and blocks.
greggirwin
01:04AI elements will be modules, but the first step is always to think about how you *wish* you could do things, and then write the dialect that lets you do it that way. :^) In Red we can solve things in many ways. There is the data aspect, which doesn't mean there have to be datatypes for them. Remember, datatypes all implement a common set of actions. In an AI context you have something like a reactive push system. We can absolutely set up a wiki page for notes, and @ameridroid and other experts can weigh in on the domain language, elements, and what can be done in Red versus what needs R/S performance.
GiuseppeChillemi
07:13Talking about datatypes, I sometime ask to myself if would it be so difficult to expose the action layer of datatypes and implement the ability to add actions code to manage new datatypes or replace existing one.
xqlab
07:37@lucindamichele I'm fine with blocks. If I want pretty output or record like behavior I can use \skip with newlineor other functions
pekr
07:50@lucindamichele As I have already told to @rebolek, as an authoer of the CSV codec - I have to think about it more, as I find it rather complex. I know it tries to cover many scenarios, delimiters, etc., but all those years, working with a CSV data, I was mostly OK with just few lines of the code, which felt as oneliners - read/lines data.csv, parse data ";", remove the first element of block, if there is a need (column headers) and on the output side, looping via foreach [field1 .... fieldx][... write/append ...]. Sure, mine aproach covered just mine generated CSVs, semicolon separated ...
rebolek
08:21@pekr you can use to-csv and load-csv and not care about refinements at all.
08:23However you simple example parse data ";" would fail on a lot of real world examples. You really need more complex handling.
greggirwin
08:26@GiuseppeChillemi what is the driving need for that feature? That is, what *can't* you do today that makes you want it?
08:28I was trying to follow "simple things should be simple complex things should be possible" principle.
pekr
09:48Once again, I have nothing against the particular implememtation, just trying to point out, that an underlying implementation seems a bit complex and sometimes we can see even simpler stuff being revoked for its seeming complexity. But you are right, I have only historically used one concrete scenario ...
09:51What I am not fully about to consider, is those various record/block modes. Are we sure we will use similar options for SQL/ODBC codec?
rebolek
10:20The underlying code is more complex than simple parse data ";"because it has to correctly handle escaping, custom delimiters and other stuff. Just read this for some fun :) http://secretgeek.net/csv_trouble
10:22Various record/block modes - this is where I'm mostly interested in user input. I can throw out ~50% of code and support block of blocks only. But I believe other modes have their purpose.
GiuseppeChillemi
12:21@greggirwin RED datatypes could be used as building block for quite everything, I agree. But when you create complex structures, simple operations like select/next/back/tail/at and PATHs are no more directly usable on the work and the target data. You have to add more steps making your expression convoluted. A datatype which add code to the basic actions let you create shorter code and done with the very basic of RED words and concepts. It's not a matter of "show me what can't be done", it's a matter of simplicity while expressing and manipulating data.
12:49note: are no more directly usable on the work and the target data -> are no more directly usable to work on the target data
xqlab
13:25The help text of load, save and other funtions with the /asrefinement should show all possible encoding types.
rebolek
13:34@xqlab you can get all available codecs from system object:
13:41That is how CSV works. One should not use it when don't have to talk with foreign apps.
9214
13:42@xqlab codec is not supposed to load all possible values, that's beyond its scope.
rebolek
13:43 @xqlab yes, that's intended. Functions that try to convert values to appropriate datatype may be added later (or may not, that's not decided).
xqlab
13:44system/codecsdoes not show UTF-8used with readand write
Oldes
13:46because read and write don't use real codecs for now. They were there before first codec implemented.
GaryMiller
14:46In real world large data load application CSV files most often can be comma, delimited, pipe delimited, or tab delimited. Some csv files have comment character such a # in the first column position of the record used to document different sections of the CSV file. # is commonly used but is often redefinable to handle files created by other systems. More and more often UNICODE characters in strings being loaded are occurring. Embedded single quotes within double quoted strings are common and to be expected as column delimiters such as commas. Both integer values and floating point numbers are often included. Most Python CSV handling reads the csv file and maps it into a list of objects where the object attributes are the column names. Numeric values are mapped directly into numeric variables to avoid data conversion overhead later when processing.
> CSV files most often can be comma, delimited, pipe delimited, or tab delimited.
CSV codec uses comma as default, different character can be selected using /with refinement. I did some work on delimiter auto-detection, but that’s experimental feature, not available in master branch.
> Some csv files have comment character...
Thanks, I’ll look into it.
> UNICODE
If the file is UTF-8, Red handles it well.
> Embedded single quotes within double quoted strings are common and to be expected as column delimiters such as commas.
Quote chars are fully supported, you can choose if you want to use single or double quote (or something different, if you want).
> Most Python CSV handling reads the csv file and maps it into a list of objects where the object attributes are the column names.
This can be achieved with /as-records refinement.
> Numeric values are mapped directly into numeric variables...
I need to run some test to see how much code it adds, and how it will slow down the conversion.
greggirwin
18:41I thought about comments as well @GaryMiller. It's a bit of a pain to work around with remove-each read/lines + rejoin, but as we talked about more options, the number of refinements grows and we end up looking at deeper changes, which are probably not where we want to go. e.g. load/as could take a spec block as the type arg, which contains option settings.
Auto-loading fields is another deep design question, which we discussed. Either you take a big hit by processing *every* field, or you add another option to guide what to load. @GaryMiller do you happen to know, or know who to ask, how Pythonistas feel about their CSV solution? We're happy to learn from their experience.
18:44@xqlab the current doc string has e.g. to denote that not all codecs are listed. However, there's a precedent with checksum which *does* list them all, and that can be useful. A big difference is that checksum is a fixed func, while the codec system is dynamic. As soon as people start writing their own codecs, the doc string either has to stay incomplete, or be dynamic itself, when a codec is registered. If we keep the standard codecs small (and we should), I agree that listing them all there is a good idea.
19:06@GiuseppeChillemi can you *please* give me a concrete example of what you want to do, that makes the datatype solution more expressive. That will help me a lot, to understand what's in your head.
This is a good general design note as well. For me, the greatest benefit from Red's wealth of datatypes comes from their literal forms, by far. It's like a periodic table. And lexical space is tight. We're already seeing limits on new forms without adding special characters and sigils that are less human friendly. People can, of course, but remember that new forms also mean changes to the lexer, which is not something we can easily make dynamic and robust. *We* need to define Red's syntax, for interoperability and longevity. And for our own sanity. :^)
Having spent a fair number of years doing OOP, I do know what that view looks like. But nobody has proven that it's objectively better. It's good for some things, but not for others; most of the time it's just different, not better or worse.
There's a great book by Bertrand Meyer, an OOPer if ever there was one, called Reusable Software. In it, he argues for naming consistency. He explains it as a Linnaean Classification model. Things are grouped because they share common characteristics, and you use the same names to talk about them. An example is the series in Red. We have insert, append, remove, take, etc., which work the same on all of them. We don't have enqueue/dequeue and push/pop, and we shouldn't. You can write those, when you want the meaning, but you don't need new queue!/stack! datatypes to do it. It's tempting, I know. I've done it.
The interesting thing, and where Red's difference comes into play, is that Red is *aaaaalllll* about the data. How that data is processed is context sensitive. OOP, and the idea of adding more datatypes with associated actions, conflates data and behavior. Of course, we do this too, and have objects, rather than a strict separation at all times. But our objects are different. Datatypes are static by design, while objects are really data containers and some of that data is evaluated for its behavior (e.g. functions). You can do the same thing with blocks, though you lose the implicit context aspect of the words in the object. That is what makes Red special, so it's key. Of course, we can mix and match and create any other system or model on top of this.
As to your thought (I know it was a question, not a feature request), it leans toward [this](https://github.com/red/red/wiki/%5BDOC%5D-Red-Should...-(Feature-Wars)), where it has to be thought about deeply, and championed by someone who really wants it.
GaryMiller
19:15@Greg Irwin Pythonistas used to use the standard library. But for big jobs now they usually call NumPy or Pandas which are much faster since they are based on optimized statically compiled code. Invoking them is usualy a few lines shorter than the standard library. This article gives a comparison of the three different approaches. https://machinelearningmastery.com/load-machine-learning-data-python/
meijeru
19:43@GaryMiller Please be careful with @-names; your above post was signalled to a totally different person than you intended, and who probably does not know what to do with it...
I often have to redo @ names because Gitter selects the wrong one.
20:35Some good considerations in that article @GaryMiller.
- The most common format for machine learning data is CSV files. (if that's true ;^) - Pandas lets you specify names to go with the data, if they aren't included. I don't know what the result looks like, but we don't have an option for that, which would go with as-records/as-columns. - A comment talked about auto conversion errors. Once we have HOFs, mapping conversions will be short to write, and shouldn't suffer a performance hit, compared to doing it inside the codec. Looks like numpy has a converters option for this.
Reading more: - https://docs.scipy.org/doc/numpy/reference/generated/numpy.loadtxt.html - By default you get back a block of blocks (in our world). - Numpy has an unpack option, which transposes the result and lets you assign it, like so: - Lots of args for loadtxt, which is the problem we face, and they're only concerned with the numeric view.
obj = StringIO("1, 2, 3\n4, 5, 6")
n, m, p = np.loadtxt(obj, delimiter =', ', usecols =(0, 1, 2), unpack = True)
print("value of n: ", n)
print("value of m: ", m)
print("value of p: ", p)
; Output
value of n: [ 1. 4.]
value of m: [ 2. 5.]
value of p: [ 3. 6.]
This is the crux of the issue, and why CSV is a great and terrible thing. It's used for 3 types of data, none of which is "the one". - Spreadsheet model: rows, cols (named or numbered), cells - DB Model: rows of records, often with named columns - Column model: pivoted spreadsheet model.
As I commented on the PR at one point, if we *have to* pick only one, it has to be a block of blocks. The question is, are we better of minimizing the codec and putting all the other logic in a module? i.e., load/as will *only* return a block of blocks. *Ever.* The rest is up to a blessed module or users themselves.
Your mission, dear community, should you choose to accept it: Mock up what that looks like in your mind. What's the best design if we go that way?
rebolek
20:43> specify names to go with the data, if they aren't included
if names are not included, they are currently auto-generated, adding support for custom names, is very small change
greggirwin
20:43A small change, yes, but another user-facing option.
21:02You can also process multiple CSV files from inside of of one zip file like this
with zipfile.ZipFile('file.zip') as zip: with zip.open('file.csv') as myZip: df = pd.read_csv(myZip)
greggirwin
21:05I would like a standard zip codec, but it's not a great fit for the codec model by itself. It could load the content info, but then we need supporting funcs to do something with them, unless load returns a full object that includes them, making it a *much* more complex codec. So zip may be a module, as convenient as it would be to build in.
rebolek
21:16Archives are a better fit for ports than codecs.
22:17@greggirwin Thanks for your long answer. The real fact is that I have many ideas and usage example trying to combine into my mind but I am somehow intimidated from the high level odience. Also my other fear regards a psychology effect: one you introduce something and start receive the first negative feelings and answers becouse you are not good at introducind ideas, it will be harder to let other see them as positive later. So my wish was to make a good presentation to not damage the ideas with my errors (if the ideas are relly interesting). Ok, yes, I should win my fears and write about my views and let other go beyond my "simple" words and errors. I need a more little courage and write down my thoughts.
04:23@GiuseppeChillemi @greggirwin If we care only about meanings we can do this (at least in the interpreter):
stack!: block!
; block!
push: function [s [stack!] x][append s x]
; func [s [stack!] x][append s x]
st: make stack! []
; []
push st 1
; [1]
push st 2
; [1 2]
greggirwin
05:42That way lies madness. It won't keep you from passing a block you don't intend to treat as a stack. And it will create the false impression that it has stack-like behavior. The helper funcs (e.g. push/pop) are enough.
xqlab
06:34@greggirwin If the doc string does not contain all codecs it can contain at least a reference where to find them e.g. *see also system/codecs*
06:37 I prefer simple block over block of blocks as long as there is no native find/deep
greggirwin
07:47@xqlab something like "For full list use extract system/codecs 2"?
07:49And I hear some brain cylinders pumping now... Can we embed code in doc strings for help to use? ;^)
>> ? now
USAGE:
NOW
DESCRIPTION:
Returns current date and time (17-9-2019, 9:55).
07:56It would be security risk, but cool one :smile:
xqlab
09:29The description how to get the information without automatic execution should be enough or maybe a refinement help/reduce ?
Oldes
11:18:point_up: [September 16, 2019 3:04 AM](https://gitter.im/red/red?at=5d7edf952e8fd94630dcaa97) I consider Red's AI orientation to be much more interesting than the blockchain orientation. I wish I could help, but it is very complicated task:/
11:23I'm using just now [ESRGAN](https://github.com/xinntao/ESRGAN) for one project and I'm doomed to use Python, which I really don't love. When I installed all dependencies to be able train my own model, I ended with Python using almost 9GB on my filesystem :-/
GiuseppeChillemi
12:01@Oldes me too. I have many more usage scenarios in companies than blockchains. However, blockchain technology in RED is a reality so we have this thech too !
9214
12:10@Oldes conceptual excerpt about potential AI framework does not define project's orientation in any way - at best, it's a community effort that, if initiated, can be sponsored by Red Foundation. We still have general purpose language to build before considering if machine learning hype has any leverage for Red at the core level.
12:14There's another idea that circulates around since the last RedCon - to build a small neural network that sits on top of memory allocator and applies various garbage collection strategies to fit your program's profile.
So, instead of boo-hoo-ing how we picked for a ride one wave (blockchain) instead of another (machine learning), any local AI expert can take that idea (or the one that @Respectech described in blog post), work it out, and bring to Red what he considers a crucial missing piece of modern tech, maybe even tying it with blockchain-based economies of autonomous actors (potentially becoming rich and famous in the process... or not, but you still have fun).
GiuseppeChillemi
13:15@9214 I actually have more ideas on AI than blockchain. As of blockchain boo-hoo-ing, please understand that while we are all AI and we have tons of ideas about how an artificial AI could help in our life, blockchain is an obscure tech and our brains are not producing any idea on it. AI is intuitive for us, blockchains is not. Maybe some GURU could open our eyes and provide us his vision on this tech and explain why it could be useful in day to day normal and professional life. Actually I feel rater blind on it and this is the admission of my ignorance on the whole blockchain matter (and I think many of us). I feel that you, as deeply skilled professional, have more to say on this topic or point to the proper resources that will open my (our) eyes and build a bridge torward the future.
1) AI is artificial intelligence, so artificial AI is artificial artificial intelligence. And no, we're not AI, in better case we're I, but I'm not sure about that.
2) It's not AI even, it's just machine learning.
Oldes
13:26@GiuseppeChillemi for me is machine learning same magic as blockchain... I just commented because I'm right now using it. Maybe I should keep silent.
13:27There's nothing magical about blockchain. It's append-only DB with hash of previous data for consistency check.
Oldes
13:27I just don't want to be _boo-hoo-ing_ (whatever it means).
9214
13:31@rebolek I in modern AI falls flat on me. Bottom-up approaches and emergent computation (esp. in the context of agent-based robotics) makes much more sense IMO.
rebolek
13:32But "intelligence" sounds better, doesn't it? Same way as "cloud" is better marketing than "someone else's computer".
13:35@Oldes "boo-hoo-ing": https://www.dictionary.com/browse/boohooing. It's what we do as child to obtain something. "We want AI, pleeeaseeee, its better than blockchain ! I want it nooowww" (Please pronounce it with the tone of a complaining child !)
13:36@9214 Yes, it sells a lot. Even a toaster with AI will get attention and funds now in Italy, I don't know how is where you operate.
13:38@Oldes I should keep me silent too on neurons implemented as datatypes but it created a wave of interesting discussion on all of us. So, keep speaking !
13:44@rebolek We are multi layered AI. Moder AI is machine learing operting on a specialized topic. While humans are a multiple thinking adaptale AI that integrates and coordinates many specialized AI systems. We are able to abstract, create while articifial AI (machine learning) is not.
13:46Back to blockchains, as anyone of RED developers good learning resources to let our eyes open about this topic ?
rebolek
13:48@GiuseppeChillemi how are we **artificial** intelligence?
13:51@rebolek We are all AI when we believe we have been created from an higher entity. He is Natural Intelligence while we are his Artificial Intelligence ! (ok Vladimir, you are right , I am stopping here!)
dockimbel
14:23@GiuseppeChillemi No religion, no politics in this channel. This is not Youtube nor Twitter.
14:26On a practical side of things, I would like to see async IO, network protocols, db protocols, concurrency, some more codecs (XML, JSON), db-grid, continuous small gui advancements and some more targets down to some embedded systems. All that, before AI, as nowaday, most stuff out there is just an AI hype. So, in my book, Red is on a good track, of course it will take some time to get there ....
dockimbel
14:28Just a short remark on the discussion topic above: AI and Blockchain can be related, AI can give birth to autonomous systems, and a blockchain can make them economically viable.
pekr
14:29Of course I am glad stuff like RedCV exists, it is a nice example of how Red ecosystem could be extended. It's about small usage scenarios, like e.g. creating a camera app, doing some "OCR" and reading card registration number plate, storing it into db. That's just one example my friend was looking for lately. The trick here is, that Red as a project, has to stay vital and sustainable, so the focus might be just different to the wishes of some of us (not necessarily mine).
> AI can give birth to autonomous systems, and a blockchain can make them economically viable
Should we perhaps share a banana-pancake tidbit back from July?
pekr
14:33As for AI, my remark about "everybody and your mum is doing an AI" was related e.g. to the photo business - this year, every SW vendor is introducing some "AI" stuff there. It's just automated masking, object identification, sky replacements, relightning images, etc. Not all of that should be regarded being an AI. For that, I have better example. We've got a call centre and our company wanted to know our clients sentiments, reason of rental termination, etc. So we have found one Czech company, Sentisquare, who digitized phone calls (run it via a MS or Google service) and created a special graph - their machine learning technique is working with language vectors, contexts and the results we've obtained were very interesting.
dockimbel
14:42@9214 We can keep it for some future article. ;-)
14:57And about XML - writing parser is simple. How to interpret parsed data in Red, that's the hard part. CSV supports four modes because of this. And because of JSON, Red changed none handling in maps. So XML... who knows.
Oldes
14:59@rebolek it is not able load real life ugly json file:
15:09Regarding XML, I was using [this XML parser](http://www.rebol.org/view-script.r?script=xml-parse.r) in Rebol.
GiuseppeChillemi
15:21@dockimbel No intent of discussing religion in my words. Just a word in a(i) context.
16:01@rebolek Is there a discussion or documentation about the NONE handling in maps you can point me to ?
dander
16:50@Oldes you may already know, but comments in JSON are [not part of the JSON spec](https://stackoverflow.com/questions/244777/can-comments-be-used-in-json), which means that JSON file is malformed. But people _do_ really want them, so it's probably fairly common to encounter... So then the question becomes, what is the best way to handle malformed JSON in Red, or would we want some sort of less strict parsing?
We will proceed with the split between red/red and red/view on Wednesday 18th at 16:00 UTC. For your local TZ:
do [d: 18-Sep-2019/16:00:00 d/timezone: now/zone d]
The modules/view folder will then become a git submodule. If you have pending View commits, you should send us the PR before that deadline, or have to manually patch back your changes in the View code afterwards.
@x8x We need to update the server scripts and CI scripts around that time. We'll take care of updating the README file.
@rcql @bitbegin We will move the red/GTK branch to view/GTK after the deadline expires tomorrow.
18:10@greggirwin > That way lies madness. It won't keep you from passing a block you don't intend to treat as a stack. And it will create the false impression that it has stack-like behavior. The helper funcs (e.g. push/pop) are enough.
I would say "it's user responsibility to pass correct argument and use correct functions" but somebody may not like this. On the other hand, functions (like push/pop) don't tell you exactly what kind of types you are using/changing.
Oldes
18:11@dander no.. I don't know it.. I just tried to load first JSON file I found in Red and it failed. I would support it.
giesse
18:31@Oldes have those been reported? Please note though that comments is not valid JSON - in fact it completely kills the original idea of JSON; but if it's been standardized I'll add support.
18:32The XML codec is in the works ( https://github.com/giesse/parse-markup ), if you guys have any examples on how you'd like it to work, let me know.
18:34@Oldes just for the record, in over 10 years of working with JSON I've never found a JSON file with comments. You surely are one lucky fellow :P
dockimbel
18:35@Oldes If you look at github's [own rendering](https://github.com/victorca25/BasicSR/blob/master/codes/options/train/train_ESRGAN.json) of that JSON file you've pointed out, you'll see the red overlays showing up invalid JSON parts. Comments are not part of JSON format.
19:05@hiiamboris About your Red stack related post :point_up: [September 10, 2019 9:59 AM](https://gitter.im/red/red?at=5d7757df3b1e5e5df184db0d):
> It's filled manually item by item in various parts of code, sometimes recursive code, then gets modified by the many functions you call from that code (and the functions called by those functions).
I don't understand your point here. The stack is a working place for Red functions, so it's heavily used in many different places, as a lot of processing happens on the stack.
> So basically it's impossible to predict what will happen to the stack by just looking at the source. As an example if anybody will be able to follow how the stack works inside do-print in less than 2 hours, I'll applaud him :)
You are making a generality from a specific case (and you've picked up one of the worst). Fortunately, it's not that bad, even though the current stack handling is not fully satisfying.
> So, can you add a (debug-mode) feature that would check the Red stack (or any data referred to by another pointer) layout declaratively and report if anything's amiss?
I don't see how that would be helpful. Which problem are you trying to solve with that?
19:05FYI, we have plans to improve the Red stack, merging together the current dual stack we're using into one and incorporating some dynamic aspects (in a simplified way compared to early work I did in [dyn-stack](https://github.com/red/red/tree/dyn-stack) branch). Though, the fundamental inner working of the stack shouldn't change much, we still need stack frames, so the stack layout would still depend on the Red code you are currently evaluating.
greggirwin
19:08@xqlab what about help/deep rather than help/reduce?
19:17On JSON, the Red codec is based on the old Rebol JSON library, created by Romano Paolo Tenca, and which I maintained for many years. When Douglas Crockford removed comment support from the JSON spec, I chatted with him about it, and asked if they would ever come back, and about his reasoning. He was firm that they would never come back, and that JSON was *not* meant for humans to use that way. He removed comment support *because* people were using it "incorrectly". This, of course, leads to "If that's how people want to use it, maybe the spec should change." Design is hard.
If you have a JSON endpoint that includes comments, maybe someone can whip up a helper func to preprocess content like that. But since they aren't in the spec, you can't know what people will use for comments. Could be //, /*...*/, or both.
Oldes
19:17@dockimbel most probably because nobody from JSON community cares like [Rocket community did](https://github.com/github/linguist/issues/1717) . I can say just say that comments in JSON are common and not being able to load such a files without preprocessing these first is a bad move. But I quite used that I have different opinions often these days.
19:19Btw... I can remind, that I'm standing behind the activity, that there is any color in Red code on Github https://github.com/github/linguist/pull/1150. I was trying to fix it here on Gitter too, but I have not enough patience for it anymore.
greggirwin
19:24On XML/markup, please do comment on @giesse's work. He's waiting on comments from me, as once we started talking about it, I wanted to take some time to think about how to unify some things. There is no perfect solution there, just choices, but I hope we can look at structures/trees like that with an eye on HOFs and processing them as evented streams as well. The fundamental pieces are: navigate, query, select/filter/FLWOR, and transform. I've made notes and read quite a bit on XPath/XQuery/XSL/XSLT, their HTML/CSS/JQuery counterparts, and of course the DSSSL origins.
In some ways it feels like wasted effort, because it's such a pain and everybody uses JSON now, right? On the other hand, there's still a lot of XML out there, and getting this design "right" could show what Red can do to ease the pain in specific domains.
Oldes
19:27Here is the unfinished Gitter pull request for Red code: https://github.com/highlightjs/highlight.js/pull/988 In case someone want to contribute.
greggirwin
19:27@Oldes, et al, here is the comment support from the old JSON lib:
19:28I know... it is easy to have it there and I don't understand why you don't want to support it
19:29But I'm not using JSON (withing Red), so I don't care much.. it is just that one can have bad feeling when it throws an error on file, which is commonly used, as I had when I tried to load my first JSON file.
greggirwin
19:30Because it's not in the spec. I know Postel's law but specs exist for a reason, right? What we have to figure out is how common this is, how it affects people, etc. Set up a JSON wiki page where people can add their name to a petition, and have to include the source of the offending JSON, so we have some data to work with.
Oldes
19:31Apparently people want to have comments there.
There is no comment in JSON specification, so it means that people can use whatever they want for specifying comments. So how many different comment syntax should a JSON parser support in order to be fully non-compliant with the JSON spec. ;-) Moreover, even Crockford (JSON's author) is [against them](http://web.archive.org/web/20120506232618/https://plus.google.com/118095276221607585885/posts/RK8qyGVaGSr).
Oldes
19:32We are talking about being able to load the file, right?
dockimbel
19:32An invalid file... I wonder if the top JSON parsers in other languages are all supporting comments, and which ones?
Oldes
19:33Sorry.. I give up.. do whatever you want, but if I would like to load JSON, I want it with these type of comments.
19:34:point_up: [September 17, 2019 12:10 PM](https://gitter.im/red/red?at=5d812199577fc14c7fe068b3) @nedzadarek the issue I have is that simply aliasing block! and stack! is that you're lying to the user. If the semantics are the same, aliasing can be a win, but if the behavior is different it's a hurtful lie. ;^)
Oldes
19:34And main author of the project I work on now moved from it to yml https://github.com/xinntao/BasicSR/blob/master/codes/options/train/train_ESRGAN.yml
greggirwin
19:36@oldes, don't give up. Convince us with data. Find all the examples you can and put them in a wiki page, so we can evaluate.
19:37> The needs of the many outweigh the needs of the few.
:^)
dockimbel
19:38@Oldes You can't blame us for willing to be compliant with the JSON [specification](https://stackoverflow.com/a/4183018/2081311). If all the other JSON parsers in the mainstream languages are supporting /*..*/ and // comments, then it's a de-facto standard that we need to support also. But, as Gregg said, we need data, not opinions.
Oldes
19:38I don't want to convince you... I just know, that it is much more easier to remove these when you load the json, than writing any type of preprocessor and do the job twice. _Go ahead and insert all the comments you like. Then pipe it through JSMin before handing it to your JSON parser._
greggirwin
19:40@oldes, preprocessing is an extra step, yes, but if we auto-strip comments, you also can't tell if the JSON is malformed, because it contains comments. Now, if you want to know that, you need a separate linter, correct?
19:41As I expect we agree, caring about that is probably rarer than comments, but we don't know how common comments are, do we?
19:42But let's focus on CSV. It has a lot more we can argue about. :^)
Oldes
19:43If you really care so much about specification, you can add options to the codec.
19:43I'm not going to write any wiki.. all you want to know is [here](https://stackoverflow.com/questions/244777/can-comments-be-used-in-json). There is [list of parser supporting C-like comments](https://stackoverflow.com/questions/244777/can-comments-be-used-in-json/7901053#7901053)
greggirwin
19:43If we care about the spec, we would adhere to it.
19:46From that SO link, it looks like comments aren't supported, and workarounds are suggested.
19:47If you want to use specific comments from SO, start at the top. :^)
nedzadarek
19:47> :point_up: [September 17, 2019 12:10 PM](https://gitter.im/red/red?at=5d812199577fc14c7fe068b3) @nedzadarek the issue I have is that simply aliasing block! and stack! is that you're lying to the user. If the semantics are the same, aliasing can be a win, but if the behavior is different it's a hurtful lie. ;^)
@greggirwin ok, stack =/= block but if you use certain, correct, functions then it's not that bad. I think.
greggirwin
19:48@nedzadarek I stand by my statement that it is madness. It's like incorrect comments being worse than no comments at all.
19:51@oldes, so it looks like there are 3 that support it. Looks like there are ~150 libs listed on https://www.json.org/.
All this said, if, and that's a big *IF*, having this feature wins us hearts and minds, because it's better than what others do, then we want to do it. But I'm not convinced it is.
Oldes
19:53I don't know how many supports it, I just took it from the SO link. Reason why people want to use C-like comments is to be able quickly remove some parts... like in configurations, but still be able to put them back quickly
19:54But I really end... I don't care. I just don't understand the reasoning, why you don't want to optionaly support it, when it is so easy to do. Your choice.
dockimbel
19:54I think we should just look at the top JSON libraries from the top 5 mainstream languages. From the few links I just followed, as expected, it's a mess, as each lib implements its own rules, some support only //, other support // and /*...*/, other support #, // and /*...*/ but no inline comments(!)... total mess..
Oldes
19:55When I look at it with argument, that Github don't colorize these correctly, apparently SO recognize these as comments in the link above.
dockimbel
19:56If we support comments in JSON, I want our own unique flavor, with additional support for ; and comment {...}. ;-)
Oldes
19:56Actually I think, that codecs should have options.
dockimbel
19:58@Oldes Which SO link? Does that code use a JSON tag for SO to parse it as JSON, or does it use a generic code parser?
9214
19:58@dockimbel generic parser, judging by CSS class.
nedzadarek
19:59@greggirwin using 1 "type" for many different things might be not the best thing as well... but it's a topic about other/custom types that we have talked about, as fair I know.
greggirwin
19:59> I just don't understand the reasoning, why you don't want to optionaly support it
- The R2 lib has been this way since at least 2008, and nobody has ever complained. - It's not in the spec. - Even if easy, it's a non-issue until we have some data to justify *not* following the spec. - Making it optional makes it less easy. - Only a few other libs do it, which says that there hasn't been an outcry over this.
20:03I vaguely remembered seeing it somewhere recently. ;-)
greggirwin
20:03<hehe> :^) It came up while hashing out how to handle CSV options.
Oldes
20:03@greggirwin nobody complained because nobody sane would have reason use JSON as a configuration file for a Rebol script.
greggirwin
20:04@Oldes, OK, you have only 4 more reasons to refute now. :^)
Oldes
20:05I don't mind... I would use codec which strips such a comments for me and not your. There is a reason why there is not just one JSON lib and there must be 150 of them.
greggirwin
20:05OK, I've given you the code for that. Case closed?
pekr
20:10I can understand both sides, but e.g. - original (or maybe still valid) e-mail RFC specs did not support dots, so something like name.lastname@email.com is/was not valid AFAIR. Yet it it most common format of corporate e-mail addresses nowadays. Another example was Rebol's ignorance of supporting @ in the URL login part for FTP. I had to use patch for that in user.r, or something like that. Another one - read http://www.idnes.cz in Red - honestly - I don't care about some invalidity of the UTF-8 used there - each browser simply displays the page. Red chokes on that. Because of what? Because we want to stay 100% pure on definition? So - I can understand that Oldes might not have willing to fight that, if we can see, that keeping things pure to definition defies the practical merit of things, things we always wanted to keep simple for ppl to use.
20:19I don't remember the name of the guy, who run Reboller of the year award. He proposed load's ability to just load any source, unrecognised stuff being relaxed. IIRC Geomol tried something similar with his World lang close, was it called a quatz! datatype? Don't remember anymore.
dockimbel
20:21@pekr You don't care about having some unreadable parts on a web page displayed in a browser, but I am sure you care about having 100% correct results on your server when some script is doing some HTTP queries and processing the responses.
pekr
20:22I also know that the language design is a deep discipline. And especially with Rebol-like langs, where every single think gets deep thinking. So consider my comments being purely user drived. I am not claiming anything being wrong with how things work. Just trying to find out the balance of practical usability and eventually supporting some edge cases.
20:23I know it is tricky. For now I will have to find a workaround. Most probably a read/binary ... and then, not sure what exactly yet, how to parse it :-)
20:24I am sorry - tooo long away from even practical scripting .... but will have to parse some web content in coming week, so will definitely give Red a try on a practical side of the things ...
dockimbel
20:24@pekr It was Brian Tiffin. We had a long discussion here (the same we had on Altme years ago) about the impossibility to meaningfully parse arbitrary input strings.
pekr
20:26Yeah, it was him, thanks :-) I never felt the need to just "load anything", which sounds strange now claiming, that readshould just read anything too. For completly foreign formats, I would not use load, but readinstead and custom parser ....
Oldes
20:28@dockimbel content of the page is completely correct. It is just that Red is not doing required conversion from windows-1250 to utf8 and instead just throws an error.
pekr
20:32Aha, so read/as could fix that, if there would be some simple "codec" or whatever? But then I would have to read the header first, learn the encoding and use appropriate codec?
dockimbel
20:35@Oldes We never said that read supported anything else that UTF-8, that's the only external text format supported for now.
nedzadarek
20:37@pekr :+1: things change, adapts to the current needs.
dockimbel
20:37@pekr No, the encoding of HTML pages can be extracted for you in such case. And it's not an "error that needs fixing", it's just non-implemented features yet. And there are simple [workarounds](https://stackoverflow.com/questions/43379932/access-error-invalid-utf-8-encoding-ffd8ffe0/43383454#43383454) in the meantime.
20:39@pekr you would have to use read/info/binary http://www.idnes.cz in Red.. parse the header and decode the binary if you know how.
dander
22:42looking at @giesse 's [parse-markup](https://github.com/giesse/parse-markup), I notice that it handles HTML, which has got to be WAY worse for consistency than JSON. It even has a garbage rule. Rather than adding support for various non-standard comment formats, could the JSON codec instead be able to ignore garbage values in certain areas?
I believe the more robust Red is the more successful it wil be. Reading JSON files is an area where robustness is beneficial. It is clearly sensible to consider applying Postel's Law here - to paraphrase - be liberal in what you accept from others, be conservative in what you provide to others.
So Red would be more robust if it accepted JSON with ("illegal") comments but never create JSON with comments.
greggirwin
01:30If these were easy choices, they'd be done once and everyone would agree. But they are *choices*.
I mentioned the robustness principle earlier, but here's my argument against it in this case.
Where there may be ambiguity or optionality, being flexible (liberal) is within the bounds of a specification. Where there is a clear specification, and something doesn't conform to it, it's incorrect, either intentionally (maliciously) or not. Can we all agree on that?
If so, and also that JSON is a data interchange format by design, with a clear specification in this regard, can we agree that anyone including comments in their JSON is *intentionally* non-conformant? I'm a fan of comments and self-describing data in general myself, and I'll *guess* that the majority of those cases are using JSON for config data, not what it was designed for.
If we agree on those two points, can we finally agree that just because Red's standard JSON codec doesn't support comments in JSON, that if someone *really* needs them, it's easy to do themselves? We can even provide the code as an example of *how* to do it, with the example code I posted above, or a parse example that is a general "preprocessor" that can be adapted.
My stance is that we should not include this feature without a clear and concrete benefit with at least some evidence behind it, just because it will make a few rule-breakers happy. That's *my* choice.
I'll close with this thought. We'd like people to use Red/Ren *instead of* JSON, right? I know I do. We support comments already. If somebody complains, tell them to use Red for their config format, and have an example that shows how to make that easy.
rgchris
02:59Just an adjunct to this discussion—just because the codec doesn't support comments doesn't mean you can't use a third party one that does or modify an existing one. Same with JSONP or surrogate pairs. I don't support comments in AltJSON in part because it's not in the spec, I haven't ever encountered it in the systems I've interacted with, nor has anyone requested it (that I recall).
pekr
05:06ok, ok, guys ... just tell me how should I read that idnes.cz website to parse its content nowadays using Red then :-) I can read it in the binary form, but once again to-stringlogically complains on the wrong UTF too. What are my chances to convert it "somehow" to a readable string? I can live with the recent state of affairs vs the planned ones. I would just like to know, what are my chances here ....
giesse
05:56@Oldes you say that comments are very common in JSON... but I just tested on Firefox and Node.js (ie. V8, aka Chrome) and they doesn't support comments in JSON. I'm not going to test any other browsers, but if you know of one that does it would be nice to know
I can't imagine comments being common if browsers don't support them. I've worked for a decade writing JSON/REST APIs and interfacing to them and I've never seen comments in JSON.
iNode
06:03> Just an adjunct to this discussion—just because the codec doesn't support comments doesn't mean you can't use a third party one that does or modify an existing one.
That would be reasonable if there would be quite a big set of available libraries or laguage users like python ecosystem have. Unfortunately this is not the case yet. So it looks like attempt to split efforts of not so big community of language users for nothing.
If we will talk about following specs and standards, how about decoding HTML content based on the provided HTTP headers in response which are in specs? I see a bit of contradictions there. Maybe actual goal is just stick with minimal implementation of whatever is present even if it worth just a few lines of code to solve it?
giesse
06:04@dander contrary to JSON, XML and HTML are a total mess. The parse-markup code comes from real world code dealing with real world HTML. It's one of the reason why I think no sane person would ever want to use XML over JSON. But, very sadly, we are often forced to deal with HTML, and having a parser that doesn't fail too easily is worth a lot (especially given that I already had it written, so it didn't take much effort to handle all those extra cases - which, sadly, is not all cases, but close enough in my experience)
that binary, and make a parse rule to convert it...
rgchris
06:42@pekr I wrote a [Clean](https://github.com/rgchris/Scripts/blob/master/red/clean.red) script to convert a hybrid (messy) UTF-8/CP-1252 codepage to UTF-8. It'd be a little trickier with any other codepage as ISO-8859-1 (a subset of CP-1252) is numerically lined up with the UCS. Gabriele mapped this out in Rebol 2 with PowerMezz as I recall.
06:44I would note from said Clean script that it'd be nice if there were some built-in Parse keywords to be able to identify generic UTF-8 characters in a binary parse.
07:34@pekr I gave you the answer to your question in my last post above :point_up: [September 17, 2019 10:37 PM](https://gitter.im/red/red?at=5d81440f72fe125111c1a715) with the link to the code.
08:04@greggirwin If I remember correctly there was already a discussion about a reference to a url that can be called from help
9214
10:19So, to summarize, the questions is if codec should distinguish between malformed and intentionally messy, non-conforming data, and if it should tolerate the latter if it is commonly used, but goes against the spec. Are there any other JSON features that fit such profile? What about other formats?
@Oldes mentioned that common use-case for comments is quick config modification, but IMO usage of JSON as user-facing configuration format is misguided in the first place, as there are godzillion of other, more sensible ones (TOML, YAML, etc). It's supposed to be a data exchange format between machines, an ugly (but successful) Rebol's sibling. And in the Redbol context, usage of JSON configs just doesn't make any earthly sense.
@iNode you're exaggerating quite a bit. Writing a dozen lines of code for JSON parser or its preprocessor (as @greggirwin demonstrated) isn't a grand attempt at community's effort splitting. Not having hundreds of messy and opinionated JSON parsers, each supporting different comment flavor, is the exact opposite of "unfortunate", in my point of view. And we don't plan to go there - quantity isn't quality.
The point here is that *comment* is a syntactically-rich construct, entirely language-dependent. People use C-style /* ... */ and //, but what about Python's #, Haskell's and Lua's --, ours and Lisp's ;? Should we counter all possible combinations, or just let users know that their data is malformed and that they should clean it up on case-by-case basis, the way @rgchris does with codepages?
Given that external formats are a hot mess, and that we cannot (nor should) bake their defficencies into standard codecs, it makes more sense to concentrate on how general-purpose clean would look like, and if it's doable at all.
GiuseppeChillemi
10:31About JSON why don't we use refinement to have everything ?
Option 1: Standard working being strictly adherent to the standard and /RELAX to have the codec accept comments
or
Standard working accepting comments in data and /STRICT to accept only data adherent to standard.
rebolek
10:40IMO the most usual use case for JSON codec is interfacing with web APIs and I haven't encountered web API that returns JSONs with comments yet.
10:50@GiuseppeChillemi "to have everything" is not a valid specification. The question is should non-compliant formats be supported, and not how to support "them".
10:53If JSON with comments main use-case is config files, then it should be arguably a rare need for Red code to load such files.
xqlab
11:06I am in favor of @GiuseppeChillemi s proposition of a refinement with a block argument including all comment variations the user wants to support maybe /comment *jsondata* ["//" "/*" - "*/"]`
GiuseppeChillemi
11:07@dockimbel Nenad, nothing is strictly adhering to standards in our world. As example, cisco has its own differencies implementing the SIP protocol, so the other players. The producers of hard and soft phones simply put some extra code to work with one or another variation (but not all, yes) if (and only if) that variation is worth having. I don't know if Oldes request regards some personal use or a common pattern of JSON users. As rule I would remain **strict to the standard** and use a refinement if there are common out of standard use cases worth implementing.
dockimbel
12:36@GiuseppeChillemi In software, enforcing standards as much as possible is good, not doing so is harmful. Companies have their own good or bad reasons for extending some standards, that's not our concern. We are talking about programmers only here, and in the JSON case, they are not justified to break the standard just for personal comfort, while a standard (but more verbose) way to write comments exist (see the SO links above). About refinements, it was already mentioned above that load will not take any new refinements for codecs. And you still haven't defined exactly what extra rules should be supported, you keep being vague with "common out of standard use cases". Same for @xqlab with the "maybe". That is the problem you are overlooking: when you jump out of a standard, there is no more guideline about what should be supported and what not.
GiuseppeChillemi
13:26@dockimbel Nenad, I have been vague "on purpose" as I am expressing a general rule in the debate. Oldes request for accepting comments in JSON files is a request whose I have no data to support it. Data could be the absolute diffusion of it (% on overall developers) or the relative (% on a specific use case). Generally speaking, when those data are available for something and reflect high numbers, or if there is a perception there is a wide adoption, it means we have an important unwritten secondary standards and it is good to support them because it implies the ability to interface and work with a wider audience. So, the most important secondary /de facto/ standard(s) should be evaluated and implemented. This helps the diffusion of the language or the product because you have a great benefit with a low cost. Again, I am speaking generally to suggest a rule to solve debates on implementing requests like this. Other approaches exists, that's just one.
x8x
14:25Not supporting comments, is no fun, I have to have a JSON file and a separate file for comments... but that's how it is, VSCode which is quite popular won't accept them, we could have /cleanup refinements for load thought, as we try to do better than friends, but it should output details of what it changed/removed. When saving they would be gone anyway, not sure it's worth the effort.
9214
14:29@x8x it was already stated that load won't support any more refinements for codecs.
14:31Some interesting bits to the discussion (w/o taking sides though):
* From [RFC7159](https://tools.ietf.org/html/rfc7159):
>9. Parsers > > A JSON parser transforms a JSON text into another representation. A > JSON parser MUST accept all texts that conform to the JSON grammar. > A JSON parser MAY accept non-JSON forms or extensions. > [...] > >10. Generators > > A JSON generator produces JSON text. The resulting text MUST > strictly conform to the JSON grammar.
* [Suggested Improvements to JSON](http://bolinfest.com/essays/json.html) * [JSON5](https://json5.org/), [spec](https://spec.json5.org/)
Oldes
14:38@toomasv That is exactly what I was proposing.. not requesting.. that the file should be loadable. But I really don't care about JSON for now.
9214
14:41By gradually improving and extending JSON... you'll get Redbol. Evidently, all JSON extensions (comments, trailing commas, object literals, multiline strings, rich numeric syntax, etc) are trying to make it a proper subset of EcmaScript, which means that this whole trend was started by web developers trying to re-invent the Rebol wheel of "human readable" data exchange format.
rgchris
15:32@dockimbel Not sure, even just valid-utf8-char or some such. Something that's tied to a low-level UTF-8 decoder/validator: parse my-binary [some valid-utf8-char]. It may be worth distinguishing character sequences of different sizes in situations where you might have a length constraint.
dockimbel
16:56@toomasv The [ECMA-404](http://www.ecma-international.org/publications/standards/Ecma-404.htm) "The JSON Data Interchange Syntax" standard spec says in paragraph 2:
> A conforming JSON text is a sequence of Unicode code points that strictly conforms to the JSON grammar defined by this specification. > A conforming processor of JSON texts should not accept any inputs that are not conforming JSON texts. A conforming processor may impose semantic restrictions that limit the set of conforming JSON texts that it will process.
Which contradicts the RFC... Is there anything in the web stack that is not a mess? ;-)
greggirwin
17:19People keep commenting, but nobody speaks to my points here :point_up: [September 17, 2019 7:30 PM](https://gitter.im/red/red?at=5d8188b853bbf77ee080d90b). (Thanks @9214 for referencing it in cleanup ) Please say whether you agree with the points I make there, though you can still disagree with my choice. I'd also like to hear if you agree with my closing thought.
Let me ask a slightly different question. Anecdotally, many of us have never been affected by comments in JSON in the wild. Who here has ever *needed* this feature, because some API returned JSON with comments in it? I don't mean finding an example config JSON config file in some JS project, but in your own work. That *may* include your own JSON configs, if noted as such. I ask, because we don't have data, and those who want it represent JSON-commenters, but we don't know how many of them exist, or if they even care.
@x8x, would it help in your case to have Red support JSON comments? That is, if you're using Red to load the config, just use Red. If you're using JS tooling, don't use Red. If you're driving *both* JS and Red tooling with a single config, that's a special use case. (And, using JSON for configs makes you a rule-breaker, but we knew that about you already. ;^)
dockimbel
17:38@greggirwin Maybe a separate a cleaner lib as you propose, covering common data exchange formats JSON/XML/HTML/CSV/... would be a useful tool, to "fix" non-conforming files before passing them to the codecs. So we don't have to cripple our codecs with arbitrary non-conforming "extensions".
toomasv
17:45@dockimbel That's really interesting. From ECMA-404:
> (para2) This specification, ECMA-404, replaces those earlier definitions of the JSON syntax. Concurrently, the IETF published RFC 7158/7159 and in 2017 RFC 8259 as updates to RFC 4627. The JSON syntax specified by this specification and by RFC 8259 are intended to be identical. >[...] >(para3) This specification and [RFC8259] both provide specifications of the JSON grammar but do so using different formalisms. The intent is that both specifications define the same syntactic language.
And RFC8259 repeats verbatim RFC7159 as referred above.
I second that. Dedicated clean dialect / module to clean up messy data in external formats (if possible at all), and make them conformable to respective specifications. This keeps codecs tiny and robust, while untying our hands in how to handle so-called "common out of standards use cases"; and it's a good project idea by itself, that leverages Red's key strengths and can possibly attract users from other languages.
greggirwin
17:53And is a great parse example. If designed properly, it's also something others can extend.
pekr
18:03You have to have two parse passes thru one source, right? Not sure it is a problem, speedwise. But would not work for a "streamed" parser, if we will see it one day?
9214
18:03Another point that only a few here seems to get (and that @greggirwin already articulated) - if core team, as language designers, accept this proposal, then it opens up a Pandora box for other similar feature requests, with no end in sight. So, I agree with no-comment stance - we need concrete data, not anecdotal evidence, and that's especially crucial with JSON , because, being one of the first codecs, it sets the tone for all future format parsers.
As far as I understand, comments in JSON are used only in configuration files maintaned by humans, and they are never included in API responses and other automatically generated data. And I already said that using JSON for handwritten configs makes no sense in Red universe; so, what we need are examples (both real and hypothetical) of Red interfacing with JSON-based tooling that uses said "messy" configs.
greggirwin
18:08It's interesting to look at the tradeoffs and design intent behind a spec. IIRC, Crockford wanted to keep JSON's grammar as simple as possible, to facilitate writing correct parsers and consistent generators. Some aspects also came from JS itself of course. Quoting keys, trailing commas, removing comment support, no leading zeros on numbers, unicode char format; all conscious choices.
For us, it's also interesting to note that Rebol never had a formal grammar defined. @meijeru has taken on the monumental task of formalizing one for Red, which covers a lot. We offer libRed for others, so we are the reference standard, but Ren (ren-data.org) was intended to be a Redbol spin on JSON. Define literal forms that could be consistently shared between implementations. I still want to revive that, but there are open questions to be answered.
We make these choices all the time, and few are easy. Consider date!'s format. It now supports T as well as / as the time separator, which Rebol consciously did not. We believe / is a better fit for our world, but T makes it match the ISO8601 spec, which is widely used. But note that we don't make T the default. We need to move forward, and make Red the best it can be, while still helping people adopt it. Helpers and band-aids may seem inconvenient, but the idea is that they can be added if needed, and removed over time, without affecting the core.
dander
18:41My sense is that most people using the tools just don't want to be blocked because they can't load a document. Whether that is possible from the built in codec or a separate module is probably less important to a user of Red than whether they need to write their own parser or not. I understand that cleaning data is a big part of AI work too. That sounds like a great project
greggirwin
18:45I should have said RFC3339, rather than ISO8601 above.
dockimbel
20:01FYI, we have postponed the switch of View code to a submodule to tomorrow morning, as we are not fully ready yet.
GaryMiller
20:21Apparently almost 62,000 Javascript users can't live without JSON comments! https://www.npmjs.com/package/comment-json
dockimbel
20:27@GaryMiller > supports comments everywhere, yes, EVERYWHERE in a JSON file, eventually > Stringify the objects into JSON strings with comments if there are
So fully non-compliant with all the official JSON specs! :+1:
20:34From what I can find online, there's 10M+ JS developers in the world, so:
>> to-percent 62e3 / 10e6
== 0.62%
greggirwin
20:41@GaryMiller good find. Not sure we can say "can't live without". ;^) At a quick glance, 58K downloads of json-parser, which depends on it account for the vast bulk. Json-parser is deprecated. It also doesn't tell us how much it's actually used. Still, it's a metric. It would be good to know, for example, how many use it to keep comments, rather than just stripping them. Because I don't think we're going to keep comments, especially after looking at the results for how they do it. If you need commentary in JSON, that's fine. Include it as data. It breaks no rules, it round-trips by default, and can easily be ignore by processors. The argument against bloat there would only apply in data exchange scenarios, where it would still be a better solution than comments, because every JSON system would support it by default.
It would be great to extract some of this chat, so the rationale isn't lost.
Oldes
20:44Rationale is, that although it is quite easy to add few lines into existing parser, there is no will to do it and you will rather let people to write own parsers if they need it and do two load passes. But can we just move into something else? I really don't want to ready anything about JSON anymore.
GaryMiller
20:47True, but if one developer pulls it down with NPM to our server our other 2,999 developers don't have to. So I should correct myself and say at least 62,000 shops that develop in Javascript instead of individual developers. But I know too that not all shops have 3,000 developers. Where I see comment used a a lot is in NOSQL database which are called document databases and basically just large JSON collections distributed across multiple servers. They are commonly versioned which means that new JSON data comes and other JSON data goes from version to version. Usually its safer to comment obsolete JSON data for a while until you're sure you won't need to rollback to an earlier version.
iNode
20:51@9214 "quantity isn't quality" - I can agree there, why one would write or use another JSON parser(s) if original one is good enough? Definition of "good enough" may differ of course as in this case. And/but having a number of compeeting libraries may make some sense from "evolution" stand point of view in case if community is quite big and have a lot of spare resources. But it's hardly applicable for Red community and we need more focus there. So duplicate libraries are waste at this stage and proposal to have your own parser when original one is present it is proposal to waste community time. And I'm OK with the point to save core team resources on some "minor" things, from their point of view, but it shouldn't be hidden under "we want to follow the spec _in this case_".
9214
20:53@Oldes it's quite easy, technically, to jump from the roof. You know why very few actually do that? Same reason we weight in on JSON comments - it has long-stretching consequences. I think everyone agrees that Red _should_ have an RFC-conforming codec, but whenever or not it needs a JSON5 one is an open question, to answer which we need some first-hand experience.
Oldes
20:55My experience was, that I took the first JSON file I found and it failed to load... as a someone who is not following JSON _development_ I was not awared, that comments are not legal anymore and though that it is a Red bug. That's all... and now I can jump elsewhere.
greggirwin
21:08I declare the JSON comment case...closed. <bangs gavel>
9214
21:09Actually, two interesting points: * [Original JSON file](https://raw.githubusercontent.com/victorca25/BasicSR/master/codes/options/train/train_ESRGAN.json) that spawned this thread was used, as far as I can tell, to train GANs, and comments in it are a hacky way to manually patch model's options, or debug leftovers. * [It got replaced](https://github.com/xinntao/BasicSR/tree/master/codes/options/train) by YAML.
GiuseppeChillemi
21:11Developers should receive the reason for the failure to avoid such flow of thougths. Other tools loads this JSON file - > RED does not - > RED codec is buggy. My intuition tells me in such situation it is common to exchange a good compliant implementation for a buggy one: if everything else loads the file and a good tool does not, then the good tool become the bad one. This let me think about people following rules in a territory where people do the opposite: good guys become bad guys and vice versa ! I see a pattern... I could call it an inversion of perceived law
greggirwin
21:14Red clearly tells you the offending JSON is invalid @GiuseppeChillemi.
@dockimbel > @hiiamboris About your Red stack related post :point_up: [September 10, 2019 9:59 AM](https://gitter.im/red/red?at=5d7757df3b1e5e5df184db0d): > > I don't understand your point here. The stack is a working place for Red functions, so it's heavily used in many different places, as a lot of processing happens on the stack. > You are making a generality from a specific case (and you've picked up one of the worst). Fortunately, it's not that bad, even though the current stack handling is not fully satisfying. > I don't see how that would be helpful. Which problem are you trying to solve with that?
The point is that when I make Red function calls from R/S, I have to make sure my stack layout is correct. But I have no means to test for that correctness. Okay, sure, I can write a ton of asserts, but this approach has some shortcomings..
Anyway, it was just a vague idea born from pretty brief R/S exposure, that I wanted to share with you. If you say this problem is uncommon, I trust your judgement :)
21:18@GiuseppeChillemi do you mean "Your JSON contains comments, which are not valid."? No, because then our codec would become massively bloated with every possible invalid construct someone could come up with.
21:19That could be another external utility though.
Oldes
21:20@greggirwin funny thing is, that Red actually don't load the file because other reason than comment:
21:23Well, what do you know. There's a missing pair of wrapping {...}.
GiuseppeChillemi
21:24@greggirwin Just remember that our mind tend to fill the uncertainess with its own explanation when no other explanation is provided. Sometime this could put you off track. However, if the combination of error cases is low (< 20 ?) explaining would be good. Otherwhise (cases >20) no explanation or generic one, or divided in classes of error, is advised.
21:30@9214 However, I have not followed the debate on the reason why LOAD will not have an /option refinement to pass a block of options to the internal specific data parser/codec. Has this happened here ?
greggirwin
21:32Load spec blocks are a conversation for a later time.
21:43@Oldes as @9214 said your example is malformed. If I remove the comments from the original URL-sourced data, it loads fine. So it is the comments.
Oldes
21:44:point_up: [September 18, 2019 11:20 PM](https://gitter.im/red/red?at=5d829fbac77f285fb1a04745) there is no comment.
21:46Ok.. I really have to end with this. Good night.
GiuseppeChillemi
22:14Good night Oldes, do not despair! We are humans. Our difficulties let us all exchange opinions and evolve. It's falling down and emitting strange sounds we learn to walk and talk.
koba-yu
00:05Though I have not read and understood all discussion here(Sorry, not have enough time and knowledge for me), I just want to comment VS Code treats JSON and JSON with Comments as different languages.
Maybe this is one practical choice example that JSON and JSON with Comments are different. If Red distinguishes them in the same way, JSON codec(if it is not JSON with Comments codec) does not allow comments is understandable.
02:36Question: is anyone familiar with the "expect" program that was based on TCL? Is there an equivalent for Red, at least under Linux/Unix systems?
greggirwin
03:10There is no Excpect for Red...yet. I have Exploring Expect on my shelf, and have thought about implementing it at times. Step 1, I think is a CLI dialect that offers interrogation and feedback for itself, and sub-commands it may launch.
xqlab
05:43@dockimbel *maybe* I was too hasty. I was thinking about something like a load-json: function with the optional refinement. But even with load/asis a solution possible. Offer a json-comment field under system\options, that can contain the wanted comment ways.
getHandleComments
boolean getHandleComments()
Whether to parse or ignore comments - either reading or writing
setHandleComments
IParser setHandleComments(boolean value)
15926222352
07:29I now want to develop a DAPP in EOS block chain don't know if the community have the programmer would like to help me develop the DAPP I would like to pay with RED TOKEN
07:36Red team you should let the Red Community Token can play out the value of ICO for one year I didn't find Red scrip have any real value can not correctly reflect value
rebolek
07:37@15926222352 please, don't post same messages into multiple rooms. Thanks!
08:57I am using the Red progress site (https://progress.red-lang.org/) to stay abreast of developments. Until recently, it tracked all branches of the red/red repository on Github, but the latest activity on refactoring the lexer is not appearing there. Can @x8x, who I think is behind this site, explain?
08:58Or is the site using a fixed list of branches?
15926222352
09:01There will be language development in red DAPP programmers? I want to use red token to pay for development costs. Thanks
10:16Red language project team should organize more activities for example use red language as the foundation of application development or DAPP game development contract
10:28I don't want to re-open the JSON codec, but codecs in general. As Gregg pointed out, we might have several codecs, given their size it might or might not be an ideal solution. Given the Redbol dynamic nature, I can imagine codecs having some /parsefunction and/or local storage of available parsers in a block. Imagine if some standard develops, and you might welcome versioning, it could be codec/parsers: [1.0 [.....] 1.2 [....]]. Any such storage is dynamically extendable, sortable, searchable, as it is a block or a map.
9214
10:38@15926222352 please use [dedicated room](https://gitter.im/red/blockchain) to ask blockchain-specific questions (related to Red of course), and refrain from spamming.
x8x
10:43@meijeru Hello Rudolf, please send me the links of what is not showing up so I can have a look, thank you!
My thoughts are that @Oldes [problem](https://gitter.im/red/red?at=5d8299ceb9f8210ed5ac4c6c) is perhaps not lack of comments support, but poor Red error message? A problem I also stumbled upon many times. Useful message would be Invalid json string. Near: ^{// comment^}, which would point exactly where the problem is.
Red is expressive enough that (provided you know where exactly your problem is) it's faster to write your own parse rule to clean comments than looking for a suitable *npm* library in JavaScript world.
Oldes
10:52@loziniak please... the JSON case is closed! But you are right, that the message should be better.. first of all it should not be User Error
loziniak
10:55Sometimes a closed case is a good start for a new case :-)
9214
11:12@loziniak in current codec implementation (which is not even 1.0, mind you), error reporting has [coarse granularity](https://github.com/red/red/blob/master/environment/codecs/json/load-json.red#L201), i.e. it marks location before malformed JSON value (object in this case), and reports it only [after](https://github.com/red/red/blob/master/environment/codecs/json/load-json.red#L234) parsing have failed.
As for "poor Red messages" see [this](https://github.com/red/red/issues/3282) thread. Informative error reporting in dynamic and homoiconic language (such as Red) is not a trivial problem to solve.
loziniak
11:13@9214 great info, thanks! Apparently not a new case.
JacobGood1
15:26Debugging experiences to emulate: https://malisper.me/category/debugging-common-lisp/ and from Pharo: https://twitter.com/Richo1066/status/1131788453451096068
15:27I have probably linked these before, but I am just refreshing everyone's memory in case these examples, the ones from Pharo and Common Lisp, are forgotten.
I appreciate that error reporting is not trivial, but what we have at the moment is not fit for purpose. It may be more-or-less adequate when debugging the latest dozen lines of code writte while developing (9/10 times the problem is in those lines). But it seems to fundamentally put a limit on the size of Red systems - and/or the ability to easily integrate two separate code bases.
User example - a couple of weeks ago, I experimentally tried to convert a Rebol/Core system (60 scripts, 25,000 lines of code) to Red. I did not expect it to be easy or fun. But I was not expecting to be so misled by errors messages.
Take this one - it took a couple of hours of my life to resolve:
There is not a single instance of SET-PATH in the 60 scripts / 25,000 lines of code. So basically, not a single clue in the message where to start looking.
(If you are interested, the bug fix was to make the 'word in a FOREACH local to its function). I got a log of around 20 other errors which might as well have just said "Shrug. Magic bad".
So attacking the non-trivial problem with some priority could well be a unique selling point for Red.
Error doesn't tell you that there's a problem with set-path! value, it prints out stack trace, in which set-path was the last called action. Not very informative, true, but hardly misleading.
dirtbagger
22:24I am not a programmer, but from time to time I have a data-manipulation problem that I can't handle using off-the-shelf software. In cases like that I write the program I need. For the latest such project I set out wanting to try to write the program in Red, but when I found that I would have to learn using the Rebol documentation I decided to write in Rebol, with the aim of eventually converting to Red.
22:29Hmm, just learned not to hit return if I'm not finished a message. I'm new to this sort of message board. Anyway, to carry on, I now have a working program in Rebol. I started looking at what I'd have to do to convert it to Red. One problem I've found is that in Rebol I made extensive use of ports for file I/O. In other words, I used "open" and "close" a lot. These instructions don't seem to exist in Red. Am I missing something. Does Red not have a facility like ports for file I/O?
GiuseppeChillemi
22:35@dirtbagger ports are being implemented, soon you will see them. Be patient, they are doing lot of work behind the scenes.
9214
22:55@dirtbagger ports are scheduled for 0.7.0 release. In the meantime, depending on your actual task, you can substitute them with read.
dsunanda
23:05@9214 Thanks. Actually, completely uniformative, as the last action called is irrelevant to the failure....If a SET-PATH was called, it was not (directly) from the user-level code. It might have well have said "Failure in something defined somewhere in SYSTEM. You're on your own". Red can do better than that - Rebol does (somewhat).
packetrhino
04:15@greggirwin there are many ports of "expect" like behavior to examine, such as Perl's Expect.pm , Python's pexpect or pyexpect, even Windows PowerShell has an "expect" like package.
meijeru
08:13@x8x basically it is all of the branches of the red/red repository that have new commits - you have shown the negative-zero and the GTK branch last week, but this week there is activity in refactor-lexer and it does not show up. The links are like https://github.com/red/red/tree/refactor-lexer and similar for all branches.
x8x
08:21@meijeru Thank you! I'll have a look and let you know.
09:37@meijeru Should be fine now, please let me know if you spot issues again!
12:02I have just published a small program to check if you have the latest Red version. It is in my [Gist](https://gist.github.com/meijeru/cdf230aa9a94d51737931bf20269587b)
12:05I have a suggestion: incorporate this in the current GUI console as a second option in the Help menu (after About).
loziniak
15:45User would probably never see "you are up-to-date" message with current speed of generating commits by the team! :-)
meijeru
16:02BTW in the red/gui-branch room I show how I added this facility myself to the console, by modifying the menu and the on-menu actor.
lucindamichele
16:15> I have just published a small program to check if you have the latest Red version. It is in my [Gist](https://gist.github.com/meijeru/cdf230aa9a94d51737931bf20269587b) Very cool @meijeru !
19:37Thanks to @GiuseppeChillemi and @9214 for the responses to my question about ports. On a more general question, does anyone have advice to offer on converting Rebol code to Red? My perhaps rather naive approach would be to just try running the Rebol code from the Red console and see what doesn't work. If there's a more efficient or systematic approach to use I'd be pleased to learn of it.
9214
19:40@dirtbagger Rebol2 and Red are highly compatible, I suggest to gradually copypaste Rebol bits, bottom-up, and check if they work as expected. In case something breaks - the best way to figure out what went wrong is to ask for help in our [chat room](https://gitter.im/red/help).
dander
19:58@dirtbagger It would probably be helpful to look over [this reference](https://github.com/red/red/wiki/%5BDOC%5D-Differences-between-Red-and-Rebol) for differences before you start. And would be very helpful if you record any new things you find there as well!
greggirwin
20:20Thanks @dander, yes, more info is always good.
20:32@JacobGood1, thanks for those links. We have various elements of debugging to address: language (errors), instrumentation/tracing (runtime), and environment (tooling). @maximvl did some CL-like experiments, which were pretty cool, showing how Red can be adapted at the user level for some things. Tooling is probably the easiest thing to address, because we can build them as needs arise, and use the future plugin system in the console and full IDEs. e.g. a 5-minute object inspector:
debug-obj: function ['obj [word!] "Ref to object"][
o: get obj
spec: copy [across]
repend spec ['h3 rejoin ["Editing: " obj] 'return]
foreach word words-of o [
repend spec [
'text form word
to set-word! rejoin ['f- word] 'field 'data o/:word compose [
(to set-path! reduce [obj word]) face/data
probe o
]
'return
]
]
probe spec
view spec
]
o: object [x: y: 0]
debug-obj o
o2: object [x: y: z: 1]
debug-obj o2
Instrumentation is an interesting area I'm keen on (think DTrace), and Red's dynamism is great and terrible for some of these issues. e.g., it's not just a compiler optimization switch we can flip. We also constantly push and pull, on the design side, about what needs to be in R/S for performance, and what can be built at the user/mezz level. Also figuring out what hooks are necessary in order to facilitate probing and AOC type features, without going full MOP on people. I'm not saying MOP is bad, not at all, just that it's not part of Red's design today.
It all raises questions about debugging in general, and that one size does not fit all. Sometimes you're debugging a function, working in the REPL, sometimes an application, other times a complete system.
07:58@JacobGood1 So much true...I hope to see an editor that let's you debug a selection of code and/or that let's you isolate all but a new function (or even a line) you are creating, and let's you debug only that. Or does it exist already? P.S. have you seen [this](http://www.rebol.org/view-script.r?script=mini-edit-do.r) ;) ?
meijeru
16:28@greggirwin debug-obj is a nice quickie, but when I called it with an expression evaluating to an object, rather than with a word referring to an object (which admittedly I should not have done), it showed a confusing error message. I will report on this in red/bugs.
planetsizecpu
16:42Why not a switch? I used a very effective debugger for many years, you selected the point where you wanted to start debugging with the debug-on keyword and the point where you should end the debugger with debug-off. Then you compiled the program in debug mode, so when it was executed it worked normally, and, when program arrived at the debug point, a window opened where you could see the source code and the debuger awaited confirmation to execute each instruction, step by step, also check the status of the variables or continue the normal process by closing the debuger. I saved many hours looking for hidden faults, but it is just a idea.
9214
16:49> selected the point where you wanted to start debugging
I hope you realize that in Red this "point" cannot even exist in a textual program at the time of debugging (e.g. code generation). Traditional breakpoints are extremely limited, and cover only a naive, static subset of the language.
planetsizecpu
16:58I know, and there maybe also events code running ... bigger challenge, just a idea, as I said.
9214
17:02Not to mention dialects, for which debugging and error messages should be, ideally, domain-specific. Which means that Red should provide some "debugging framework" to build on top of.
JLCyclo
18:26@luce80 For debugging a script step by step, try https://github.com/red/community/blob/master/tools/rdbstep.red
18:28I will update this script to manage breakpoints in a way not to simulate automatic step commands until a breakpoint.
greggirwin
18:29@meijeru, yes, lit-word args deserve a good article written about them, their exceptional flexibility, and the pitfalls that come with it.
18:30@JLCyclo thanks for the reminder about that. I get an error just putting it in the console. Need to read up.
Type help or h or ? for help at the prompt (rdbstep)
*** Script Error: stepnext does not allow string! for its redsrc argument
*** Where: stepnext
*** Stack:
18:31Will try to make time to check it out in the near future.
JLCyclo
18:41In the header of rdbstep.red, there is some help
19:03I copied the source to the clipboard and did do read-clipboard in the console. Standard practice for me, when playing around. Will download and run standalone in the future.
greggirwin
02:56@packetrhino if you'd like to be in the loop on any Expect related chat, let me know. I've done some reading today, and remembered a couple related projects I've done. One is send-keys, which is a Windows-only GUI lib for keystroke pumping. Another was an old Install Helper app that launched apps, watched for dialogs and interacted with them, etc.
packetrhino
03:28@greggirwin yes please do keep me in the loop
JacobGood1
03:53@9214 and an easily extensible ide for those dialects
meijeru
10:22I have downloaded the latest red.exe for Windows (22-Sep-2019, sha: 7daa2dd5) and compiled the console (yielding gui-console-2019-9-22-34786.exe) but, strangely, when I ask for about, it gives me Red 0.6.4 for Windows built 20-Sep-2019/18:03:51+02:00 commit #04daa5e, which is a much older version. What am I doing wrong? Also, I can't see a commit with sha: 7daa2dd5 anywhere.
10:25So far, one explanation seems to be that red-latest-exe has not been updated.
greggirwin
20:06What OS? I don't see a 7daa2dd5 for any of the SHAs on the download page.
19:15I am looking for the Wiki entry that lists the functions that still have TBD in their specs. It was recently made but not findable from the Wiki main page. Help!
19:53Thanks to Ian Nomar for making this. I did an exhaustive scan of the pre-defined functions, and the only one he missed is request-dir which has a /multi refinement to be defined.
greggirwin
20:07@meijeru I thought that signature part came from the build webhook, but can't find the details right now to verify. @x8x? :point_up: [September 23, 2019 12:29 AM](https://gitter.im/red/red?at=5d88665db9f8210ed5d59849)
x8x
20:16All is good now, small issue related to the git submodule experiment.
20:46@meijeru Thanks for watching our back and reporting! Much appreciated :smile:
greggirwin
20:57@meijeru on https://github.com/red/red/issues/4047 the behavior is easy to reason about, but you're correct that it's not documented. It *is* by design however, as there is explicit integer handling logic. @gltewalt, would you please add an example to the image! docs?
Oldes
06:53@greggirwin I must disagree again with you. I consider @meijeru issue to be a bug. Sorry.
06:57@greggirwin regarding your _ask on chat_ comment... I don't like it either.. it is easy to lost info in these chats and quite often there is no response, like [in this another buggy case](https://gitter.im/red/red/gui-branch?at=5d82894f901bb84d902f879e)
greggirwin
08:47If someone says "Is this intended?", it's a questionable ticket. If we chat, and agree it's ticket-worthy, then we put it in a ticket. That simple.
08:47If it's a bug, then it's either a design bug, and should be addressed as such, or a genuine bug, in which case we need to determine the correct/expected behavior.
meijeru
09:42I can reformulate it as a genuine bug by saying: since it has not been documented anywhere and is not obviously by design (at least not to me), I say there should be an error message that it is forbidden. That may then be dismissed by the Red team with proper justification and motivated interpretation of what it does.
09:44I don't buy the argument of explicit integer handling, because one integer could also be interpreted as four bytes (RGBA).
dockimbel
14:29FYI, we have a WIP https://github.com/red/red/issues/4049 on changing the underlying pair! type to use float32! components instead of integer!. As using floats for pairs is not always desirable (because of side-effects in float handlings), we are considering keeping the pair! as is, and introducing a new similar 2D type, but relying on floats. The hard part, as usual, is coming up with a proper syntax for such type (in addition to a proper name). So we are proposing coordinate! for such new type name and using the same syntax as pairs, but with mandatory decimal markers, e.g. 1.0x2.0. Such type would allow also an optional third coordinate. Would such syntax be acceptable?
15:50@dockimbel I just wanted to say: Consider point! or point2d!. With a plan to have a point3d! in the future (surely this one will come handy). But you were faster :) P.S. or point! can have a varying length, like tuple - 2 or 3 numbers
rebolek
15:51> (...) but not sure Redbol land likes such abbreviations
coord(inate)! is based on float32! which is an abbreviation itself. :smile: Anyway, point! is a better name I guess.
15:58Also. Can we not use the comma , instead of x for this new type? I always wondered why comma is never used for anything in Redbol. 1.0,2.0,3.0 or 1.0x2.0x3.0. Without syntax highlighting the first one reads a bit easier to my eye.
16:11> btw - how could GUI benefit from a subpixel accuracy?
One example is the caret in the gui-console. The position is not accurate for now. When you press Enter key many times in the gui-console, you'll notice it.
hiiamboris
16:15Yes, think also of draw used with scale. Think of the points expressed in https://github.com/red/REP/issues/34. Think of the https://github.com/red/red/issues/3336 problem (computing the text size).
rebolek
16:21Custom GUI styles would benefit from it. I've got code in Rebol that is point!less (haha) to port to Red without floating pair!.
pekr
16:21Thanks for the answers re the subpixel accuracy usefulness. As for the name point!all the way ....
toomasv
16:45@pekr Here is an [example](https://tinyurl.com/y4fe699c) of subpixel accuracy importance. (You'll need also [dftc.red](https://raw.githubusercontent.com/toomasv/fourier/master/dftc.red) and [coffee](https://raw.githubusercontent.com/toomasv/fourier/master/coffee)).
If you run the file and stop the animation (by clicking on it) and then zoom into (wheel) then you might find the end-point of all the blue lines and see that orange line is drawn actually in a bit different place than the end-point of blue vectors. Blue ones are placed with sub-pixel accuracy, but orange line with pair!, i.e. pixel accuracy. (You can move the pic with mid-down dragging, ctrl-wheel to change rate).
Also, smallest circles are mis-sized and misplaced because there seems to be a lower limit on circle radius :)
dockimbel
17:07@hiiamboris The comma syntactic treatment is a decade-long discussion about keeping or dropping comma as decimal separator. Maybe it's time to revisit it. Though it's a pandora box, the resulting discussions usually have low signal/noise ratio, as many people tend to express their personal opinions instead of giving factual arguments.
hiiamboris
17:13I've two arguments: - better worst-case readability: 1.0,2.0 vs 1.0x2.0 - we get shorter syntax variant for free: 1,2 vs 1.0x2.0
dockimbel
17:15I see three main arguments for dropping the decimal comma: 1. Demography: when taking the top 30 countries ranked by population, the [ones](https://en.wikipedia.org/wiki/Decimal_separator#Countries_using_decimal_point) using decimal point add up to ~4.5B, while the decimal comma [ones](https://en.wikipedia.org/wiki/Decimal_separator#Countries_using_decimal_comma) add up to ~1.2B. 2. Inconsistency in human-friendliness goal: comma is used by many in financial and scientific communities as digits grouping symbol. So why would we be more human-friendly by accepting 1,234 rather than 1,000,000? Moreover, why should we insist on localizing the decimal separator, if we don't localize everything else? 3. Pretty much all the mainstream PL are standardizing on decimal point, freeing the comma for other literal forms.
17:16As a French mathematician, I never use comma as decimal (as we should do) since it is incoherent with list of numbers as in the example given by @hiiamboris 1,2 or 1.0,2.0.
dockimbel
17:19@rcqls As a French too, I always use a comma when hand-writing, but a point for decimals when typing on a keyboard.
17:32Hello ! I'm from France, former user of Rebol for my PhD in medieval history. I was really happy to discover Red. I'm using it actually for personal uses as I don't really work in the computer science field but always passionate and I'm teaching code and art to kids (and big kids too ;-) ) in schools and museums during workshops. I plan to use Red in my activity in order to make them discover this language and all its capacities. I join this room in order to meet people and discover more about Red.
hiiamboris
17:41Hello and welcome, @jeffakakaneda_twitter :) If you're more familiar with Rebol than Red yet, https://github.com/red/red/wiki/[DOC]-Differences-between-Red-and-Rebol page may be of help to you. https://gitter.im/red/help is a place where we will help you learn Red :)
jeffakakaneda_twitter
17:49Thanks ! I wonder if there will be some Red users or a Red event at FOSDEM in Brussels in february.
Oldes
17:50What is advantage of having pair! 1x1 and point! 1.0x1.0?
> As using floats for pairs is not always desirable (because of side-effects in float handlings), we are considering keeping the pair! as is, and introducing a new similar 2D type, but relying on floats.
Oldes
17:58I mean... what is wrong with having pair! based on float32 as it is in Rebol3?
17:59When I read [this](https://github.com/red/red/pull/4049#issuecomment-534493329), than only that _No bitwise operations. (and, or, xor)_, which I never used.
18:00Having float pair when dealing with images is a good thing imho.
18:01So my opinion is, that it is definitely good to have float pair, but not two very similar types, which differ only in internal implementation.
18:02Btw... I would like to have more dimensional _points_ as a datatype.
rebolek
18:03@Oldes that's like saying we don't need integer! because we have float!
nedzadarek
18:06@rebolek @Oldes it depends on the implementation of a floating numbers. According to [stackoverflow answer](https://stackoverflow.com/questions/37025423/what-is-lua-number-type-length-in-bytes/37025843#37025843) the Lua used "floats" as it's number representation. I read that they didn't have "big problems" with "float handlings" nor speed. As fair I remember DEC64 (implemented by @hiiamboris but I couldn't find the link) does not have that problems.
18:11> The number type represents real (double-precision floating-point) numbers. Lua has no integer type, as it does not need it. There is a widespread misconception about floating-point arithmetic errors and some people fear that even a simple increment can go weird with floating-point numbers. The fact is that, when you use a double to represent an integer, there is no rounding error at all (unless the number is greater than 100,000,000,000,000). Specifically, a Lua number can represent any long integer without rounding problems. Moreover, most modern CPUs do floating-point arithmetic as fast as (or even faster than) integer arithmetic.
[Source](https://www.lua.org/pil/2.3.html)
pekr
18:24In Czech locale, comma is used as a decimal separator too. But - I do hate it. Using it for a thousands separator looks even mor weird though. MS allowing locales and translation of function names in Excel was imo one of the worst decisions ever.
18:26My question though is, what would we gain be freeing comma? Do you really want to see something like 1.2,1.1 instead of 1.2x1.1? I also fear that freeing comma will attract ppl to use it in arrays or vectors :-)
18:57Supporting comma as decimal separator is really not needed and it is inconsistent in a way. When writting code you are actually writting in English (all the keywords are English anyway), so it's just normal to use "English locale". Should comma be used somewhere else and where - it's another question.
19:19@avitkauskas you can translate keywords (there were the post in the website) but if you want to share your code - yes, you should use English.
greggirwin
19:35@dockimbel agreed on your points, er, comments. I believe you proposed point! as the name initially, which I thought was fine, but coordinate! is much more specific and perhaps better, even if longer. Other domain uses of point may not be common, but there can really be no confusion about coordinate!
Did your original syntax proposal use parens around the numbers? e.g. (1.0, 2.0, 3.0) My gut instinct prefers that over a non-spaced comma connector sigil. It's also a direct mapping of mathematical notation.
I'm in the U.S., so can't have an unbiased perspective on commas. I think the original intent was good on Carl's part, but I don't know that it has been a practical benefit.
9214
19:35* pair! with float32! - I always thought that pair! will be casted to float! when one of its components overflows, the way it does with integer! and float!, and that float-based pair will be created with x; point! with optional 3rd component makes sense, and common notation for that is (x, y, z). But I'd prefer pair! and point! to be merged together, if possible, as it's just an implementation detail and discrete vs. continuous difference, which IMO shouldn't be user-facing. * as for discussion about comma support in floats - some data is kept that way (esp. in DSV/CSV tables), so it might make sense to keep them as loadable lexical forms (this parallels recent discussion about JSON codec and messy external data); there's no substantial gain from ditching it... but then it makes (x, y, z)point! literal form a bit ambiguous.
Respectech
19:39@jeffakakaneda_twitter I'm hoping to go to FOSDEM, so if I can make it there should at least be one other. :-)
jeffakakaneda_twitter
19:41@Respectech Great ! I generally spend the whole weekend there.
9214
19:54([Continuing](https://gitter.im/red/red?at=5d8a7011a38dae3a63af58a2)) another thing to consider is how to support point! in VID, Draw and View, and how to interpret its 3rd component (we're talking about 2D interfaces and images here). I also recall some ad-hoc point! struct being used in Parse, to track internal state.
hiiamboris
19:56If we accept the (x, y, z) form, I suppose , becomes a word delimiter (like brackets), then both (x,y,z) and (x , y , z) are also valid? How will this form live along the paren! and compose is what I'm concerned with. Will comma become as sort of a composition operator that concatenates numbers into a point!? May then words and expressions be used instead of numbers in place of xy and z?
9214
20:01> Will comma become as sort of a composition operator that concatenates numbers into a point!?
In such case parens are not strictly required and we end up with * value that has no direct lexical form (like e.g. object! or function!) and require evaluation to be created * esoteric concatenation operator (or point! constructor?) on the level of APL family, which is limited solely to point! values
> May then words and expressions be used instead of numbers in place of x y and z?
That's a more general question WRT support of symbols in aggregate values, e.g. use r.g.b in tuple! or quantity% in percent! (BTW, does axbpair! smells fishy to you?).
20:06Though, all examples are :fish:y: r.g.b is a valid word!, and in quantity%% receives a special lexical treatment.
20:34Is there any relationship with the proposed point! type(s) and vector!? Is vector! more akin to a sequence type?
9214
20:39@dander what do you mean by "sequence type"? vector! is homogeneous (can keep only values of the same type) and supports scalar operations. You can, in theory, have vector! of point!s.
dander
20:45@9214 I was mainly thinking about whether or not it has a fixed length (but maybe didn't have that question formed in my mind), rather than the types that it can hold. I think that does answer my question, since the point! is more like a struct, and the vector! is more like a constrained block!
9214
20:47@dander proposed point! can keep up to 3 float32! elements, that's a hard limit on cell's payload size. Both point! and vector! are "like a struct", implementation-wise, it's just that vector! keeps a reference to external buffer with all the data.
dander
20:51It sounds like they fit totally different uses. Thanks for the explanation
Softknobs
21:50Hi, I was missing some web development with Red. So I ported a minimal example of libmicrohttpd server usage to Red. Bindings are minimal and the example only serves one page but it can be expanded. Code and library binaries (Windows/Linux) can be found here: https://github.com/Softknobs/RedLibmicrohttpdPoC
greggirwin
02:17:point_up: [September 24, 2019 1:56 PM](https://gitter.im/red/red?at=5d8a74de56677e767a50d88d) Interesting questions @hiiamboris. If we think of point! like pair!, then no. They are strictly numeric in literal form. But if we think of them like parens, compose/reduce should work just fine. Effectively, the commas are there only to identify the literal form and are invisible otherwise. So the lexer can still identify them. Boy, it's a can of worms though, isn't it? It also forces the comma-as-decimal issue.
My gut says no to a non-paren, comma-connected syntax. But I'll have to think about it more, and try to overcome my history. What is the value in supporting it, I wonder?
My original thought, long ago, was simply to extend pair syntax to allow a third, optional segment. The argument, which we face even now, is that floats are harder to read in that context. But let's think about that, along with how literal coordinate! values would likely be written. Will we use them with placeholder words, to be composed? What are the use cases for entirely literal coordinate! values? Integer pairs, and their primary use(s) are easy. Pixels in UIs with VID and image sizes. What other literal pair values do people use? Anyone?
Can we identify the primary use cases for literal coordinate! values? Chime in people. Some math cases, certainly, and possibly some multipliers in 3D systems.
After literal forms that humans write, we have stored/exchanged values, which humans *may* see, but don't deal with too much, except in debugging. Then there are those values we never, ever see. We care about 1. We don't care about 3. 2 seems not so important to me in my current mood. Given that, I'm not likely to write floats out to a lot of decimal places by hand anyway, so the harm seems minimal when it comes to readability. That's true for either pair or paren syntax.
If that all makes sense, the value of paren syntax is being closer to mathematical notation. That's big. Is it big enough to warrant a completely separate syntax from pairs, which live in a similar domain for some uses? That's a *really* tough call.
Linoonphan
07:58In an article updated in June this year, the article said that it will release the Red/Android beta release in September this year. may i ask when there will be new news about Red/Android
qtxie
07:59After more reading, I think totally switch to float32-pair should be fine. Every integer between -16777217 and 16777217 has an exact floating-point representation. For the use case of the integer-pair, this is quite enough. That means we can process an image size up to 16777217x16777217 pixels without problem. We can use pair in a textarea which has up to 16777217 columns and 16777217 rows.
1. I think conformance to mathematical notation is not too important. There are plethora of expressions and constructs in programming languages for which there are specific mathematical notations that are too cumbersome to support lexically in a PL. Think e.g. of powers and roots. Type-ability, readability and Redfitness (conformity to Red-ways) are more important.
2. When it is easy to support it is advantageous of cause to have lexical form which is already established in mathematics (in some variation). In case of (1.0, 2.34, 3.01234) it is easy to type and read, but 1.0x2.34x3.01234 is not too bad also, albeit a bit harder to read. But the parens/comma version brings confusion with paren evaluation mentioned above. E.g. compose [a (b) (1.0, 2.34, 3.14)]. It's probably mainly psychological confusion as lexer can presumably easily recognize it as a special type. But visually, it's in parens but not a paren!.
3. Can other forms be considered, e.g. x(1.0 2.34 30.1234)? But it seems even harder to read, unless longer spaces are used: x(1.0 2.34 30.1234).
4. If with three members, it is certainly not a pair! anymore. To be semantically precise it is more of a point than coordinate. According to [MW](https://www.merriam-webster.com/dictionary/point) (geometric) point is *"a geometric element that has zero dimensions and a location determinable by an ordered set of coordinates"*. Coordinates are values characterising the location of a point in different dimensions. Nitpicking, coordinates determine the **location** or **position** of a point. So may-be loc! or pos!? But then again, it depends on interpretation, these values can also characterize not position of a point but dimensions of an object. E.g. (3, 10, 5) may be dimensions of an ellipsod, not a point or position. Thus, to leave room for different interpretations, it should rather be triple! analogously to pair!. But (sorry!) then it can't have just two members (as it was proposed to have two or three members). (It is probably pointless to point out that out of geometry "point" is not particularily pointed term. Did I make my point?)
5. What usage might this point!/loc!/coord!(let it be point! for now) have besides "coordinates of the position of a point"? Complex numbers and quaternions (and tessarines and bicomplex numbers) pop into mind. Two-member point!might be interpreted as a complex number, quaternion might be presented as a block of float! and 3-member point!.
6. If pair! can include float! members as @qtxie points out above, then it seems very Redfit to have "floating" triplet!s like 1.1x2.2x3.0 or 1x2x3 too.
qtxie
08:03@Linoonphan Nope. Plan changes as usual. :sweat_smile: We should have only say what we were working on at that time in the blog article.
greggirwin
08:10Good thoughts. Thanks for weighing in @toomasv. Even for the puns. :^)
3) seems like a bad path to head down.
5) leads to more thoughts, like aliasing. But this is also a slippery slope. With Red you really have to know the context to give something meaning, but the ability to alias types could enforce more strictness. I tend to lean toward pushing that enforcement up into dialects and modules, but there are arguments to be made both ways.
I like the idea of triple!, as it is domain non-specific, but it also has a very different connotation in the RDF domain. We already have that problem with tuple in other langs and such, so it's not a big problem IMO.
qtxie
08:10([Continuing](https://gitter.im/red/red?at=5d8b1e49a8c2c26e9f9833d2)) Switch to float32-pair, the user should not need to update anything. While some runtime function need to be changed to support float arguement. For example, pick and poke for image!, we need to do the conversion internally in those actions. The conversion should be safe if the range is between [-16777217, 16777217].
greggirwin
08:10We had quite a conversation in the Ren space long ago, about the name tuplex!.
08:13Issue! is another type that spans many uses, and while the name is imperfect for many of them, nobody has come up with a better one.
08:14Aliases sound nice, but offer a false sense of type safety, which is worse than offering none at all.
08:15So you really want to say that the implementation is shared, but by giving it a new name, it is a new type.
08:16But that's not perfect either. It's just all tradeoffs and, as you say, finding the best fit in Red, overall, is the goal.
qtxie
08:18> So you really want to say that the implementation is shared, but by giving it a new name, it is a new type.
@greggirwin You mean the float32-pair? No new datatype, My proposal is what this PR does. (https://github.com/red/red/pull/4049)
greggirwin
08:19Sorry @qtxie, I meant the general discussion of pair/point/triple/quad/coord/loc/pos.
hiiamboris
08:22What do we do in case of 0.0x1.0 / 0.0x0.0 ? Paren form allows us to define such values as (1.#inf, 0). x-form does not: 1.#infx0.0 R3 didn't solve that:
>> 1e10x0 * 1e40
== I.nfinitye9998x-N.aNe9998
>> I.nfinitye9998x-N.aNe999
** Script error: I.nfinitye9998x-N.aNe999 has no value
toomasv
08:23@greggirwin Er.. was it question to me? ("So you ...")
greggirwin
08:24Rhetorical. It's late for me, so take everything in that light. :^)
qtxie
08:27@hiiamboris We support this 1.#NaNx1.#INF in the lexer, though it's ugly.
toomasv
08:28@greggirwin If I understand the question to imply that I proposed introducing new types by just renaming , then noooo. What I meant was example of possible *usage* of float32-pair as complex number, like currently I might use [a i] in this way. Operations on it should be still implemented separately.
greggirwin
08:31I was springboarding thoughts off of yours. :^)
Linoonphan
08:34@qtxie If this is always the case, we are losing many developers.
08:55Yeah I get that @qtxie. Thanks :) Real ugly, but useful.
09:13@toomasv I like the triplet!+pair! idea. Mainly because usually you expect a point of a certain dimensionality. View expects 2D pairs, while some theoretical 3D engine parts will expect 3D triplets. So it makes sense to enforce that dimensionality by the typing rather than bother with extra length checks. If there will appear a case where both 2D and 3D points should be accepted, one can always make a typeset: point!: make typeset! [pair! triplet!].
bitbegin
09:20for float32! pair!, we can use a new syntax like: #<1.0 2.0> to distinguish them ?
qtxie
09:39> If there will appear a case where both 2D and 3D points should be accepted, one can always make a typeset: point!: make typeset! [pair! triplet!].
@hiiamboris Or just use the 3D triplet!. If it's used for 2D, the Z dimension can just be ignored.
hiiamboris
10:15> Moreover, most modern CPUs do floating-point arithmetic as fast as (or even faster than) integer arithmetic
After skimming thru https://www.agner.org/optimize/instruction_tables.pdf I have to agree. It's on par speedwise, and float multiplication can even be twice faster than that on integers.
9214
11:08So... initial proposal was to get float-based triple! / point! / whatnot, but now we have pair! that supports both integers and floats; then, what's the point (no pun intended) of triple!?
11:14I mean, we can always squeeze an extra 4-byte value in the payload and get new datatype, but it doesn't seems like a priority to me, as we don't have any related use-cases. Not to mention the amount of design musings over lexical form that it requires.
11:22How frequently whose coming from Rebol actually _wrote_ float-based pair! as a literal value, instead of encountering it as an intermediate computation result? With images we reason in terms of x and y amount of pixels (discrete values, integers), and rarely think of subpixel position - rather, it's almost always a result of some precise geometric computation, hidden behind graphical facade.
11:28i.e., 1.23x45.6 looks a bit quirky if you see it, but I can live with that, because I rarely will type it by hand.
qtxie
11:35> i.e., 1.23x45.6 looks a bit quirky if you see it, but I can live with that, because I rarely will type it by hand.
I'm also OK with this format.
11:44One problem of the float32-pair is in some old code we don't always use the pair/x and pair/y as number. We use it a flag sometimes. For example, In a text editor, we may use pair/x to store the line number, usepair/y as bitset flag to store some information. In this case, we cannot use float32. But it is kind of hacking code, I think we should just 2 integers. Or use vector! if we need to record every lines in the text editor.
greggirwin
17:05:point_up: [September 25, 2019 5:44 AM](https://gitter.im/red/red?at=5d8b5315b6aa4d6c90dd5add) See what happens when you hack things @qtxie? ;^)
19:48FYI, the refactor-lexer branch was dropped. The most useful changes from that branch were ported to master. That branch has been replaced with the fast-lexer branch now, re-implementing the Red run-time lexer in R/S.
bitbegin
01:47@dockimbel the new lexer can parse all codes, and give all errors? Also, if it return the line/column, will be very useful.
pekr
04:35Question of an uneducated - Lexer parses Red source code, during the load, or even interpretation? By rewriting lexer in R/S, will it "just" load code faster or will generally interpreter be faster?
hiiamboris
06:49Just load. Unless you are a fan of do load "my-code" patterns :) Still, it's a very welcome change, as sometimes you load data. After 10MBs it's unbearably slow.
06:54And as @bitbegin notes, preserving the info about the origins (line/column) of each word would be a tremendous help in debugging. Is this planned?
dockimbel
09:34@hiiamboris @bitbegin It's a feature I want to add since a long time, but we still haven't figure out how to do the reverse mapping between a given value and its line/column info for debugging purpose. One way would be to extend the cell! size to fit such extra info. Though, we can return that info on syntax errors, that case is trivial.
hiiamboris
09:49Perhaps one way is to change "index in symbol table" part of a word into a pointer to a structure with that data + the actual index?
dockimbel
10:18@hiiamboris We need a reverse-mapping to line/column (and even filename) for any value, not just words.
1. Every 2D point could be considered also a 3D point, also conversion between float and int could be seamless:
>> 1x1
== 1.0x1.0x0.0
2. My wish - could we make possible using parens like in path!?
>> 1x(pow 3 2)
== 1.0x9.0x0.0
3. In special cases (discrete image pixels, editor line hacking) we can always use vector! of integer!s.
greggirwin
16:37@loziniak 2) is a significant change, which opens the question for other segmented/multi-part values, like tuples. If you could mock up some more examples using that syntax, for use cases you imagine, we can more easily weigh things. It may be that we try an as-coord helper to start, and see if paren notation still has enough value.
16:51More of a side-note, since not everyone would have them, but with a font that has ligatures, the x-delimited ones do look a bit nicer (this is Fira Code)
giesse
18:58@loziniak 1x(something) would have to be a new block-like type. So, even though those things look like great ideas, in practice they are not.
GaryMiller
18:58Will Fast Lexer be in tomorrows available download? Windows red-25sep19-f753e25c.exe 1.2 MB
Will be interested to try. My Lex is running about 9 seconds now when loading into Interpreter. ~62,000 lines of Red Code
16:44@greggirwin @giesse this proposed paren notation for me is natural consequence of having similar mechanism in defining path!s, which is very convenient for me:
So, for me 1x(pow 3 2) is more easy to read/understand and shorter than as-coord 1 pow 3 2. At first glance you see that this expression is a coord!.
greggirwin
17:05@loziniak I'm used to parens in paths from many years of Reboling, though I don't use them often. However, they are still considered an experimental feature in Red, as we are not sure they are worth keeping.
To make sure I understand your example, you have code with 2 known values and variable key between them, like accessing a keyed record's field. Here's a more efficient way to do that, which seems clearer to me:
>> a: [b [c 123]]
== [b [c 123]]
>> k: to word! "b"
== b
>> a/:k/c
== 123
Does the path approach give you some other benefit that I don't see at a glance?
17:10Pairs today are completely literal in their syntactic form. There is no evaluation whatsoever, which has pros and cons, and is simply a design choice. Because of the separator used (x), which is not "special" like /, it opens up a lot more questions and potential ambiguity. Paths are specifically meant for indirect access, and have to start with a word. Do pairs in your design have to start with a literal number, or is (pow 3 2)x(pow 2 3) valid as well? Because that's no longer Red compatible as a syntactic form. If that's not valid in your design, you can only evaluate the y axis, which seems much less useful and general.
>> x: make op! :as-pair
== make op! [["Combine X and Y values into a pair"
x [integer! f...
>> (power 3 2)x(2 ** 3)
== 9x8
loziniak
17:16@greggirwin in your example, k is not a very meaningful name for a variable. I find it clearer to use expression to word! "b" in-place. I did not think about using get-words though, because parens were first thing I tried and it worked, so I searched no more.
17:19@9214 try to do that with hypothetic coord! :-)
17:24@greggirwin good point about syntax incompatibility of having x part of pair! defined by paren!. That kindda invalidates my idea.
9214
17:25@loziniak and how can I try to do that if it's hypothetical? Thought experiment?
loziniak
17:26Exactly. Just assume it's real. Brillant hack nevertheless.
greggirwin
17:35:point_up: [September 27, 2019 11:16 AM](https://gitter.im/red/red?at=5d8e43f0d97d8e3549c1ffed) @9214, you're going to Hell for that. ;^) Lacking the power to send you there, I will have to concede that it's an AWFULly cool idea for a dialect.
@loziniak forgive me for not trying to come up with a more meaningful name in a short chat example. ;^)
17:44@greggirwin Point taken, my names also don't carry much meaning. But everytime I can, I try to avoid variables like key, index etc.
GiuseppeChillemi
18:11@greggirwin >> I'm used to parens in paths from many years of Reboling, though I don't use them often. However, they are still considered an experimental feature in Red, as we are not sure they are worth keeping.
I use it a lot !
dander
19:16@greggirwin, here's a concrete example of [using path construction](https://gist.github.com/dander/47d10aa43d04bfcd27080ba6f3cf04ba#file-find-pattern-red-L46) (granted with all indexes in this case). It would probably be better to use word! instead of index in the cases where that is applicable, but then it would need to know if that word! was being reused in that branch of the tree...
giesse
19:16@loziniak sure, but, path! is already a block-like type, while pair! is not.
greggirwin
20:00@dander path construction isn't an issue. That's an alternative, because you're making the path from other parts, not putting parens in a literal path for their evaluative property.
20:08For the reference, the main argument against paren! in paths is a stylistic one: you can abuse them with multi-line expressions or ungodly mess like inclusion of external files and deeply nested code logic.
head/(
...
<you can embed whole Red runtime here for all I care>
...
)/(
...
)/tail
One path (no pun intended) we can take is to prohibit newlines during path! lexing, thus allowing only simple, single-line expressions. Another is to get rid of them entirely.
loziniak
20:19And one more – leave it as it is now, letting a programmer choose her own style.
16:40Allowing strings in paths without requiring extra parenthesis would make more sense. But then we end up with the exact same stylistic argument against multi-line {...}.
It is really useful when I navigate database data. Also I am planning more complex index retrieving experimenting with custom datatypes and their data position but I am currently in early stage as the data description language is currently building up in my mind.
21:12Also I am working on a way to access data in multiple separate blocks where each part of the path could jump to another pre-existant or computed block. This work is based on path access notation experiment created from ToomasV. All of those ways to dinamically access data blocks need parenthesis to be expressed in "serialized" form (hope the term "serialized" is used correctly here).
beenotung
06:20I tried to compile a hello world program w/wo -r flag, why is the binary smaller in dev mode? shouldn't release version be trimmed more aggressively?
endo64
07:48 @beenotung in release mode (-r) your compiled program and Red runtime are packed into one file, that's why it is bigger. In dev mode runtime is not included in your executable, that means you need to ship your program with the runtime (libRedRT.dll on Windows) otherwise it won't work.
greggirwin
04:06Thanks for the examples @GiuseppeChillemi. Much appreciated.
GiuseppeChillemi
08:08@greggirwin Your are welcome. Parenthesis impact a lot on my day to day programming style.
Palaing
08:20I want to split a string (a 2-column table from a database query) with both "^-" and "^/" characters to get a flat block of items. When the string is too long (13060 characters), the following:
split rawdata charset "^-^/"
fails with a "not enough memory" message. While this:
split replace/all rawdata "^/" "^-" "^-"
works fine and fast. I was just wondering why the first one would not...
hiiamboris
08:24@Palaing what's the build you're using? I cannot reproduce the issue on Red 0.6.4 for Windows built 25-Sep-2019/22:36:30+03:00 commit #f753e25
GiuseppeChillemi
08:32@greggirwin and I think I have just found a possible solution to access data with reusable paths. But I will need a little help from the RED team that should implement a feature to express this solution in a coincise manner.
Palaing
09:21@hiiamboris I'm on Red 0.6.4 date: 3-Apr-2019/11:40:57+02:00 commit: #492254683df98fd779b4157466f54a625007d80e (I don't change so often as I'm used to gui-console-not-starting problems)
20:01@Palaing if you update, you should now also have the CSV codec available. load/as expects commas, but the load-csv func can be used directly to specify that it's tab delimited. And has a /flat refinement.
GaryMiller
20:11Just curious to see if anyone benchmarked the new Lex code yet. I know it's not released yet but was too excited to about it not to ask. Rough numbers are fine. Like does it seem twice as fast? Three times as fast? Be still my heart!
greggirwin
20:50Have to wait for news from the inner circle. :^)
TheHowdy_gitlab
05:16Found an interesting idea for a dialect todayhttps://dev.to/teamxenox/introducing-caligator-a-simple-yet-powerful-open-source-calculator-convertor-5f86
05:17(Not sure if this the right place to post this, my apologies if not)
05:18That thing can probably be rather easily implemented in red and have about the tenth of the executable size of the original(the original is written in electron)
17:42Would it be possible to change the block while a path is being decoded ? I mean technically and not as an actual feature. Would it be difficult for RED ?
greggirwin
18:11@JacobGood1 Red lexer rewritten in R/S for improved performance and instrumentation.
@GiuseppeChillemi we'd need to add a callback feature so each segment would trigger that. Easy to mock up at the mezz level, which would be step one.
@TheHowdy_gitlab thanks for posting! That link ties into 2 topics. An old one is a unit! form and datatype. We can do it with blocks today, of course, but still want to consider a direct lexical form. It's tricky, because so much value of units (as Frink and Wolfram also show) comes from having their relative rules built in. That means units may be an optional module. The newer idea is that of Expect, which is an interrogative automation interface. We don't need automation here, but something like that, or Caligator, are based on the idea that you may only get a partial input, and need to "talk back" to the user to guide them in possible completion options.
GiuseppeChillemi
18:18@greggirwin Gregg, I will write a proposal and some usage examples once the idea will be complete.
bferris413
15:37Howdy, any updates or roadmap for when port! type will be generally implemented/usable? I check the website regularly and drop in here from time to time to see the latest, haven't seen much about it though
dockimbel
15:54@bferris413 Hey, port! type is already present in the master branch, but low-level I/O networking is still a WIP. We have a working async TCP and TLS ports implementation (both client and server-side), but they still require more work to cover all the target platforms. Once we have UDP and DNS, we can push the code into a branch on the red/red repo, so that people can play with them. No ETA for that yet, as we have several related sub-tasks to complete first (like some memory management improvements for I/O).
bferris413
16:18Sounds good @dockimbel , thanks for the update and work involved :+1:
dockimbel
16:43@bferris413 You're welcome. We'll publish more info about it when it will be more usable.
TheHowdy_gitlab
20:03@bferris413 just to prevent confusion, I'm by no means
20:04in the red-team, just a curious visitor of this gitter :). So I can't give u that kind of info.
bferris413
20:05Ah, "howdy" is an american-english way of saying "hello" (which is how I meant it) =)
GiuseppeChillemi
21:01@dockimbel How is the RED team composed ? I mean either how many are the members of the team and which is their respective role. I think you have never talked about this. It would be good to know about all of you.
greggirwin
21:46@GiuseppeChillemi, there are now 6 of us dedicated full time to Red, and another 6 or so that contribute regularly but have other primary jobs. Then there is a wider circle in the community with some deep work done. e.g. @rcqls on GTK and @hiiamboris on tickets requiring deep analysis and R/S skills. Respective roles, in general:
- Nenad is the leader, for language vision and design, overall direction, and deep core dev - Qingtian is his right hand in all that, and figuring out how to make it all work across platforms - I focus on management, business, logistics, community, high level design/dev, "and stuff" - Bitbegin is Core, fixes and features, Wallet, VSCode, and support for Nenad and Qingtian - ToomasV leads thinkering and has internal tasks related to tools, education, and examples - Lucinda heads PR, which includes many channels, blog, docs, and work on new web sites
Warp, Rebolek, Peter, Harald, Semseddin, GregT, Gabriele work on many things, because so much support is needed. Infrastructure, testing, research, codecs, blockchain R&D, docs, deep design. I wish I could name everyone and list their contributions, because they (you) all deserve it, but that's yet another task I'd have to put on my list. ;^)
9214
22:21@greggirwin I think @meijeru's work on Red specification deserves a dedicated mention as well.
greggirwin
22:35Indeed! And Mike and Arie for red-by-example.
pekr
09:43Thanks for the info, Gregg, appreciated. Hope that new website will carry the Team section, would be nice to see those core ppl dedicated to the project. It would imo help to generally improve the project perception. Just my opinion, of course ....
TheHowdy_gitlab
10:12@pekr imho this is a much needed idea. Many people not watching red closely enough may not even be aware of the team (even mby thinking that it is a one-man project) or the Red Foundation.
planetsizecpu
10:42There are good news, I see @TheRedTeam growing, so I want to encourage you, it still a long road to 1.0 and a plenty of things to solve, so stay tuned and push hard.
GiuseppeChillemi
10:56@greggirwin Could I write the team composition on my WIP wiki (... this reminds me someone...) programming.red ?
greggirwin
15:51@GiuseppeChillemi best to point people back to us here, or where we post team info in the future.
GiuseppeChillemi
16:41@greggirwin So you are suggesting a link to your gitter post ?
greggirwin
16:53Sure. Or just tell people there is a small team and if they come here, they'll meet some of us. :^)
GiuseppeChillemi
17:04Of course ! The best part of life is being together and not reading a web page with no people around.
Palaing
17:49@greggirwin thanks, that (CSV codec) will certainly be better than the one I made!
pekr
13:58@rebolek Where should I report findings and/or questions towards the CSV codec? First - when I try to use the delimiter parameter ";" all I get is an empty block. Second - load-csv/with #";" returns an error stating, that delimitercan't be a char! type, though its help string states otherwise. And lastly - why some lines are enclosed in quotes, whereas most of the lines are enclosed in {}?
14:21@pekr thanks for report! I'm on phone now, so I look at it in the evening and let you know. Delimiter can't be char error looks very strange, there are tests for it and they pass.
14:22If you can send me your CSV privately, it would really help.
pekr
14:52Btw, the difference between the "" and {} is there even with read/lines. I am on the phone right now too ....
14:53Btw, is there any plan to prettify console output of help on objects?
greggirwin
17:18"" vs {} came up not long ago. It's Rebol's design, and confuses people. Beyond 50 chars the runtime molds strings with {} instead of "". If, for example, truncated console output always added a closing } that would be useful, because you could persist console sessions.
Object help alignment looks like a bug/regression. @bitbegin, I hate to say it, but it was your recent help changes that caused it.
The rationale here is that /header means it should be *used*, not just that it *exists*. If you want the default format, and to separate the header, we (you? ;^) can add an example like this to the wiki page:
>> s: {a,b,c^/1,2,3^/4,5,6}
== "a,b,c^/1,2,3^/4,5,6"
>> data: load-csv s
== [["a" "b" "c"] ["1" "2" "3"] ["4" "5" "6"]]
>> hdr: take data
== ["a" "b" "c"]
>> data
== [["1" "2" "3"] ["4" "5" "6"]]
pekr
17:27I can tell you just one thing and most probably you might agree - there's always a tradeoff between the simplicity and the features offered. I gave codec a try, found some bugs or inconsistencies with just few tries. Well, bugs might get fixed, but I don't want to even think, why should I get a block vs the map. What for? To think just about that aspect is probably more complex than it might be useful to me.
17:29Worked with CSVs for 15 - 20 years with Rebol. Never ever had I to use more than just few lines of code, and it was alway consistent: data: read/lines %file.csv, remove first dataif there is header present ... and then finally the loop foreach row data [items: parse/all data ";" ....]`.... done ....
greggirwin
17:29It's still open for discussion, and is a tough call. If you get back a block of blocks by default, and user /header, what do you expect to get back?
pekr
17:30I will surely give it more try. The truth is that I never faced other delimiter than semicolon. Constructing resulting converted CSV was once again a foreach loop with write/append applied ....
17:32OTOH I have also faced a space delimited data. Fields of certain length and missed the default R2 left pad funciton back at those times ...
greggirwin
17:33I noted at one point that I've almost always taken the low level approach myself, because that's all we had, and it wasn't worth writing higher level mappings when you're trying to get a single job done, just for you. With this design we're trying to save lots of people effort over time.
17:36Looking at past projects, there were 2 big ones where these features would have helped me a lot, and I probably should have taken the time to implement them. One was data aggregation and analysis (column model), the other was a data scraping system that mapped data to records. In the latter case, whether you use "records" or just blocks depends on what you're tying to. e.g. a SQL model for DB or a grid UI that takes blocks, or a CRUD system.
pekr
17:36The problem is/was, that Rebol's low level aproach, was flexible enough to get things done in just few lines of code :-)
17:46Another argument for the extended features being standard is that it facilitates data exploration and verification, including generic tools we can offer.
17:47Having concrete examples is great @pekr, so if you have old code you port to use the codec, and can post both examples, that's helpful.
rebolek
21:17> The truth is that I never faced other delimiter than semicolon.
CSV is **comma** separated values, so comma is used as default separator. Anyway, loading data with semicolon should be as easy as load-csv/with data #";". If it doesn't work, there may be a bug. We have tests for it, but I could have overlooked something, that's possible.
>> to-csv/with [["@pekr" {convert this ; with your "parse loop"}]["@pekr" "I think it won't work"]] #";"
== {@pekr;"convert this ; with your ""parse loop"""^/@pekr;"I think it won't work"^/}
pekr
21:22SCV name might suggest that, but comma is the last value, which is used by default. That's just my experience, always semicolon. It works without the /with refinement, and returns an error with one :-)
21:23I work with company enterprise dat, always check for the length of the parse operation and return an error, if not of the same value thru the whole data set. I know, call me just lucky :-)
rebolek
21:25@pekr as shown above, it works with /with refinement. If you have an example where it doesn't work, I'll be happy to see it and improve the codec.
pekr
21:28I can not provide you with the whole dataset - company employee data from the HR system, but here is a sample:
>> data: load-csv/with ";" "12345;Krenzelok;Petr;;19.12.2018;;19.12.2018;19.12.2018;"
== [[""]]
>> data: load-csv/with #";" "12345;Krenzelok;Petr;;19.12.2018;;19.12.2018;19.12.2018;"
*** Script Error: load-csv does not allow char! for its data argument
*** Where: load-csv
*** Stack: load-csv
21:29shouldn't both cases work? Or am I doing something incorrectly?
9214
21:29@pekr you do realize that arguments are mixed up in your example?
21:32Was confused by not using any refinement. It "loaded", and I thought that the codec is not much useful, as it returned a block of strings, which I then parsed using split. That's why I wondered how is that useful in comparison to a "manual mode"
rebolek
21:33Just switch your args and it should much more useful ;)
11:43It seems the consolle does not like very big printout.
endo64
11:56For GUI console yes, CLI console can do that, just tested with over 50.000 lines text file, if the CLI console is minimized it is almost instant, otherwise it takes some time but not too much (around 20-30 seconds).
07:17Reddit blockchain programming languages - is it worth someone commenting? https://www.reddit.com/r/programming/comments/defin3/best_blockchain_programming_languages_2019/
lucindamichele
07:50I'll definitely keep an eye on this, but I'm going to wait & see if others from the https://www.reddit.com/r/programming/ community respond.
9214
10:46@mikeparr not worth it, as its's a very low quality article, and everything related to blockchain receives hostile reaction on /r/programming.
17:03window object and h5 (text) object are both assigned to t word here. But what is going on here? Which sequence of assignment is used in every cases? And why are they differ?
Oldes
17:08Because if you don't wait.. events are not processed. Use wait or do-events functions.
greggirwin
18:16@ushakovs_gitlab in the first example, t still refers to the h5 face, because view hasn't returned yet due to its implicit do-events.
w: none ; Will refer to window. Not required, but nice to note.
code: [
size 300x200
base 0x0 rate 0:0:1 on-time [w/text: mold now/time]
]
w: view/no-wait code
do-events
packetrhino
02:53I would like to start to use Red as a "shell" in Windows, I often have to use AWK for summarizing data. Can anyone point me to some easy ways to get started?
greggirwin
03:03I'm slammed this week, so won't be responsive if you have questions, but you could look at porting https://gist.github.com/greggirwin/6397bdfe8e9e7dd9f3d543bc4b0e570c to Red. That's a larger task since you're new to Red though.
Depending on your needs, the CSV codec might give you a good start (no streaming if your data is large), and then playing with the loaded data to get a feel for Red in general. I also have old [file globbing bits](http://www.rebol.org/view-script.r?script=file-list.r), as do many others. @dockimbel has a simple example [here](https://gist.github.com/dockimbel/1c0f51e3044f23688aae696a28d3096b).
*** Script Error: rename does not allow file! for its from argument
*** Where: rename
*** Stack:
While help shows that it expects file! type of argument as well
ARGUMENTS:
from [port! file! url!]
to [port! file! url!]
It looks like some other rename action or function is executed instead. Please let me know if this is an issue to report or just a wrong use of the action.>
hiiamboris
21:03@iNode looks like it's only defined for port! as of yet. TBD :)
iNode
21:10Yes, it seems so. So code is out of sync with help. I see. Thanks!
ushakovs_gitlab
17:48What is system/view/screens ? Why is not simple one screen? What does it mean?
17:55What about multi-desktops support? I mean such MS Windows function as CreateDesktop, OpenDesktop and so on.
rebolek
17:57What do those functions do? If it's something Windows-specific, it probably won't be part of Red, as it Red is going multiplatform way.
17:58That of course doesn't stop anyone from implementing it.
ushakovs_gitlab
18:07What consider platform-specific is? Android and MSDOS platforms not support multi-monitor. Is multi-monitor support platform-specific? On the other hand, multi-desktop environment exist not in Windows only, but in Linux as well. Is multi-desktop support multiplatform?
18:08It's useful ability to switch between several graphical desktops.
rebolek
18:09Red/View supports Windows and OSX and partially Linux. So if the same functionality can be achieved in all systems, it's possible it will be implemented some day,
18:10@ushakovs_gitlab thanks, now I understand what you mean.
18:19I don't suppose this feature should be touched by any apps except desktop managers. So who's gonna implement into language features that are only good for one program? :)
18:48In view's refinements some inconsistent exist. refinement /flags - set view's facet "flags". But refinement /options isn't set view's facet "options". Instead it sets any view's facet, including "flags" and "options". Is it worth to rename refinement /options to /details or /facets to eliminate this confusion?
hiiamboris
18:51I'd rather call it view/with, to be consistent with the VID with keyword.
18:52@ushakovs_gitlab you can open a wish issue at [REP repository](https://github.com/red/REP/issues)
22:38Folks, I was looking at load/csv and JSON, for Data Science. Will Red have all the libraries for data science like python using pandas, numpy, seaborn, etc? Do you have this at the Milestones? I think interfaces with TensorFlow2.0 would be good or interfaces to run using Jupyter Notebook such as R has with Jupyter. Don't you think? I'm using red but calling other interfaces to connect to elasticsearch, mongodb, solr and processing all data using R or Python, it would be great If we could have everything just using Red. What are the plans for Red for DataScience and Machine Learning? Is there anybody implementing algorithms such as linear regression, logistic regression, decision trees, random forest, neural networks, NLP, etc?
03:25> Will Red have all the libraries for data science
Dunno, will you write them? All libraries that you listed are user-contributed. Red Foundation may sponsor the efforts of writing / porting them, but said efforts should be carried out by community in the first place.
> What are the plans for Red for DataScience and Machine Learning?
The plans are to reach 1.0 and sustain the project. Period. Everything that doesn't help us to achieve this goal is a distraction, and we cannot afford yet another last-year downtime.
Once we are at the point where Red has modules and package manager, our only hope is that community will stop raising constant demands and requests for the core team (a residual habit from the times of Rebol and Carl with RT I guess), and start proactively build language ecosystem themselves. There's only so much we can do, and our plates are already full for years to come.
> Is there anybody implementing algorithms
If you want to help (or need help) in implementing them - ask @ldci and @Respectech. @moliad is rarely around, but he will be interested in NLP with Red. There are probably other members I forgot to mention.
pekr
08:24I agree with Vladimir and wanted to mention something similar. It is imo important for Red to offer low level integration facilities. And we've already got some - much much better library / c level code integration via the R/S, in comparison to R2/library module. Then we've got calltoo. On some systems, you call external tools and you can parse back the result. CSV and JSON codecs are the latest addition. Today's online world seems to be using REST API and Red should cover this. USB or Serial interface, Full IO (TCP/UDP) might be useful for embedded integrations. And so on. As it was already stated, Red could sponsor some activities, as well as community could. E.g. ODBC/Database schemes, or other stuff.
rebolek
10:35Unofficial builds are live again https://rebolek.com/builds/
10:40@rcqls Linux GUI is there for more than a year :) But I need to change repo I guess, it's still using gtk-dev I believe
rcqls
10:42@rebolek Sorry I was confusing with console-gui which works on my computer (but not in yours if I remember well)…. My bad! linux-gui is indeed there for long!
rebolek
10:44the build script is fairly old and not updated for changes you did, so who knows what it compiles ;) Anyway, now that the server is moved to a new machine, I can do some required updates (like pointing to right repos and add commit name to build).
rcqls
10:54@rebolek Everything is now in red/GTK branch and @bitbegin is working hard to improve the code.
rebolek
11:06@rcqls cool, thanks for the info. I'll update the build script accordingly
07:31We are going to add back the pretty printing for float to cover this case. Then another issue https://github.com/red/red/issues/3243 has to be reopened. I'm not sure which one is the better choice. What do you think?
hiiamboris
08:00Make mold/all do the precise output, mold - user friendly.
meijeru
08:09@hiiamboris Seems very sensible, but will it really guarantee round tripping?
08:52@hiiamboris > Make mold/all do the precise output, mold - user friendly.
That could be an acceptable trade-off.
Oldes
08:54@dockimbel than it is probably not the latest R3
dockimbel
10:19@Oldes That build corresponds to the latest commit https://github.com/rebol/rebol/commit/25033f8 in R3's repo.
giesse
19:29IMHO it would make more sense to have form do the pretty printing while mold is precise; but I guess this is mostly a console issue...
dockimbel
19:38@giesse Indeed, we need a human-friendly output in the console by default.
rebolek
20:23I also would prefer to have form doing pretty formating and mold precise one with no need for mold/all. It has been added to Rebol just for backward compatibility of mold anyway.
hiiamboris
20:33Have you seen mold/all output for strings though? (if we're talking about turning mold/all into mold)
20:35Red loads UTF-8, so if mold outputs UTF-8, there’s no need for escaping
hiiamboris
20:36I agree. Looks like a traffic waste. I wonder what was the reason for it.
rebolek
20:46I believe that mold implementation is not final, so this may be just some temporary solution.
giesse
05:52My problem with mold and form as they were defined in R2 is that form is not good enough for end users and not good enough for programmers (eg. at the console). So it's a waste of a good word, while mold has this weird distinction between mold and mold/all that only makes sense because of how mold is the default at the console and then /all was added to allow better serialization. IMHO format it's what you use to format things for end users (or, perhaps, form/with, but that's another big discussions), form should be what programmers use to inspect stuff (eg. console), and mold should be for serialization.
9214
08:00@giesse I'm the kind of guy who thinks that programmers should inspect serialized representation, because it's more precise and avoids double-guessing (is it function! or func words followed by two blocks? Is it logic! / none! or just a word true / none?).
09:45@9214 talking about mold/all and construction syntax here.
giesse
19:07@9214 agreed, but there's a clear need also for pretty printing, and it's usually what's expected at the console. In hindsight, perhaps this should all be a matter of refinements, but, given the legacy of form and mold, IMHO the former should be the pretty printing one (but, not for the end user, as it's clearly never going to be enough), and the latter the serializing one. Unfortunately that creates compatibility issues with R2 and with existing Red code...
CodingFiend_twitter
19:12with regards to Mac OSX, my point is that Apple is ruining OSX as an ecosystem, and basically transitioning to using iPad software, which is a far better selling platform (more than 2x larger user base increase per year, and probably a 10x installed base superiority). So IOS/ipad OS should probably be your target. I have OSX output on my Beads language and nobody uses it; everyone is either doing web apps or mobile. The energy level of the laptop/desktop world has collapsed.
hiiamboris
19:57What do you guys think of take/part/last construct? Should we (1) forbid using both refinements at once? R2 uses /part and ignores /last Another options would be to: 2) take the last item within the outlined part, or return none if that part is empty (following the symmetry of take/part) 3) take the last item within the outlined part, or return none if that part is empty or negative (following the idea that take/last after the tail should return none and negative part argument sort of tells us that we can't look past current position, so effectively it's a tail)
20:03Interesting! I tested it with series part argument (R2!):
>> take/part/last s: "123" tail s
== "123"
>> take/part/last s: "123" s
== ""
20:05Current behavior of Red is probably just an artifact also (considering how buggy take is right now...):
>> take/part/last next s: "1234" next next s
== "34"
>> s
== "12"
>> take/part/last next next s: "1234" next s
== ""
>> s
== "1234"
But who knows... Here are more options 4) skip the part and take & return the rest, when part is positive; an empty string if negative (like it is now) 5) skip the part and take & return the rest, but if part is negative - reverse it before doing anything
20:10My opinion is that (2)-(5) is just confusing esoteric stuff and we should proceed with (1) ☻
21:00After more digging I see that behavior (4) is an intended one, at least for the positive part.
greggirwin
22:04@CodingFiend_twitter iOS as a target only works for finished, commercial, consumer products. Eventually Red will be there, but not soon.
(take/part/last s: "1234" 1) = (take/part/last s: "1234" next s)
should be true
08:06And I also think, that the part length should be consistent across functions.
toomasv
08:07In first case you give literal length of the part, but in second case you give the starting point of the part. Why should they be equal?
Oldes
08:08Because that is how we were using it for years in Rebol?
toomasv
08:10Ah, I don't have that luggage, so I'm trying to make sense of what I see in Red, and this seems logical.
GalenIvanov
08:12The current behaviour seems logical to me too.
Oldes
08:12I know how you mean it, but I consider it confusing. Maybe because I have the luggage. Your version is making too many exceptions. As I said.. I believe that the part value should be consistent and not that in take function it means something different.
08:13Btw... is there any real life usage example for code like this?
GalenIvanov
08:18@Oldes Hmm, on second thought I understand your point.
Oldes
08:19The _series_ like length was introduced here for these situations:
>> parse "1234" [1 skip s: 2 skip e: to end] copy/part s e
== "23"
list: ["Hi I am Boris" "Gregg Irwin" "Oldes Huhuman" "Galen Ivanov" "Toomas Vooglaid"]
foreach name list [print take/last/part name find/last/tail name space]
Boris
Irwin
Huhuman
Ivanov
Vooglaid
Oldes
08:24Why not just: foreach name list [print find/last/tail name space]
toomasv
08:31This is not the point that you *can* do it differently. May be you want to split names and treat parts separately. Of course you can use split then too. Anyway, the example just shows that it can easily be used.
Your last example works the same either e is just difference of indexes or series starting point IMO.
Oldes
08:34You are right, that current version may be useful in some situations. Which I never needed so far ;-) So I end.
08:36I still have a feeling, that although it may be useful, it introduces exceptions. Just imagine how you would document it. But maybe it is ok. Sorry. Have to work.
toomasv
08:39Generalizing the example, one use-case would be when you need to pop pieces incrementaly from the end of series based on find.
Ok, have a productive day!
hiiamboris
08:41What I have against the current behavior of take/last/part a b is: 1) When both a and b are series, it uses only one argument of the given two. Think of it. It was given 2 positions in the series, it only requires one of them, as the right margin is the tail. If b > a then it uses b and disregards a. If b < a then it returns an empty string (see 2 why this is particularly bad). "34" = take/last/part s: "1234" skip s 2 "" = take/last/part skip s: "1234" 2 s 2) It's not symmetric as normal take/part is: take/part a b = take/part b a 3) It's (as @Oldes pointed out) treating integer part and series part arguments differently, which is not how /part in other places work (it should be func/part a skip a n = func/part a n)
Overall I consider the behavior so confusing that personally I would rather abstain from using it altogether than go through all the pain of modelling in my mind how it will work.
08:48And more differences between Red and R2 to further illustrate the complexity:
10:06What we need is a formal model of series to build all action!s upon, like the one [Ladislav Mercir worked on](https://github.com/revault/rebol-wiki/wiki/Mathematical-model-of-Rebol-series). Otherwise all design discussions derail into exchange of opinionated "Red should do X" with very low S/N ratio.
toomasv
10:06@hiiamboris Some thoughts on your points: 1) Well, kind of. But consider this:
2) If you play a bit with it you'll see that this is not so with take/part (to my surprise). And I agree that take/last/part a b should be symmetrical with take/last/part b a. (er.. probably) 3) What about e.g. copy:
@toomasv re: 2 -- take/part a b is symmetric in R2, in Red it's just buggy (see https://github.com/red/red/issues/4078) re: 3 -- copy is working as expected IMO: copy/part skip s: "abcd" 3 next s = copy/part s: skip "abcd" 3 skip s -2 = copy/part s: skip "abcd" 3 -2 = "bc"
toomasv
11:16But it (3) is (somewhat) similar to take/last/part s: "abcd" next s = take/last/part s: "abcd" skip tail s -3
hiiamboris
11:25@9214 looks like Ladislav's model didn't go beyond a single man's opinion on head, tail and indexes ):
Anyway, I brought up the take problem only because I'm working on https://github.com/red/red/issues/3369 and take crashes it most badly and requires a total rewrite, while most other funcs I can touch only slightly to fix.
I totally support the notion that we need a model. Lack of the model encourages ad-hoc decisions that in the long run will bring only headaches. Current code is such a mess that simply by calling get-length in R/S you get your series' head modified. A modifying get-function! Add to that the fact the most of the series code is duplicated over each series datatype, each with minor quirks. It's a stairway to hell... 500 tests can ensure the most obvious and often used situations are resolved as expected, but tests won't ever cover series operations as a whole and new bugs will never cease to be found.
Let's move past the "we need it" part maybe? ☻ Outline the possibilities, discuss the quirks, reach a consensus, build the utilities that will enforce that consensus in the code, and modify the series code using these utilities? We only need people who are willing and able to express their *argumentative* opinion on the matter. Personally, I'm in.
9214
11:33Start with invariants and some sort of "canonical form". e.g. how series offsets and indexes should be treated by /part.
>> x: [a b c d e f g h]
== [a b c d e f g h]
>> copy/part tail x next x
== [b c d e f g h]
>> copy/part tail x offset? tail x next x
== [b c d e f g h]
>> copy/part skip x add length? x offset? tail x next x length? x
== [b c d e f g h]
>> copy/part next x length? x
== [b c d e f g h]
hiiamboris
12:14Good idea, but I'd firstly reconsider the indexing problem, as this is the foundation, but we don't even have that defined. head < 0 is forbidden throughout the whole runtime AFAIK. Past-tail indexes are an evil we can't get rid of but thing is that it is remedied differently in different parts. The dominating model in the current state I could formulate simply like this: 1) series data is defined on indexes [1 ... tail], where tail = count of items in the series 2) getting an item at indexes outside of the ones defined yields none 3) when getting a slice of the series, undefined regions become empty series 4) head can be any natural number (i.e. head>=1) 5) head > tail is allowed and is not adjusted, it is returned by the index? func as is (contrary to R2 which "lies" that head = tail in this case, although internally still keeps it >tail) 6) series functions, when passed series at head > tail, treat those as series at head = tail
My first question would be - do we agree on this behavior? Especially on (5) and (6) clauses
9214
12:29You're confusing head with index. As for "we don't even have that defined" - consider to (re)read Rebol/Core guide.
12:39Nvm, I see what you mean. Well, it's an intentional simplification. In R/S head is just an integer. head in Red maps to *series* with that integer set to 1. Let's call it index, I agree.
12:46@9214 any specific place in Rebol/Core guide you wanna point me to?
15:48@9214 I don't see anything useful there, sorry. I was hoping it'd describe edge cases handling, but there's only trivial stuff from what I can see.
greggirwin
18:17I'm on board with creating a model for discussion and addressing behavior design. If @hiiamboris and @9214 can head that up, I'll owe you each beverages.
For me, this is a deep and important matter, because our choices should be *forever* and we want to get it right. I am willing to sacrifice Rebol compatibility for that in this case. Many of Carl's designs came from a usability perspective and guessing how things will be used (else, why do we even have a series /part arg option?), and work well in common/simple cases, but may fall over a bit once things go outside those bounds (calculated indexes and such). We can address things in many ways:
1) Make it technically uniform and easy to reason about. 2) Make it easy in easy cases, but confusing in advanced use. 3) Best of 1 and 2. 4) Constrain options to achieve 1 and 2.
Step one is to understand it so we can discuss the options clearly.
@rebolek or @toomasv can probably whip up a script to see how often series are used at /part args. I don't do it often myself.
hiiamboris
18:26So what about :point_up: [October 15, 2019 3:14 PM](https://gitter.im/red/red?at=5da5b83b870fa33a4df7e0b7) ? (read "head" as "index" there)
18:28Are we happy with that, or are we considering deviations from that?
giesse
18:57@hiiamboris I'm good with https://gitter.im/red/red?at=5da5b83b870fa33a4df7e0b7
greggirwin
21:05- For past-tail evil, you mean that we can enforce head's index because it's part of the series structure, but not past-tail because they aren't?
- For 3, would you define " undefined regions"?
- For 5, do you mean it would work as it currently does?
As a result of clear b we got a series' index (9) past it's tail index (1). And there's nothing we can do about it, else we'll have to keep track of all the series that refer to the same buffer as b. Not an option ☺
re: 3: I mean items at i <= 0 and i > tail re: 5: index? skip b 10 is debatable, I'll write a bit about it soon ☻ What I meant is that 9 = index? a even after the clear b operation, as it currently is. R2 returns 1, but should I start adding items to b it will increase index? a until I reach 9, so it's even worse IMO. Still in R2 it is still hackable, but less clear.
21:30Okay, while we're waiting for more voices, let me continue.
As a remark, since index can go beyond the tail, I'm not opposed to letting index go negative either. But I think this change requires a justification. Some sensible advantage. If you guys could think of one :)
But let's think more of the past-tail indexes. Question is - to which extent we allow them? Just some thoughts that come to my mind right now:
1. Since we can (using tricks) build a series with index > tail, and our index? func doesn't lie about the index, we could also allow at and skip do that too. Then we would have:
>> a: skip "" 2
== ""
>> index? a
== 3
>> append a 1 a
== ""
>> append a 2 a
== ""
>> append a 3 a
== "3"
>> append a 4 a
== "34"
>> head a
== "1234"
2. If we accept clause (5) of https://gitter.im/red/red?at=5da5b83b870fa33a4df7e0b7 , then I may formulate it like this: For any series function f and any series a and any series part argument b these equalities hold: (index? a) = (f s index? a) (index? a) = (f/part a b index? a) (index? b) = (f/part a b index? b) Or in other words, a function call does not affect either series' head. Maybe this is guaranteed by how Red evaluates it's arguments (copies a and b cells when passing to R/S funcs) anyway. But on R/S level this is quite a question, and often an R/S caller func may call an R/S series callee func, expecting the same behavior as in Red, while in reality it will be not so without an explicit copy of the cell holding the series info.
3. Speaking of return values. Let's consider:
ai: index? a
bi: index? b
ti: index? tail a ;) a and b are the same series buffer
r: f/part a b
ri: index? r
Let's for simplicity say that f operates strictly on items with indexes ai <= i < bi. It can: a) remove any of these items, moving the following items (and the tail) to the left b) add some more items, moving the following items (and the tail) to the right c) read/inspect these items, make a copy of them, etc. - not moving anything around It's possible that either ai > ti or bi > ti or both. Question is, in which scenarios we return ri > ti?
Some functions are said in their docstrings that they "return on the same index". In this case I say we should follow it to the word and let ri = ai.
Some functions (like sort) permute the data and return on either of the given indexes ai or bi, which one is lesser or greater. In this case I say we should still return ai or bi even if those are past the end.
Some functions return at the index after the changed/found/copied data, which may not be aligned with ai or bi. This is much trickier. Take insert as an example, returning series a "past the insertion". Let's call this past-insertion index pi. I propose we treat it like this: - pi >= ai => ri: pi (when insertion index is past the initial index of a, we advance) - pi < ai => ri: ai (when insertion index is before the initial index, we do not advance backwards) Another option would be: - pi < ai => ri: pi, in this case insert will return on an index before the one given.
Even more interesting is change/part, returning "after the change" (let's call it pi again). It replaces the slice between ai and bi of size s1 with a new segment of different size s2. If bi < ai we can reorder the two, so let's assume ai <= bi. The tail can either go left or right. I propose this: - pi >= bi => ri: pi (after-the-change index is past the biggest of indexes given, we return it) - ai <= pi < bi => ri: pi (after-the-change index is between the indexes given, we return it, even if bi > ti or ai > ti) - pi < ai => ri: ai (after-the-change index didn't reach the leftmost index (happens when ai > ti), we don't advance it backwards) Again, another option would be: - pi < ai => ri: pi (advance backwards)
21:31I see no harm in not advancing backwards. Although it does not follow the docstring to the letter, it satisfies the (naive) expectation that change/insert can't return an index before both series' a and b indexes. But I'm very open to arguments here ;)
21:43Oh, almost forgot. **(4) Equality.** I propose: same? a b is true when a and b are of the same buffer and same index (as currently is) strict-equal? a b is true when for every i >= 1: true = strict-equal? pick a i pick b i (thus past-the-end series are treated as at-an-end) equal? a b is true when for every i >= 1: true = equal? copy/part at a i 1 copy/part at b i 1 (thus past-the-end series are treated as at-an-end again) (tip: copy/part trick is for strings where false = equal? #"A" #"a" yet true = equal? "A" "a")
Like, consider remove/part head b: tail a: "1234" 4: no = same? a b yes = strict-equal? a b yes = equal? a b Even though a and b are of different index and both have an empty buffer
00:37When is the support for 64-bit MacOS (Catalina) likely to be available?
dockimbel
09:52@RonHochsprung Hi Ron, it will take a few more months to get there, we aim at Q1 of next year, though we still have many other tasks to complete before opening the 64-bit branch. We will likely first provide a cross-compiler allowing to produce 64-bit executables from a 32-bit platform so that the Red console can be available asap on 64-bit.
11:29☻ More funny things in the current build, regarding :point_up: [October 16, 2019 12:30 AM](https://gitter.im/red/red?at=5da63a5957c2517c6a15493b), that clause (1) may elegantly solve:
>> remove/part head a: skip "12345678" 6 4
== "5678"
>> index? a
== 7
>> index? tail a
== 5
>> index? back a
== 6
>> index? back back a ;) decreases
== 5
>> index? next a
== 7
>> index? next next a ;) does not increase
== 7
>> index? skip a -1 ;) <> back a
== 5
>> index? skip a -2
== 5
>> index? skip a -3
== 4
>> index? skip a 0 ;) <> index? a
== 5
>> index? skip a 1 ;) <> next a
== 5
>> index? skip a 2 ;) ditto
== 5
>> index? at a 0
== 5
>> index? at a 1 ;) <> index? a
== 5
>> index? at a 2 ;) <> next a
== 5
>> index? at a -1 ;) <> back a
== 5
>> index? at a -2
== 5
>> index? at a -3
== 4
This is where invariants IMO are truly important.
eddyparkinson
23:38Hi, I am new here. I want to know about the early adopter market for Red/Eve/Lighttable etc. I have been working on: https://i.imgur.com/YxytmAr.gif ... i.e. making programming more accessible. Other Examples: https://sheet.cellmaster.com.au/examples
Where would I find out more about the early adopter market? Typical uses cases of early users of Red/Eve/Lighttable? ... This looks to have good use cases: https://www.spreadsheetweb.com ... But I see Eve is table focused, so I assume different use cases exist.
greggirwin
23:57Welcome @eddyparkinson! Red is a general purpose high level language, like Python or Ruby. Red/System it its low level dialect, like C. Those are the target users (devs) for Red the language. Building tools on top of Red, higher level, low/no-code, is where others come in, as well as the commercial arms of the Red project. They will create consumer products and services with Red.
23:58Jonathan Edwards is another person to follow in the table oriented programming space.
eddyparkinson
00:09I saw some of Jonathan Edwards work about 5 years ago. I will take another look, has been a while.
00:12I understand eve shut down - Just trying to understand what they learned along the way about the demand side. Gregg Irwin sent me https://www.red-lang.org/2016/07/native-reactive-spreadsheet-in-17-loc.html
RonHochsprung
02:15@dockimbel That sounds like the obvious first step, and I'd love to have it ASAP. I've been using Rebol for many years.
qtxie
12:37> We are going to add back the pretty printing for float to cover this case. Then another issue https://github.com/red/red/issues/3243 has to be reopened. I'm not sure which one is the better choice. What do you think?
Now form float will try (best) to give a user friendly output and mold floatwill do the precise output. Also you'll get the pretty result in the Red console.
12:39@hiiamboris Great thought about the indexing problem. We should save it in a wiki page or some other places (REP, issue, etc). Otherwise it will be lost in gitter.
hiiamboris
12:43I'll save it, don't worry :) I was just trying to get any feedback
12:44Regarding the form float thing, @qtxie. I think we should output time! in %.Nf format rather than %.Ng, or it becomes unloadable.
qtxie
12:50Also we really need a better place to do those discussions. It really took me some time to find the discuss conversasion about float. I don't remember in which room and gitter search is unusable.
13:29OK this last one isn't a regression, but something more complex. I have only two debug builds which output it as 3e-12. Will have to investigate further.
dander
17:08@qtxie It's possible to download the entire chat using https://github.com/rebolek/gritter/blob/master/gitter-tools.red, and then it's a bit easier to search through the plain text, but still requires a bit of work piecing some parts together. I've had some success finding old things with it.
rebolek
18:52I've just pushed new version of http-tools to my [red-tools repo](https://github.com/rebolek/red-tools). It shouldn't break anything, but if you use it there some new features that should make your life easier. And there's one bug fixed also. So here's the list of changes:
Bugs fixed:
* fixed a bug, where send-request always expect that the reply has content-type field in the header. That's not always the case.
New features:
There's one. The handling of /data refinement was totally revamped (thanks to a suggestion by @BeardPower). content value for that refinement now accepts other types than string! and works for GET method too:
* with GET method, content (expected to be block!) is translated to url-encoded string and appended to the link, e.g.: send-request/data link 'GET [x: 1 y: 2] results in link?x=1&y=2.
* with other methods, content is treaded based on type: block! is also translated to url-encoded string passed as data and Content-Type field in the header is set to application/x-www-form-urlencoded (with one small exception useful only for a very small niche).
* map! is treated as JSON and Content-Type is set accordingly. So you don't have to care about sending JSON requests, it's handled automatically.
* string! is passed as it was before you have to set Content-Type manually, no change here.
00:20I have created my first intermediate code. A for loop running iterating on data tables rows and mapping each column name on a word (as object) .
Here is the code with a simple example:
fordata: function [
"Purpose: iterate a block of code on data block making columns data accessible using column name"
'data-name
"The object name"
data-block
"the source with headings on top"
code-block
"The code to execute"
]
[
headings: copy first data-block
data-block: next data-block
row-obj-specs: copy []
forall data-block [
forall headings [
append row-obj-specs to-set-word first headings
append row-obj-specs data-block/1/(index? headings)
]
do reduce [to-set-word data-name make object! row-obj-specs]
do code-block
]
]
----------- Basic usage ------------
dataset: [
[CUSTOMER_CD Name Contact Role Personal-Number Interest]
[001 "Amazon" "Jeff Bezos" "President" "0012666999" "BOOK: How to keep you money safe from world taxation"]
[002 "Microsoft" "Bill Gates" "Programmer" "0019852029" "BOOK: How to code in Basic" ]
[003 "Apple" "Steeve Wozniac" "President " "001196868FREE" "COURSE: How to make money with free software"]
]
fordata row dataset [
print ["Person: " row/contact "-- Interested in: " row/interest]
]
Here is the output:
Person: Jeff Bezos -- Interested in: BOOK: How to keep you money safe from world taxation
Person: Bill Gates -- Interested in: BOOK: How to code in Basic
Person: Steeve Wozniac -- Interested in: COURSE: How to make money with free software
You can use it for composing and executing code based on data tables or building strings/blocks
Person: Jeff Bezos -- Interested in: BOOK: How to keep you money safe from world taxation
Person: Bill Gates -- Interested in: BOOK: How to code in Basic
Person: Steeve Wozniac -- Interested in: COURSE: How to make money with free software
Customer: Mr. Jeff Bezos Phone#: 0012666999 Interested in: BOOK: How to keep you money safe from world taxation
Customer: Mr. Bill Gates Phone#: 0019852029 Interested in: BOOK: How to code in Basic
Customer: Mr. Steeve Wozniac Phone#: 001196868FREE Interested in: COURSE: How to make money with free software
05:41There seem to be first numbers for Fast-lexer branch posted on the Red Twitter channel ... and those .... look impressive :-)
05:45Posted by Lucinda, so to give her a credit: The numbers so far: Loading 100'000 words (5 to 15 characters, 1MB file): Red (master): 19000ms; Red (fast-lexer): 150ms. And it's with no small amount of surprise & pride that we observe words load a bit faster than even #R3: 1M words (5-15 chars, 10MB file): Red fast-lexer: 850ms; R3: 940ms.
05:45I hope this makes for a Blog article too, as it seems to be kind of a great achievement ;-)
22:17So, I just downloaded red for windows, and clicked to compile... Norton is telling me there is a threat "Heur.AdvML.B". Is this something real, or a part of RED that just scares Norton??
loziniak
12:33@tkslattery050558 It probably just scares Norton. It's a [known issue](https://github.com/red/red#anti-virus-false-positive).
hiiamboris
12:43@dockimbel Here's a bit of a complaint regarding current stack implementation (or usage?).
take works by allocating a new series, where into it moves the taken data.
If you add an assertion assert ser <> stack/top before this line https://github.com/red/red/blob/d7fd28291d7fcc38f1b5e0423c4130829b2ac5cf/runtime/datatypes/series.reds#L1009 , the assertion will crash before the console will even boot up.
Apparently take gets called on a stack cell. Without the assertion, newly allocated cell refers to the same memory as ser cell, ser/node gets overwritten with the following ser2/node: node line, later references to ser and it's node become invalid, and it happily goes into undefined behavior from there on.
And I can't imagine how many more mines like this are there in wait.
17:05Question 1: Is there a pattern we can use to search for more of these cases?
Question 2: What's the best way to make sure we avoid writing more of them, especially in the v2 rewrite?
hiiamboris
18:11@greggirwin I'm asking myself the same questions ☺ But as of now my knowledge of Red runtime and compiler is just not enough to propose concrete solutions (otherwise I would've implemented that already). I'd usually go by making stack more declarative. It should *know* at what moment what cells are *in use*.
As for a pattern, every time I see some stack/something invocation I don't know if it's gonna work properly or not. I can only see the code that is in front of me. When this code calls another code, I can not tell anymore. Since it almost always calls something, I can never tell :) This is the core of the problem: Red stack is modified by almost every callee out there with no way of seeing those modifications in the context of the caller.
greggirwin
19:21And why Forth programs were always, necessarily, small. ;^)
greggirwin
20:12@ne1uno Is there an easy way to run https://gist.github.com/ne1uno/a5d79c0b7a8f9dac65f4737834b900b4 ? Looks cool, but doesn't work for me in a quick console-paste.
>> ? pick
USAGE:
PICK series index
DESCRIPTION:
Returns the series value at a given index.
PICK is an action! value.
ARGUMENTS:
series [series! port! bitset! pair! tuple! date! time!]
index [scalar! any-string! any-word! block! logic! time!]
RETURNS:
[any-type!]
>> ? scalar!
SCALAR! is a typeset! value: make typeset! [char! integer! float! pair! percent! tuple! time! date!]
Note that time! is already in scalar! but is added into index types again. I know of: - pick series integer - pick [1 0] logic - pick charset "abc" #"a" and pick charset "abc" "a" thing - pick image pair
20:20maybe no-wait? thanks for trying, exits in -e build too
20:22the being compiled switch fails, interpreted? need a yes/no/maybe
greggirwin
20:22@hiiamboris scalar! seems a very broad brush for indexing, and some others aren't intuitive. This is a big question, and one that needs design rationale.
20:25At the most basic level, defining what "index" means for each datatype.
20:26And refining the doc string so it denotes the concept of "sub value" for non-series types.
hiiamboris
20:49I can say that R/S code currently covers only the cases I outlined above. Tests are *only* written for pick with an integer.
Last time! is obviously a mistake in [this commit](https://github.com/red/red/commit/96249ccae3ca1fca7d18bf18fe8c844920993009). It adds indexing of time values with an integer, but adds time! into index.
Interestingly, it was an even broader typeset before, including an immediate!:
>> ? immediate!
IMMEDIATE! is a typeset! value: make typeset! [datatype! none! logic! char! integer! float! word! set-word! lit-word! get-word! refinement! issue! typeset! pair! percent! tuple! time! handle! date!]
Changed from [integer! logic! char!] in [this commit](https://github.com/red/red/commit/ea98254634b4cf4d0e2bf1a8ed44ce17f385f8ef). Apparently for maps initially, but that was never implemented. I wonder, what good pick on maps will do? @qtxie might know the plan.
Also if I understand correctly, port! datatype just delegates index to an actor. If so, we might just as well broaden this typeset to any-type!.
greggirwin
21:02Certainly we need to think about the purpose of pick and have @dockimbel and @qtxie weigh in.
meijeru
19:16I notice a change in format of the Red Progress data (https://progress.red-lang.org/). Intentional?
trosel
13:38Hello all! Is this roadmap page up to date? https://www.red-lang.org/p/roadmap.html
It links to a trello board that looks old
13:44One of the things I'm looking for information on is how to build a GUI that actually communicates with APIs. For example, how do I make buttons that hit an API endpoint when clicked?
Oh interesting! Like a special DSL that abstracts regular protocols?
14:29@endo64 is the I/O stuff a priority? Seems like a requirement in order to build an app of any kind of value these days
endo64
14:40IO is the next item in the roadmap (v0.7) so it probably comes just after core team completes the work on fast-lexer branch. For HTTP simple-io is mostly enough.
16:44red mentioned in this thread https://news.ycombinator.com/item?id=21376114
endo64
20:36@trosel Thanks! > Like a special DSL that abstracts regular protocols?
I meant with 0.7 Red will support other network protocols like low level TCP, UDP, DNS etc. so we'll be able to extend or build according to our needs.
20:57> I just downloaded red for windows, and clicked to compile... Norton is telling me there is a threat "Heur.AdvML.B". Is this something real, or a part of RED that just scares Norton?
@tkslattery050558 It is a known issue, some AVs, especially the ones using heuristic scans, are complaining about Red console compiled by Red toolchain. Try to exclude that folder, after compilation you can upload the executable to https://www.virustotal.com Here you can find some info: https://github.com/red/red/issues/3137 https://github.com/red/red/issues?q=is%3Aissue+virus+is%3Aclosed+sort%3Aupdated-asc
rebolek
07:10Documentation for send-request is now available: https://github.com/rebolek/red-tools/blob/master/send-request.md
endo64
07:33@rebolek Cool! If the response content-type is application/json does it convert to map automatically?
rebolek
07:39@endo64 Yes, response is converted automatically based on the MIME type (if it's supported, otherwise no conversion happens).
07:39It's briefly mentioned in the beginning: "Translates response to Red values based on MIME type."
loziniak
09:00I've just noticed, that Red saves console history between sessions. So sweet! Thanks!
18:14Hi guys! You may already have noticed, but there's a new post up on our blog at https://www.red-lang.org/2019/10/october-2019-in-review.html. It addresses those latest changes to the fast-lexer branch, recent contributions from the team, and a few games that have been contributed recently, among other topics. There is a really good energy among the Red team right now as we put our heads together to plan for the new year. We have challenges ahead, but what I love about this time of year is that it's very much about preparations for new beginnings. There's good stuff in the works and I look forward to learning more.
pekr
19:25Could we please inform our FB followers too? :-)
21:05(I'm kidding!) ...I have indeed informed Facebooklandia: https://www.facebook.com/groups/redlanguage
atorres617
05:44Hi All - I am a newbie to Red - Looks like a fun and productive language -
05:45I was concerned about one thing - When I was going to red-lang.org, Malwarebytes was a blocking the page thinking there is a Trojan.
05:46I was actually trying to access the PDF of the slide deck at https://www.red-lang.org/p/about.html
05:47I had to add those two links as exceptions to Malwarebytes and also static.red-lang.org in order to download the PDF. I could only do this using Chrome. For some reason, when I go to https://www.red-lang.org/p/about.html, the tab crashes in Mozilla Firefox.
05:49Is there someone who knows why this is happening? I cannot be the only one this has happened to. If someone is new to the language, they may be concerned about it. I am not really a fan of Rust - I found out about Red by comparing code across languages on Rosetta Code.
ne1uno
05:49page loaded ok for me v70 ffox and and older chrome fork.
atorres617
05:49Ok - thank you. Maybe I will see if there is an update to Firefox.
ne1uno
05:50slow this time of day but people will check, thanks
07:31Mine FF never ever crashed on any red-lang.org section, looks suspicious. I am using our company's NOD antivirus protection, no problems with Red so far ....
endo64
07:41No issue for me too, both PDF download and all other pages are ok.
07:44https://static.red-lang.org/ looks clean on virustotal.com even for Malwarebytes: https://www.virustotal.com/gui/url/65a9e05c55d4ce86269db037c9231cd40e31c474999c144bd54d6093fc5d3cc8/detection
loziniak
11:59Hi! Does anybody know any Red or Rebol code of a **QR-Code generator** that I could use in my commercial closed-code app?
18:50@qtxie anything for 1D barcodes and to compose a label with barcodes inside?
greggirwin
19:00There were old 3-of-9 libs for R2 I think. Haven't seen anyone port them yet.
atorres617
19:08@ne1uno , @pekr @endo64 I see this mention of it happening with Windows Defender - http://www.mycode4fun.co.uk/red-apps The Firefox that I use may have DuckDuckGo privacy plug-in.
meijeru
20:40@GiuseppeChillemi I have a basic program for EAN-8 and EAN-13 (also UPC-A) codes that shows them in a base face, from which you could produce a .jpg or similar. If you are interested I can put it on Gist.
greggirwin
20:58@meijeru if we could also get it in the red/code repo, that would be great. Same for @bitbegin's QR code demo.
meijeru
21:05@greggirwin I would not call my program "curated code". It is more a POC, although it does follow the specification closely. So someone could certainly enhance it. See [this gist](https://gist.github.com/meijeru/5dee1e867dcc6a81d05f72b7c442a183)
GiuseppeChillemi
21:15@meijeru thanks Rudolph, I need them. Yes, I could create a face and then output it as .jpg and print.
lucindamichele
23:31Of note: @dockimbel was kind enough to enlarge upon the forward-looking reasoning behind the recent changes in the fast-lexer branch. A surprise post/narrative on the blog: https://www.red-lang.org/2019/10/a-deeper-dive-into-fast-lexer-changes.html
16:35Be sure to thank @greggirwin and @dockimbel for making it possible!
toomasv
16:39Hooray to @greggirwin and @dockimbel and @qtxie :mega: !
hiiamboris
19:47@greggirwin and @9214 some fun reading for you here https://github.com/red/red/wiki/[PROP]-Series-evolution
And for everyone concerned ☻
greggirwin
19:48WOW! Will have to set aside serious time to read and digest. :^)
meijeru
19:57Congratulations on the _Series evolution_ work! Also, I welcome the updated _Design questions_ page. Should the design of the function spec part be mentioned there too?
hiiamboris
20:03Thanks :) @meijeru Yes, please mention everything you recall ☺
07:43@hiiamboris See [REP #24](https://github.com/red/REP/issues/24). That discussion does not need to be repeated, but could perhaps be linked.
hiiamboris
08:40Ah! If it's a REP, then probably no point in referencing it, as REPs are already all conveniently in one place.
GiuseppeChillemi
09:50I have red the REP link and a question arose: which notation is used to describe the function syntax ::=
make function! []
| func
| has [*] ... And where to find documentation about it ?
21:47On the fast-lexer: I wonder how maintainable this approach is -- what if new lexical elements need to be accomodated, e.g. a new ref! type, will that mean changing a lot of tables and lists?
greggirwin
22:00All tradeoffs. I would love for the old lexer to be kept as an example, and updated to stay in sync. It's probably the biggest parse demo we have.
22:00Then it's also a parallel test implementation.
22:20Maybe @dockimbel can include the ref! form as a placeholder now, since I want it so badly. ;^)
22:21But this extra effort can be a good thing. We don't want to add more lexical forms lightly.
GiuseppeChillemi
01:27Parse + JIT and old lexer will be back on par with fast lexer ?
pekr
05:34"We don't want to add more lexical forms lightly." - so you discourage usage of something like a user types?
greggirwin
17:14If they have a lexical form, yes. They will make Red as data much less interoperable. That doesn't rule out a special lexical space *all* UDTs live in. It may mean they aren't as elegant and clean as standard types, but there are benefits from doing that. They can also be object-based, if the overhead is OK for your use case there.
pekr
18:06Wouldn't such user types have to live in terms of the interpreter? Well, maybe not necessarily, but some hooks to have user defined types (if those are planned) dynamically available in the runtime would be nice to have too ...
18:07After all, iirc blog article might even suggest something like that ....
greggirwin
03:56First we have to identify what the use cases are for UDTs versus, say, a struct! type at the Red level, and functions to operate on them.
GiuseppeChillemi
07:02@greggirwin the simples use case is to identify a new datatype in select, parse, find and other functions able to match a RED type. This would avoid creating convoluted code in those operations. Maybe this round I have a defined proposal and it is very simple. Will write about it later today as I am finalizing it.
15:02User-Defined Datatypes (UDT from now) have been an idea around my, and others, mind for along time. I have imagined manipulating UDT content with custom code that overrides RED actions one; redefining equality and other operations with user-provided functions and many other ideas. But the motto *"keep things simple"* has accompanied my ideations so I opted for a simple one. The main goal of UDT is to simplify code writing and reading so the developer should not write custom select/find/… functions in standard blocks and parse.
Written this, a UDT should be an ordinary block/MAP element preceded by a WORD defining the UDT:
UDT![data]
Or
UDT!#(key value …)
This would let developer use all regular RED expressions like…
find myblock UDT![DATA]
select myblock UDT![DATA]
parse myblock [copy word to UDT!]
Find myblock UDT!#(key value)
select myblock UDT!#(key value)
… and accessed and manipulate DATA like standard blocks and maps.
To create a UDT use:
MAKE udatatype! [WORD [default-data]]
MAKE udatatype! [WORD #(key value)]
The first element in a block is the WORD that will be used to identify the datatype and followed by the default init structure.
For block type UDT a default block could be with data or empty. The block content will always be modifiable during normal operation.
For UDT of MAP type a key/value list with defaults should be provided like:
MAKE udatatype! [UDT-ID2 #(customer-id: none customer-name: none)]
The map could be extendable but it must be analyzed the possibility to provide a flag to make it fixed.
(Also UDT could be of OBJECT type but I write at last because I suppose it would be more complex to implement (also more powerful))
Operations:
Let's create ablock with an UDT:
myblock: [data1 data2 data3 UDT-ID![a b 1 d] data4]
Finding:
find myblock UDT-ID![a b 1 d]
>>[UDT-ID![a b 1 d] data4]
Selecting
select myblock 'data3
>>[a b 1 d]
(note, the result of selecting an UDT is just a simple block/map)
The only "esoteric" proposals I could add is having a validating function to be defined at UDT creation like port REBOL manipulating functions. It is then called at modification (reactor).
Tomatoes and eggs are welcome (as good opinions!)
greggirwin
22:00Thanks for the many thoughts @GiuseppeChillemi. I don't know if we need UDTs for these examples, though. Maps and objects are already UDTs, where the added value comes from having a type field, which can be checked, but which also opens questions on objects, prototypes, inheritance trees, and dependent types. You end up with explosions of types and more syntax.
One alternative is simple: add support for pattern matching on aggregate structures. This can be applied to known cases, but also those we haven't thought of yet. It can also be done at the mezzanine level, so the core language isn't affected.
GiuseppeChillemi
22:50@greggirwin Leave everything working as it is. Just add a TYPE field before actual structures. Everything else will work in the same way apart blocks that will have a different initialization phase. Those UDTs are existing structures with a type before their starting characters.
23:14That fact you do not see the needing for UDT in my examples is because they have not been written to demonstrate the use of UDT but to demonstrate that everything will work exactly just as now. The only diffence is that you can identify a structure by its type, so you can select it, search for it. This will let everyone use standard RED instructions without creating new ones with all their limitations, expecially when you need to identify a block type in parse without UDT. "To udt!" is far easier to write than anything else.
greggirwin
02:55As discussed in the past, this is a significant change. It's also one that can be prototyped at the mezz level, if someone cares enough to do so.
GiuseppeChillemi
08:22@greggirwin Comparing myself and RED to the lifespan of a human being, I can say I am 5 years old. I hope someone could take the task and implement it. However I will take a look to RED source code just to try to understand how difficult it could be. I think the modification should be done to: the lexer, datatypes, actions and what else ?
toomasv
09:45@GiuseppeChillemi But for the examples you provided no UDT is needed. ALL of these can be done with perfectly normal Red code:
10:02@toomasv the proposal is to have a UDT before a structure to identify it using FIND, SELECT, and especially PARSE. It is intentional to have all the remaining working as they are. Its main purposes are:
to write short code as find udt! , parse x [to udt! ... any udt!]; having blocks initialized with a starting structure and; hopefully, having a reactor when block/map is modified.
The power of the proposal is all in having just a UDT! and everything as before, so it should be implementable with a cost that is near to 0.
hiiamboris
10:18So what you actually want is, an ability to alias any of the Red types with a custom name (and datatype id). You want to keep all the series functions working on it as they do on the associated Red type, but at the same be able to distinguish those using some functionality (it doesn't make sense to do that only for find, select and parse though).
10:20What you need to define is: - how that fits gracefully into the whole picture (start from comparisons ☺) - how does it simplify the user code
GiuseppeChillemi
10:25@hiiamboris I have mentioned only those instructions just as example as enumerating all would lower readability of the post.
10:27Also I propose to alias only blocks, maps and eventually objects as they makes more sense than aliasing a number or a string.
10:28Those are the only types where simple and complex structures could take house.
10:35Without UDT every RED instruction which relies on type identification in part or in its whole working, needs extra code to find and operate on the untyped structure, while with UDT you seek and identify a structure like you do with ordinary RED
18:48@hiiamboris I have thought the whole day to you words: "so you want an ALIAS...". I have tried to look to the scenario from your point of view and I have realized my proposal is 99% a request for an alias. But aliases mean that the underlying container is the same with a different name on equality checks or when you search for it. My proposal needs that BLOCK! = UDT![] is false and where Find UDT! returns true a Find BLOCK! should return false.
greggirwin
19:56I added a few words to https://github.com/red/red/wiki/%5BDOC%5D-Red-Should...-(Feature-Wars)#easier-custom-datatypes
19:57My current stance is that this is not needed in Red, and won't make it a better language. I'm happy to be shown the error of my ways though. :^)
GiuseppeChillemi
20:16@greggirwin thanks for your article and links. Could you, or someone else, point me to the parts of RED sources relevant to learn how datatype work? I mean definition, actions, lexer and anything else relevant to this task.
22:00@hiiamboris Just a last note: I have read some sources and without any explanation of RED sources and design implementation I see my enlightment very hard to reach !
dander
22:09@GiuseppeChillemi have you seen any of the [specs documents](https://github.com/meijeru/red.specs-public/blob/master/specs.adoc#types) written by @meijeru? Maybe not the exact focus you are looking for, but there is probably some useful information to you in there.
lucindamichele
22:22I should also chime in, @GiuseppeChillemi , that additional documentation is being collected for a more comprehensive base of resources--your observation is appreciated!
GiuseppeChillemi
22:36@lucindamichele In Italy we say "Rome wasn't been built in a day". That's true for RED too. I have to be patient and wait.
22:38@dander I have partially read it but it does not help so much if you want to start navigating and understand RED source.
Oldes
08:25My humble opinion is, that what @GiuseppeChillemi was proposing is more a struct!, than user defined type. And that it would be better to start with _typed_ handle! type instead of some sort of udt!. I mean... now handle! in Red is just an constant integer pointing to some internal resource. I believe that handle! should have a type, so it could be tested as a function arg. Example:
08:26query function could work with handles to get data from the internal structures.
rebolek
12:59I fixed problem with my [builds](https://rebolek.com/builds/) (missing soft link), so they are working again.
GiuseppeChillemi
09:54@Oldes I do not know about handles and the implication to consider my request and the structure type/alias under this light.
Oldes
11:42@GiuseppeChillemi no problem. handle! in Red is just a pointer to internal resource. No need to know it if you don't live also in Red/System. Above is not something what is implemented in Red. But I believe it should be one day.
11:47When I did several Red bindings years ago, I was using handles all around. For example in [Bass binding](https://github.com/red/code/blob/749f4662320068da6d5bc5531ac25ea0282215d9/Library/Bass/bass-test.red#L26-L33) you can see that drum, music, channel and loop are all handle! type, unfortunately not typed yet.
11:49As I said, your example more evoke old [Rebol struct! datatype](http://www.rebol.com/docs/library.html#struct)
11:50Where it would be nice to be able have it _typed_ somehow (have unique name of the struct defined)
11:53I never figured out, how should work the unfinished _user defined type_ [utype!](https://stackoverflow.com/questions/26780398/whats-known-about-utype-in-rebol-3) which was planned for Rebol3. My opinion is, that it is not needed and typed handles and structs could be enough. It was more importnat in days when Rebol was closed source and Red was not born yet with its Red/System level.
11:59Everyone who request user defined types should read Brian's comment [here](https://www.curecode.org/rebol3/ticket.rsp?id=2137)
GiuseppeChillemi
12:43@Oldes I have read Brian's comment I do not know whether the 64 datatypes limit applies RED too. However, I have looked at STRUCT! datatype and yes, it is very similar to my request. Over all, having aliased types for blocks/maps (and eventually objects) is the simplest and best solution I can see.
rebolek
12:45Red has a higher limit (128 IIRC), but the rest of the comment applies.
GiuseppeChillemi
12:45Later STRUCT! type working or complex datatypes could be added.
12:46@rebolek Do you think that aliased existing types could have such kind of limit?
rebolek
14:28@GiuseppeChillemi what do you mean by aliased types?
I think it's 32k right now, but can be increased to 1M if the need arises. Plenty of space in the header: https://github.com/red/red/blob/1d32938a2c39286c14173a4ff78f21dd3c17d905/runtime/allocator.reds#L22 Some bit fields only make sense for a certain type so it's easy to unify those.
17:20typeset! becomes the real limit in it's current implementation, 3x32 bits = 96 types. And though the implementation *can* change, it will be unwise to extend it, since we have typechecks on every function call, and they have to be real fast.
GiuseppeChillemi
17:58So, typeset is based in single bits and not a combination of them?
18:21I work daily on postgresql databases with my favorite Rebol 2. I wish I could do this with Red...
18:23Okay; then I'll wait for 0.7. I guess that once ports will be done, the author of that good old Rebol postgresql driver (http://rebol.softinnov.org/pgsql/) may be available to bring this magic to red.
18:56@Oldes I agree. However if something like utype! is added, nothing prevents you from (ab)using system/lexer/pre-load and reinventing whole syntax.
I've digged thru the datatypes enough to say the the code complexity of each action! is not O(n) where n is the number of datatypes in Red. It's not O(n*n) either, but somewhere inbetween. And I've no idea how actions on known datatypes should take care of (possible) user-defined types.
GiuseppeChillemi
19:30If there has been a discussion, and a description, about what are actions and how it relates to datatype working, I would like to read it as actions seems to be at the core of datatypes. Has anyone a link to some documents/threads or would please help me explaining this basic item of RED ?
19:39Note, I have read [this](https://doc.red-lang.org/en/datatypes/action.html) but it is not explaining so much to understand the big picture.
greggirwin
20:20I don't support abusing system/lexer/pre-load, and (in the long view) there will almost certainly be special cases where a new lexical form makes sense. We can't see the future, so we can't rule it out. But, and this is key, how much value does each new one add?
I believe that each new lexical form adds less value, and there is a point of diminishing returns. This is not just a lexical problem for Red, but for humans. We have limited capacity to remember rules, and a constrained hierarchy helps enormously here. Think more like linguists, and less like programmers or mathematicians.
In language we have words and numbers. Numbers can be represented as words, with their notation being a handy shortcut for use in the domain of mathematics. And while we classify nouns, verbs, and adjectives by their use, they are all words, and don't have syntax specific to their particular part of speech. That's important because a single word may be used in more than one context, for more than one purpose.
This is interesting, as a tangent, because human language can be ambiguous, though some synthetic languages try to eliminate that (e.g. Lojban). The funny thing is that it's almost impossible to write poetry or tell jokes in Lojban. Nobodyº speaks Lojban. This ties to programming because, while we all know the strengths and value of strict typing, and even more extreme features and designs meant to promote correctness, dynamic languages are used more at higher levels. Why is that? Humans.
When Carl designed Rebol, it had a goal, and a place in time. He had to choose just how far to go. Even what to call things like email!, which are very specific to a particular type of technology. This is what gives Redbol langs so much of their power. They were designed as a data format, meant for exchanging information. That's the core. What are the "things" we need to talk about with other *humans*, not just other programmers.
Do I want new types? ....I'm pushing for at least one. Ref! with an @some-name-here syntax. It's not username! or filename+line-number!, or specific in any way. It's very general, as lexical types should be; their use and meaning being context specific (the R in Redbol, which stands for "relative"). I also think ~ could be a leading numeric sigil to denote approximation. It came mainly from wanting a syntax for floats, to make it clear that they are imprecise, but it's tricky, because it could also be much richer, and has to take variables into account. ~.1 is easy, but what about x = ~n+/-5%. Units are also high value, but they are just a combination of words and numbers. Still maybe worth a lexical form.
When we look at what Red should support, and the best way to let users fulfill application and purpose-specific needs, we can learn from the past, and also see that there is no, single right answer. Structs, Maps, Objects, data structures and functions versus OOP, strict vs dynamic.
As Forth was all about "Build a vocabulary and write your program in that.", think about what constitutes a vocabulary; a lexicon. It's a balance, in Red, between generality and specificity, human friendliness and artifice. So when we ask for things, myself and Nenad included, we should first try to answer our need with what is in Red today, and see where our proposed solution falls on the line of diminishing returns. To this end, we can and *should* abuse system/lexer/pre-load for experimentation.
meijeru
20:43@GiuseppeChillemi A basic introduction is to be found in the spec document section 7.4.2, quoted below: The definitions of the actions are fixed at the start of the toolchain’s operation. No new actions can be made by the user. In fact, during initialization of the toolchain, each action name (word! value) is made to refer to an action! value that consists of a spec similar to the <argument-spec> of a function, and an action number. Also, a table is prepared that contains the addresses of the primary Red/System functions that handle the actions, indexed by the action number (their names are the action names followed by *). Subsequently, a dispatch table (action table) is prepared that contains entries for each combination of action number and type of first argument for which the action is defined. As suggested before, this initialization will fill the entry with the address of a Red/System function handling the action for this combination.
GiuseppeChillemi
20:49@meijeru Thanks, I will reply to this topic in RED/HELP. Very interesting.
23:22@greggirwin The relativity of expressions in the human language and its symbols are handled REBOL design in a great way, so they are in RED. I am against the proliferation of datatypes in RED, as many datatypes would be specialized ones that few users would use. Implementing them would waste the human ed economic resources of the RED team. I totally agree with you when you write (it happened at different times) that with the proper mix of actual building blocks of the language you can build quite everything. I think also that the language should make easy to add some features so they could be implemented independently from the core team by the direct ideators. Also, I think that a new feature should be usable without rewriting, or loosing, half of the most commonly used RED functions, otherwise we have lost simplicity! This is the reason why I asked for UDT, which in its current requirement just a name tied to a block/map with an initializing structure. Those hours needed to create the code to handle insertion of multiple elements in a block (the structure elements and its identifiers); the replacement of FIND, SELECT with custom ones; the writing of special PARSE rules; the analysis of the possible interferences of the preceding words of my structure and many other problems... they all would disappear if I could write find X ![]. With it, magically, all RED code would be able to identify, seek and manage those structures with just 1 word: their ID, and with all language commands. Isn't that simplicity ? One addition and you save (re)writing and complicating everything ! And what about having custom structures in structures ? I would avoid thinking of them now as I am going to sleep and I do not want to have nightmares !!! And, yes, you are right: system/lexer/pre-load is my (unknown) friend but I still am not at the level needed to use it, so I hope to convince you all how useful and code saving is ![]. I have a great willingness to learn but hope my request will be analyzed and accepted before being able to handle RED pre-lexer. I could write examples if I have not been able to provide enough arguments for this request, just ask for them if they are needed.
eddyparkinson
00:45Database? ... Please can you help. Is there a database that works with Red. I have searched "site:https://www.red-lang.org/ database" but could not find any answers.
greggirwin
01:08[SQLite](https://github.com/red/code/tree/master/Library/SQLite). @Oldes can probably say if it works with current versions.
Oldes
08:33I don't know... I have no use for databases now.. just try it :-) Also I should note that it was just a prove of concept.. there is plenty of room for improvements.. like real port integration (there was no port 2 years ago)
20:11> Database? ... Please can you help. Is there a database that works with Red. I have searched "site:https://www.red-lang.org/ database" but could not find any answers.
I'm not aware of client-server database working now in Red. However, I use daily Rebol 2 along with PostgreSQL databases, it works very well. As the author of that driver (https://www.softinnov.org/rebol/pgsql.shtml) happens to be the same author of Red (bonjour Nenad! ;-)), I strongly hope that, soon after ports will be implemented in Red, such driver would appear.
20:18By the way, there is also a MySQL driver from, still, the same author. And for SQLite, there is also a driver that works well in Rebol: http://www.rebol.org/view-script.r?script=btn-sqlite.r
greggirwin
21:32From [red/bugs](https://gitter.im/red/bugs?at=5dc5cc18c26e8923c4ed7576) @meijeru, I am quite familiar with R2's email design. It works well in simple cases, a single user or application for example. Our goal is not to copy implementations, especially when there are better ways. Persisting it can be done, of course, and ideas are in the works for general app configuration support. This is not to say that system/user is a bad idea in general, but I think it's a bad idea to hard code a send function against email info there. It's simple and seductive, no doubt. Security, as Nenad noted, is a big issue. Another is concurrency. As soon as you need to send 2 emails concurrently with different configurations, or allow editing system/user while sending, global settings fail.
While Dependency Injection can be overdone IMO, it can also make sense at times. This may be one. It also ties to a Capabilities model, which is worth keeping in mind. But all send needs is the information, which can be given to it as an argument. Send could be made even more email like in its interface:
send compose [
From: a@.b.com
To: v@w.xyz
Subject: (rejoin ["This is important! Call me by " now + 1:0:0])
{
This gets a little tricky, because we may want to `trim/auto` the body.
}
]
Where does the mail server info come from? Good question. I have a lot of emails, and don't want to edit %user.red or AppData, or code, to choose. I wrote a fairly extensive R2 email configuration system that made things like this easy and extensible. It's not fancy, by any means, as all the config data is just loadable files.
My long-winded point is that the core should be designed for this, and a higher level wrapper can provide defaults for the simple case if needed later.
00:51@melcepstrum quoting @Oldes response from above, precisely in relation to complex numbers.
> Everyone who requests user-defined types should read Brian's comment [here](https://www.curecode.org/rebol3/ticket.rsp?id=2137)
rebolek
08:29send is such great name for a general sending function that I always found it bit sand that it was wasted on just email in R2.
pekr
08:58Yeah, sand is much more useful, than having it wasted on a desert :-)
09:07Otoh in the past, I was thinking about "polymorphism" (if it is a right term here), because I did not like the do, do-browser, send, send-server, etc. kind of stuff, which was done to not overload the main functions ....
09:41btw - I have found this old gem - Rebol/services ... wonder, if anyone ever tried that in the past? At least it looks like a nice dialected messaging infrastructure .... https://github.com/revault/rebol-wiki/wiki/Rebol-Services-Tutorial
greggirwin
16:58@pekr, I experimented and even deployed some things with Reb-Services (a.k.a. LNS = Lightweight Network Services). Nice ideas, but never completed. There were some issues that led me away from it, but we can definitely learn from it.
17:14I can only guess. Rebol never took off, and it was a subset of that. So only a small number of people ever tried it. It was functional but not "complete". That is, it needed more work. Then it was abandoned.
pekr
18:03I thought it would be Rebol/IOS NG, but apparently it never properly took-off. I just hope that in some sense Cheyenne NG will emerge and we will get some RPC stuff :-)
GiuseppeChillemi
10:02@pekr @greggirwin Thanks to your messages today I had a vision of RED sending blocks of code to other machines in a data center to run another instance of a web server for managing part of the traffic or to perform joined computing. I think that once we will have full networking the "only" missing basic requirement would be the transferring of the current state of the interpreter for situations where it is needed live state migration. RED computing cluster ahead !
meijeru
10:20@greggirwin I agree that a solution for send could be to supply server information as a separate argument. The function should be kept as basic as possible, while the full capabilities could be implemented using the port schemes smtpand esmtp.
GiuseppeChillemi
11:30@meijeru I agree, actually I do this to query databases using a
query "querystring" [server "servername" user "username" password "password"]
syntax and it is very easy. I can also store access data in a block
18:38reminder that there's still interest in getting Redlang on Exercism https://github.com/exercism/request-new-language-track/issues/45
greggirwin
21:36Good to know. We have it listed on https://github.com/red/red/wiki/Advocacy, but no details about what needs to be done to support it. @gltewalt might have done some R&D there, but I can't remember now. @trosel if you'd like to add a section to that wiki page, where we can track what needs to be done, that would be great. Thanks.
DaBrondo
14:39Good morning (from the US). Quick question that I'm sure has been asked before: When will Red be available for 64bit only macOS Catalina?
18:27I'm missing it too sometimes. If only foreach could provide the series head or index as well.
greggirwin
19:04I miss it sometimes as well, and for too. Only used in a few important places, but it sure made those nice and concise. I've tinkered on some, but the main thing is not knowing if they add enough value to be included in Red by default. I always misplace my old R2 func count notes. Need to dig those up.
20:13forall dec [if all [(first dec) = s1 (second dec) = p1 (third dec) = v1][remove/part dec 3]]
atorres617
02:57Mybunderstanding is that it may be possible to use Red for Android, ios, web/Linux (or Windows) so that only one codebase is needed. Does anyone know if it native GUI will be available. Does anyone know how soon that will be available via the roadmap? I recently learned of Kotlin Native-there aren't that many options like that available. Thanks
03:10-My understanding. They call it multiplatform programming.
greggirwin
04:08Windows is the most robust GUI, then MacOS, then Linux, then Android. The next step on Android is to move to the App Bundle format, and away from the APK. IOS is not on our roadmap.
04:37Found my old func count notes. It was from 2012, based on rebol.org scripts and my own, IIRC. Tops funcs, in descending order:
if 28979
func 26409
either 18387
copy 14141
make 11626
return 11488
set 9751
not 9648
append 8464
find 7432
all 6943
= 6799
print 6446
any 6053
to 5999
reduce 5613
+ 5592
- 5589
does 5504
length? 5497
insert 5199
mold 5143
forskip was used 203 times.
Funny how often return is used. A simple compiler optimization could be just to see if a single expression follows it at the end of a func and omit it. I imagine people will use it a lot, no matter how much we say they don't have to.
pekr
06:27@greggirwin: "IOS is not on our roadmap" it is probably fine to state it as a fact, but strategically wise I am not sure it is a wise decision. Our company starts to build mobile agendas to our ERP system. Even if our internal apps could follow one platform (and we chose Android), the publick portal access needs to support both platforms. So - how to handle that effectively? So far, external suppliers are using Flutter and in half a year, I will have to make the decision for internal creations too ....
06:28I would also like to know, what is the state of the WebAssembly? It should be part of browsers nowadays, but did it took off and is widely used? Can't here/read much about it in the public .... (just thinking of how to get Red into the browser) ....
hiiamboris
08:40@greggirwin what are the stats for forall and foreach and for?
10:59+1 for IOS, it is a huge market. I have a couple of mobile applications I would like to develop and would be terrible to use another programming language just for this platform. Code once and run everywhere is a great advantage and source of attraction for developers and companies. I don't know the reasons for this choice but the team should have many to cut out one of the biggest platform available.
pekr
11:35I think it might be related to time resources, hence I think Red Team might have already full schedule. I would like to believe, that at some point later in the future, iOS will come too ...
12:52@LFReD_twitter See [Red/System doc](https://static.red-lang.org/red-system-specs.html#section-15.1)
LFReD_twitter
13:12Yeah, I saw that. I just don't get it and the windows example doesn't work.
13:14Looking to port some parts of old Rebol developments to Red. I just sourced out one project on Git https://github.com/LFReD/rash
13:17Some of the old Rebol developers may remember this.. it's a chat bot with some advanced features. IF you have a windows box, give it a try.. grab the Rash 1.0 folder, run Rash.exe, then demo.exe. A small floating blue button will pop up, click it and say hello :P
13:18I'll get around to writing some docs eventually ha!
13:23There's a dialect for the AutoIt.dll in there that may come in handy for Red users.
toomasv
13:26I remember I used user32.dll [here](https://github.com/toomasv/send-keys/blob/master/win-shell.red) and it worked. But I'm newbe in R/S.
LFReD_twitter
13:35Yeah, that's it. Just want to abstract that all away :)
pekr
14:40@LFReD_twitter Just a note - you can wrap libraries in R/S. Apart from that, there are other planned features in that regard, namely the way to dynamically load libraries. If I remember correctly, it is planned for both R/S and Red itself ....
Oldes
15:31@LFReD_twitter your repository is full of binaries, you will not find many people willing to open these. What is purpose of it? I'm old reboller and don't remember it.
LFReD_twitter
15:49Fair enough. Skip the binaries and drop a copy of Rebol/View into the main "Rash 0.9 Source" folder and 'do' Qtray.r
15:56the gui is a flash .swf file (this project was last updated in 2005 :) the gui.exe is just an executable of the flash .fla that's sourced there as well, but feel free to make your own.
15:57The Rebol code is communicating with the flash file via port 7000
16:04The 'purpose' is to migrate some of these features to Red. This is just the start, there's a good 15 years of natural language processing, triple store and graph db, AI (in a 90s sense of the term :), an ERM and tons of other bits and pieces.
16:20If found the manual for Rash.. it's on the project's Git wiki .
17:32Oldes, we were 'debating' Flash and Rebol 14 years ago..
20:00Not sure if this is the right forum. I have really appreciate what Red aims to do. I recently watched a video by Alan Kay (starts at 4:15, audio isn't great, works with CC). Alan Kay was at Xerox Parc. Xerox Parc came up with the rhe original Internet and other innovations (Apple, Microsoft copied things like the GUI, mouse from them). Here he talks about the richness and flexibility of their software and how modern softeare does not come close - https://youtu.be/nOrdzDaPYV4
LFReD_twitter
20:09Here's another Virtual Assistant made with Rebol View back in 2001? It's a little more stable, more features and uses view panels rather than Flash
https://github.com/LFReD/Rebol-Q
greggirwin
23:50:point_up: [November 17, 2019 11:27 PM](https://gitter.im/red/red?at=5dd239cb35889012b12b41f0) @pekr, of course we want to run everywhere, completely robust, fully supporting all native features in a portable way, but we can't...yet. The question is not "Can we support everybody?", but "can we build the best tool possible for *some* people?" If you were in charge, would you choose to slow development on all platforms, and have them less robust, in order to support IOS? If so, who is the target market that will pay you (and what is the product), for IOS?
No plan for WASM either, at this time. It's been talked about, and some R&D done, but is not a short term goal.
00:02For the record, I would be fine with forall and forskip being mezzanines, as in R2. Forall is a subset of forskip and became a one-liner when it was redesigned. Before the redesign, both were dead simple. e.g. this was forall's original body:
while [not tail? get word][
do body
set word next get word
]
Forskip just used skip instead of next. The redesign added arg checking, resetting the series word, and returning the body's result in forskip. Then forall became: throw-on-error [forskip :word 1 body]
LFReD_twitter
00:16It seems redundant, unless there's some speed benefit, but given the speed of modern cpus and ram these days compared to 20 years ago, it's becoming a moot point.
00:25Same goes for crawling blocks etc in general. O(n) is becoming a non-issue except in the most extreme cases.
greggirwin
01:00For me, an important aspect is leverage. The more we write in R/S, the more work it is to maintain and extend (in most, but not all cases), and the speed or features needs to be justified. In this case, you're interpreting a body no matter what, so you take a speed hit. And if handling break/continue is easier to do correctly in R/S, we should fix that for Red. We can cover a lot of control func cases ourselves, but allowing others to write them is a key feature of the language.
So that means every second forall is actually forskip. A must have then.
meijeru
10:16@LFReD_twitter Your Rash repo on Github does NOT contain Rash 1.0, but only 0.9. Moreover, the manual refers to the website powerofq.com which is not anymore yours, it would seem: it is for sale. Since I find your work interesting, I would be grateful for more accurate references.
10:25@dockimbel I note that some (significant) advances in R/S are made by you in the fast-lexer-date branch. Wouldn't they be more properly committed in the master branch? And what about the other fast-lexer-... branches? Have they now fallen by the wayside?
dockimbel
10:36@meijeru Branching out for sub-tasks is the common way to work in a version control system like git. At some point, the relevant branches will get merged and all the final code will make it into master.
10:53Guys, once you are at it (R/S), you might add first class arrays 😜
GiuseppeChillemi
11:38@greggirwin As of 2018, there are [1.3 BILLION IOS DEVICES](https://www.macrumors.com/2018/02/01/apple-now-has-1-3-billion-active-devices-worldwide/) . It is a huge user base and either companies developing software, and their customers, want to be there with a product for both IOS and ANDROID. I have worked in the area of mobile applications and the biggest competitive advantage you can have to be adopted from such companies is language which let you built solutions on Windows(server-side) + Android and IOS, or Linux(server-side) + Android and IOS, which also mean Webserver + IOS and ANDROID. If there are actually no resources to target IOS, my advice is to have it as soon they become available. It would let RED be on the tables of those companies as a candidate language.
pekr
11:41I think, that Red Team knows :-) Maybe bitbegin might focus on OS-X/iOS once Linux View is finished? I wonder if there is any other talent in the community, we might eventually help to finance/sponsor?
11:42We might be off-tipic here, wonder where would be the best place to talk oportunities ....
rebolek
11:44Supporting iOS is not just a question of GUI.
LFReD_twitter
11:44@meijeru I dropped it back to beta given it's 14 years old and hasn't been updated at all (including removing old domain urls). I just dumped it there for future reference..you'll have to take it as it comes as I'm not going to put much energy into it, as the point is to glean some of the algorithms and functions and port them (if possible) to Red.
By the way, that manual refers more to the Q version, which I has it's own repository. Give that a try, as it's more stable and has more features .
It's not my intention to clog this room with Rash and Q questions, but to throw it out there and use it as the start of a more important discussion.
GiuseppeChillemi
11:46Seems such number are not totally correct. The number of devices is [2.6 BILLION](https://www.lifewire.com/how-many-iphones-have-been-sold-1999500).
11:47@rebolek which could be the limits of an iOS port ?
Oldes
11:57@GiuseppeChillemi I would guess that mainly 64bit support requirement.
12:05Not mentioning that nobody knows if application made in Red would be approved by Apple into their store because of its dynamic nature.
LFReD_twitter
12:14Here's a question for you guys. When working at such a low level of development, do you still appreciate the higher abstraction level of Rebol and Red?
12:14I mean, I have no idea what you guys are talking about.
12:15I never took a computer programming course (unless you call lining up behind 20 students back in 1977 with a handful of punch cards waiting your turn to run a 30 line basic).
12:17But I wanted to learn, and in 1998 I had some spare time.. so I started reading "How to Program in C+" books etc. I simply could not wrap my head around it. But then I came across Rebol, and it just made sense for some reason.
12:19> ... But then I came across Rebol, and it just made sense for some reason.
Sounds familiar... We all know that "some reason"...
planetsizecpu
12:19Don't loose the focus guys, 1.0 is the main goal that must be achieved, disturbing the main task is not worth, I think after a complete rewrite for 2.0 -as planed- would be easyer to reach IOS.
pierrechtux
12:20Sorry, I've been out for a long while, I'm trying to catch up, so please excuse my ignorance: what is the current main 1.0 goal and its focuses?
GiuseppeChillemi
14:21@Oldes I have asked myself the same question: would such a dynamic code be accepted from the store ? I think the answer is positive until we totally change the nature of the app.
rebolek
14:29For anyone interested in using Red as CGI, I added some info to [CGI wiki page](https://github.com/red/red/wiki/%5BDOC%5D-Using-Red-as-CGI) how to read binary data (like images etc.).
endo64
14:57Great! Thanks @rebolek , what happens if buffer is not big enough for the POST data? Crash or read-stdin returns a value like false or none?
GiuseppeChillemi
15:31Just to end the discussion about iOS. Dynamic code is now permitted but: *The review guidlines have changed and now permit javascript to be downloaded so long as it does alter the primary purpose of the app or provide functionalities that are contrary to the advertised purpose of the app* . [Source](https://stackoverflow.com/questions/19949174/is-it-feasible-to-load-code-logic-dynamically-in-ios-app) last comment ATM.
16:17@endo64 IIRC it crashes. But as this will be replaced by ports, it's not worth filling ticked for it.
GiuseppeChillemi
18:01Side note: today a friend a mine found me writing my last messages in RED/RED. He is working for an international bank selling Android based POS and mobile payment terminals. He has been really interested in RED on Android and its "concise" development capabilities. Just imagine RED taking normail and **BITCOIN** payment on those devices and you will figure out how big is our potential. I have no knowledge of other programming languages with **BTC** network-based transactions, smart contracts , a GUI system and capable of running on Android devices. So, go on boys ! Market is waiting for our RED based solutions. We are ahead of competition and I am 100% we will all have great success. The exchange I had with my friend **opened my eyes** on **how useful it could be having BTC transaction already in RED**.
LFReD_twitter
19:09Yeah. Rebol never had a killer app... it was the killer app.
However, it was a killer app that only appealed to what, a couple hundred developers? Carl spent a good part of his life developing Rebol and where is it now? There was great talent there, and there's great talent here, but it would be a shame if after all this development, Red falls the same way... a killer app that nobody wants.
19:13I agree with @GiuseppeChillemi ... the driving force behind Red development should be towards some kind of app with broad appeal. I'm sure this is nothing new to Nenad and the rest here at all.
GiuseppeChillemi
20:49@LFReD_twitter Your fears are natural but Carl spent his life creating REBOL... and US all. While REBOL is dead, RED is in its Alpha stage and happening now. We have great energy and projects, we have experience. While in 2001 no one was so skilled to produce great applications, now we are able to create them. The past is the solid root of our future. REBOL had no one but Carl, RED has all previous and current REBOL developers. So, the starting point is different and we have greater chance to be successfull. (I would continue in [chit-chat](https://gitter.im/red/chit-chat) to avoid going to off-topic- My next reply will be there)
22:50I don't know if this has come up before, but the name 'Red' is about as generic as it gets. When doing any kind of search, I've used "Red Language" in the query, but this seems wrong. Have you guys thought of using something more distinct, if not completely unique, or am I missing something?
greggirwin
23:18It comes up from time to time. There is no plan to change it.
rebolek
08:13@LFReD_twitter I'd like to remind you about languages with generic names as "C", "Lisp" or if you fancy newer stuff, then "Rust" or "Go".
greggirwin
08:16:point_up: [November 19, 2019 1:24 AM](https://gitter.im/red/red?at=5dd3a6a6fd6fe41fc0af6b65) I don't remember @dockimbel's reason for not wanting forskip, but if we limit it to positive skip values, it shouldn't add much complexity (skip size and overrun check) to the current forall* code, which then becomes a skip of 1 special case.
08:23@greggirwin Perl , B, D, E, F, ..., Java, Logo, ... it's a game we can play forever :-) OTOH there are languages with clearly distinguishable name, like Brainfuck, SOPHAREOS or MHEG-5 (I just randomly picked some names from [this list](https://en.wikipedia.org/wiki/List_of_programming_languages)), but does it mean they're better known than languages with generic names? I doubt it.
GiuseppeChillemi
09:34@rebolek the argument "because others do this" does not help improve the situation. I have found about every Rebol page in the world during my last year researches, while finding basic Red documentation is difficult and I had lot of missing pages. This is not the welcome we should give to newcomers and it is something we should improve. Red team already expressed they actually won't change the name. I am not a SEO expert, have you a solution/proposal to have our pages more visible?
dockimbel
09:49@GiuseppeChillemi > while finding basic Red documentation is difficult
10:11A longer search string is needed and such longer search string is not guaranteed to return the same density of results as having a distinctive name.
10:17I am not criticizing ANYTHING. People usually take seconds to make an opinion on something (and someone). I think it is important to not give newcomers searching for us and docs the sense "there is nothing, this language has not a user base, nor documentation" during first searches. We have discovered that a unique word give better result, so take it as an instrument to consider and not something which lowers the value of RED and its name.
10:20If you have a better solution for SEO optimizing mine and all web RED pages I (we) will create in the future, I will adopt your recommendations and instruments to help newcomers find those pages with natural and intuitive search strings.
planetsizecpu
10:54> Sorry, I've been out for a long while, I'm trying to catch up, so please excuse my ignorance: what is the current main 1.0 goal and its focuses?
12:16@fvanzeveren I've incorporated your [Windows fix to HTTP-tools](https://github.com/rebolek/red-tools/commit/75a60b45942ca151405101fdf82e4e83fecfb3a8), thanks again!
As I wrote, I am working on some changes to headers structure (but fortunately in a separate branch, so it shouldn't affect anything currently :smiley: ), once it's ready, I'll write about the changes.
Oldes
12:25@GiuseppeChillemi I don't think that generic name Red is such a problem, you can always use red lang or something like: reactive site:red-lang.org and you will be fine. Rebol is older and so have a little bit more pages. From the SEO view it would help to have a regular Red page and not just a blog. But I think that having stable language is more important than have nice web page.
rebolek
12:28qwerjkladf returns nothing on Google, so it may be good name from SEO point of view.
GiuseppeChillemi
12:34@Oldes > you can always use red lang or something like: reactive site:red-lang.org and you will be fine
:point_up: * ... find those pages with natural and intuitive search strings *
Oldes
13:44reactive red lang search string is not natural and intuitive enough? Do you have any better solution? Changing language name at this phase is a nonsense.
hiiamboris
13:47I once proposed to put a link to some FAQ into the topic of this room. That would cover constantly reappearing questions like this one.
LFReD_twitter
14:21"red lang docs" works, and "red docs" should be the official footwear of the org.
GiuseppeChillemi
14:22@Oldes I was referring to this "reactive site:red-lang.org". It's not the first thing that comes into people's minds but "reactive red lang" is and gave sufficient results.
14:24@hiiamboris I have made a search: 4 new users, including me, have written here about this problem. +1 for @LFReD_twitter *"red lang docs" works, and "red docs" should be the official footwear of the org.*
14:25I propose writing it on the documentation page of our main site and also on wiki and FAQs.
14:27On Duck Duck: "objects red lang" returned 4 results, while "objects red language" returend 7. The latter seems to return more results. So I propose " + RED LANGUAGE" as the best way to search RED documentation. Better ideas and experience are welcome, as usual.
14:36Just a personal note: I do not know the reasons behind RED name. I always thought it has come from Nenad's experience in national republic of China. I always imagine it as "RED dragon". I think it could have great appeal on developer of that nation. (hoping American people won't do the same and think about communism !)
15:11I am continuing on [chit-chat](https://gitter.im/red/chit-chat) with links about user perception and web site statistics
17:44I have updated the [FAQ](https://github.com/red/red/wiki/%5BDOC%5D-FAQ) (the last article). Feel free to improve its language and content, also please write on the main site about this solution as RED Language FAQ does not return any result even using this trick.
hiiamboris
18:08One should add the question about Mac Catalina to that ;)
21:17@rebolek thanks a lot, that will do! I was just surprised it wasn't part of the std lib :)
rebolek
21:18@speps higher order functions are not part of Red yet, the language is still in alpha and designing such feature takes some time.
speps
21:29@rebolek it makes sense, really enjoying Red so far, I'm trying to finish my Advent of Code 2017 to warm up for the 2019 one, it's going really well!
21:32@rebolek while you're about, is there any example of sort/compare using a function? there isn't one on red-by-example.org unfortunately, i'm also confused how it can take a block for the comparator
21:46awesome thanks, i guess i shouldn't be using red-by-example as documentation...
greggirwin
21:48red-by-example is a good resource, but docs are hard. help and source are your friends too.
BrianGilbert
04:01Is Red effectively dead on MacOS Catalina? due to 64bit requirement for all apps
djrondon
06:01Folks is there any problem with the Red VSC Extension? I'm receiving this error message: The Red Language Server server crashed 5 times in the last 3 minutes. The server will not be restarted. [Trace - 3:00:30 AM] Sending request 'initialize - (0)'. [Info - 3:00:31 AM] Connection to server got closed. Server will restart. [Trace - 3:00:31 AM] Sending request 'initialize - (0)'. [Info - 3:00:32 AM] Connection to server got closed. Server will restart. [Trace - 3:00:32 AM] Sending request 'initialize - (0)'. [Info - 3:00:33 AM] Connection to server got closed. Server will restart. [Trace - 3:00:33 AM] Sending request 'initialize - (0)'. [Info - 3:00:34 AM] Connection to server got closed. Server will restart. [Trace - 3:00:34 AM] Sending request 'initialize - (0)'. [Error - 3:00:35 AM] Connection to server got closed. Server will not be restarted.
19:38@BrianGilbert Not dead, but on hold. It should still be able to be run on Catalina in a Docker container or via other methods, but not directly.
speps
20:18hi all, is there a way to do an integer multiply without triggering an overflow error? i want a similar behavior as C for example where it wraps around
20:40either R/S or make your own multiplication func, using the idea that (a + b) * c = a * c + b * c until each individual part doesn't overflow :) (choosing b to be a power of 2)
speps
20:52thanks! i think that'll last resort for now, i'll try to avoid the hash to do what i need to do :)
stmungo
00:23I don't know if this is the correct room for this kind of question or suggestion but I will go ahead anyway. When the team is designing Red do they have a picture of the intended types of user in mind for language features? If so then does it include school children? If so then what age of pupil? The reason I ask is that one of my requirements for a programming language is SI and Imperial Units plus all the other units like avoirdupois out-of-the-box. To me, although not an expert, it is ironic that a language which describes itself as "strongly typed" yet does not provide units which are a kind of type and which would benefit from the checking of arguments of assignment and arithmetic operations. I think Red is a wonderful project which I have been waiting for for nearly 50 years. I am amazed at the technical complexities which you are facing and solving. I hope you will have the resources to provide units at some point in the future. Would positioning Red as a language for schools also be an application of Plank's Principle, mutatis mutandis programming for science? Or more succinctly catch them young! Best wishes.
greggirwin
00:51@stmungo, thanks for the question. Red is a descendant of Rebol, which inherits from Lisp, Forth, and Logo. Of course Logo is a Lisp, but mainly remembered for turtle graphics. Where Logo was targeted at school children, it was also given academic treatment as a powerful Lisp dialect (by Brian Harvey). You can think of Red as initially targeting high level devleopers, rather than school children, while also being a deep and powerful language that you can't outgrow intellectually.
If you are focused on units, look at Frink. We haven't decided how units will work in Red, but implementing a library to support them isn't hard and has, in fact, already been done. I just can't remember who did it, or where, so I hope they chime in.
"Strongly typed" doesn't mean "Every kind of type". :^) They deserve support in more languages, and we do want to do it. But we want to do it right, which takes time, and hasn't been a high priority.
We absolutely want to see Red applied to education, and are looking at how to approach it. One of the early things I did in Rebol was a simple Logo interpreter with turtle graphics, and I'm a big fan of the NetLogo model as well. Red's central feature of dialect creation makes it wonderfully suited to teaching, because you can easily create languages designed specifically for that purpose.
00:55This is the units work I was thinking of: https://gitlab.com/maxvel/red-units/tree/master
00:58One possible lexical form for quantity (magnitude/unit) is a path that starts with a number, rather than a word. e.g. 10/kg or 100/meters/second.
stmungo
01:20@greggirwin thanks for the link. That is some list. I was wondering if a list might be avoided to side step its attended maintenance. I use the <number><unit> for a lexical form myself as it is usually unused being deemed an invalid name in many programming languages.
01:37@greggirwin [sorry I pressed enter too soon] For example 3$/m2 + 5$/m2 = 8$/m2. does not need to know what $ nor m2 are. Nor does 5m2 * 3$/m2 = 15$. Nor 15$/5m2 = 3$/m2
Red []
context [
digit: charset "0123456789."
num: [some digit]
unit: ["$/m2" | #"$" | "m2"]
op: charset "+-*/="
code: clear []
ans: u1: u2: none
compute: func [u1 u2 /local u rj x][
if float? x: do head code [x: round/to x .01]
ans: form x
if u: any [u1 u2][
case [
all [find "+-" o u1 = u2][append ans u1]
all [find "*/" o any [none? u1 none? u2]][append ans u]
"$/m2" = rj: rejoin [u1 o u2] [append ans "$/m2"]
find ["m2*$/m2" "$/m2*m2"] rj [append ans "$"]
]
]
]
set 'answer function [str][
self/ans: none
clear code
parse str [
collect into code any [s:
copy n num keep (load n)
opt [not [space | op] copy u1 unit]
any space
copy o op keep (load o)
any space
copy n num keep (load n)
opt [copy u2 unit] e:
opt [if (3 = length? head code) (
compute u1 u2
clear head code
change/part s ans e
) :s
]
]
]
ans
]
]
15:19I'm totally new to Gitter, but I've set up a room at https://gitter.im/AtomicaDB/community
Will take this to chit-chat for now
16:49My goal with Atomica is to build out a 'smart' database using Red as the foundation. Smart as in a natural language interface between all db function and the user. AI driven automatic query generation and more.
loziniak
20:51Hi! A long time ago I submitted Red to Stackshare.io. I thought my submission has been lost or forgot in moderation, and today I've got an email that it's approved. So, everybody, share your stacks!!
https://stackshare.io/red
stmungo
22:15@greggirwin [For some reason the first 4 paragraphs of your 00:51 detailed answer to my question were not displayed last night] I did not realise that Red is initially targetting high level developers. I did notice the conversations in this room are often technical but also noticed the 2,500,000 odd page views so assumed a wide range of technical knowledge viewing. I wonder how many viewers are like myself who will use a small fraction of Red's features but then from time to time will want to do something much more complicated and be delighted to find it is built-in, or relatively easy to implement with the built-in features.
@loziniak cool. I know nothing about stackshare, so need to read up.
stmungo
22:57@toomasv Thank you for your demonstration of units and their arithmetic. I am impressed with your exercise but I must confess I do not understand fully what the code is doing but will use it gratefully as a learning material. @greggirwin I had a look at Frink which is wonderful but not part of Red. However my query about Red's intentions was prompted by a discussions of the base lexicon forms of Red (I think by BrianH) and by the release of a feature-packed date type and I suppose in a roundabout way was really wondering does the team see measurements units as a potential base type in the future but I think @greggirwin has answered this question.
I created a block with 1.5 million 7 byte random strings, eg: "ai40s9g", and wrote this to a txt doc. I then loaded this block into a fresh copy of Red, and ran this highly scientific timer script against the block
timeit: does[ st: now/time/precise foreach [sub pred val] db [if sub = "ai40s9g" [print "found it"]] en: now/time/precise print en - st ]
00:26I read the data in as triples, as I would with the Atomica DB. I happen to know that particular string I'm looking for index? 400,000 or so.
00:29The result on my computer (a fairly new i7 with 16gb ram on win 8):
Red: 0:00:00.224 Rebol 2: 0:00:00.063
00:31Although I haven't timed it, the load time of the 14.5 mb block was significantly slower than Rebol 2.
Thoughts?
Respectech
00:47You could probably make your time-it script just a tiny bit more efficient by combining the last two lines like this:
print now/time/precise - st
But that's just splitting hairs...
00:48It removes creation of an unnecessary variable.
toomasv
05:15@greggirwin Thanks! @stmungo You are welcome! Please feel free to ask if you are stuck, either here or PM me. I'll be happy to explain.
greggirwin
06:53@LFReD_twitter hold that test and try it again when the fast lexer code is merged.
11:17Will the optimizations completed in the fast lexer code have any impact on execution speed after the project is loaded? Or do the optimizations only impact load time for now?
pekr
11:24Unless there is some change in how internally decomposed code works (e.g. added a hashtable for symbol lookup), I think it is related only to the loading of the code. But I am not a low level expert, so just my guess ...
db: make block! 750000
num: 1
new-record: func [n] [
reduce [
rejoin ["user" n] reduce [
num
]
]
]
repeat n 750000 [append db new-record n num: num + 1]
db2: to-hash db
02:54time to build the hash in Red: about 12 seconds time to build the hash in Rebol 2 about 3 seconds
running timeit on my computer;
Red: 0:00:00.172 Rebol 2: 0:00:00.016
02:55The lexer code won't change this, correct? If this was compiled, would it run faster?
03:01In general, crawling blocks, picking etc, things seem about 3 time slower than Rebol 2. Is this a future optimization thing?
Oldes
10:08There is no optimization in Red yet.. as it does not use any C compiler with tens of development years behind.
10:11Not mentioning that your db populating code is written highly un-efficiently.
hiiamboris
14:31I downloaded red-20nov19-aa7c46ee.exe recently. But now the download page is stuck at red-17nov19-640c00ed.exe for some reason (should be 24nov...).
LFReD_twitter
16:34@Oldes Well, you'll need to discuss the code with Carl as it's his example. But yeah, once I trimmed his code down a bit, could have removed the reducing http://www.rebol.com/article/0020.html
greggirwin
18:17Carl didn't write that particular bit of code to be benchmarked. I write a lot of code that could be more efficient, but if it doesn't need to be, and you can write for clarity, do that.
Oldes
22:38@LFReD_twitter purpose of the article was to show difference between hash! and block! not to show how to efficiently fill the database used. Even Carl could miss some things... like allocating block with size 10000 when it must hold 20000 values. Not tha
LFReD_twitter
00:57I dont' suppose it was necessary to show the code I used to make the point that currently Red seems about 3 - 4 times slower than Rebol 2 in a number of areas, and more importantly why and will it be addressed in the future?
00:59I mean, a single block with 750,000 strings? Probably not the best way to go about storing data.
03:30I don't want to hammer the point, but consider the following;
I created a hashed block of 300,000 integers from 1 -> 300,000 and ran this loop 100000 [find/skip db3 [299998 299999] 3]
In Rebol 2, it took .016 seconds.
In Red, it timed out (not responding) so I lowered the loop to 100 loop 100 [find/skip db2 [299998 299999] 3]
In Red, this took .156 seconds.
Now, unless I'm missing something, that's like 10,000 times slower ?!?
greggirwin
04:42.156 / .016 ... just 10x. As @Oldes said, Rebol relies on optimized C compilers. We can address this, and even have a plan, but we're not going to optimize for microbenchmarks.
LFReD_twitter
05:01@greggirwin 10x, plus the Rebol looped 100,000 times vs Red looping 100
05:14might want to change the number of loops before running ;)
pekr
06:10I would not call 10x slower time of 100 Red iterations vs 100K R2 iterations being a - micro benchmark. As Gregg points out, might be a bug, those numbers look suspiciously ....
db: make map! 100000
repeat n 100000 [m: n - 1 * 3 db/(m + 1): reduce [m + 2 m + 3]]
db/299998
;== [299999 300000]
timeit: does [t1: now/precise loop 100000 [db/299998] difference now/precise t1]
timeit
;== 0:00:00.0159156
But this would have worked with hash! too, although twice slower:
db: make block! 300000
repeat n 300000 [append db n]
db2: to-hash db
find/tail db2 299998
;== make hash! [299999 300000]
timeit: does [t1: now/precise loop 100000 [find/tail db2 299998] difference now/precise t1]
timeit
;== 0:00:00.0368983
Oldes
09:46First of all, hash! should not be used for _ associative arrays_. There was no map! in Rebol2 (and no hash! in Rebol3). Hash! makes hashes for all values, while map! just for keys.
hiiamboris
09:49:point_up: [November 24, 2019 5:31 PM](https://gitter.im/red/red?at=5dda9453f3ea522f265d25e6) is nobody bothered by this? @x8x @dockimbel
Oldes
09:50Disadvantage of map! is, that it must provide check for unique keys, and so making a map! from large block is slower than making a hash!, which does not have this limit.
LFReD_twitter
11:23@toomasv I'm using the block as a collection of triples blk: [1 2 3 | 4 2 3 | 5 2 3... etc, but without the pipes.. each triple is unique. There's all sorts of ways of doing this.. objects, whatever, but it needs to be simple enough that a bot knows how to crawl it. In that example, sometimes I'm looking for all the first value of the triple by searching for the second and third.. there could be a number of these as in the blk example. Other times, I know the first and second value of the triple, and I'm looking for the third. In that case, there's only one result in the whole block. And then again, I may want the first and third value and only know the second. In short there's around 8 different basic functions to turn this into a CRUD, hence the line find/skip db2 [299998 299999] 3 I know these are the first and second values of a triple, and I want the third.
11:25I'm doing the same with strings.. blk{"one" "two" "three" "four" "two" "three"...]
Or in a real life example blk: ["hiiamboris" "is a" "person" "oldes" "is a" "person"...]
11:29This is why the 10,000 x slower is a bit of an issue for me, especially on large blks of data.
Oldes
11:39Sounds like you should be using some real database, or at least SQLite.
11:42It uses the same functions and a single table with 3 columns.
11:43So it's trivial to move the DB from Rebol to Python etc. Only the functions change.
11:43I'm going to source this in the near future as well.
11:45It's not ideal, as you're often running multiple O(n) passes, (although indexes help with that), however, drop the DB on a SSD and nobody cares.. well, 98% of db owners don't. AirBnB might have an issue with it ;)
11:51I built the University of BC's Go Global student exchange system with it.. and a ERM for a multi-million dollar electrical equipment rental company (erm -> to manage internal operations including manufacturing, finance, HR, sales and distribution, stock managment, shipping / receiving .. it's like SAP).. And dozens of others.. never came across a single issue as far as performance goes.
11:53Think I'll source the ERM too :), but would like to see this stuff ported to Red. (I've been a fan of Nenad for awhile.. especially back in the Cheyenne days, which I used on a number of these projects as well.
12:02But where I think this system will really shine is with smaller personal DBs. I mean, even SQLite is overkill for 85% of the dbs out there, where a flat file and a couple of blocks will do handsomely. In most cases a 1mb db is massive, especially when three rows of data = [1 2 3 4 2 3 5 2 3], then index those to ["nenad" "isa" "person" "oldes" "LFReD"]
12:45Just want to add, when I used a hashed block of 1.5M strings around 10 bytes each, and did the same loop 100000 [find/skip db2 ["user499999" "pred499999"] 3] Rebol came in at .015 but I had to drop the loop to 100 again, and.. loop 100 [find/skip db2 ["user499999" "pred499999"] 3]
Red: 17.234 seconds... yikes!
12:48I'm sure Red will get there, but check out that Rebol score.. searching for a pair of strings at the tail of a hash of 1.5 million strings, looping 100,000 times in .015 seconds! I don't think there's much out there that can beat that.
hiiamboris
12:57It's not "looping" though. It's looking up the hash.
pekr
12:58Have you tried to compile the Red code? Would like to see the numbers, if it is in the ballpark of 2-4 times estimate?
LFReD_twitter
12:59Yeah, I thought of that, but other things work fine un-compiled, this should too.
GiuseppeChillemi
14:04While I was making a mistake and found another "difference" between REBOL and RED. But I do not know the reason:
09:08Hmm I tried testing View on Linux - does it still not have gui capabilities this late in the game?
x8x
09:33> I downloaded red-20nov19-aa7c46ee.exe recently. But now the download page is stuck at red-17nov19-640c00ed.exe for some reason (should be 24nov...).
@hiiamboris Thank you for noticing! We have updated nightly builds file name, about command date and progress site to use commit date instead of author date. Should now be in line with github dates and sorting. Notice that git log displays commit's author date by default.
Oldes
10:31@XANOZOID you must use GTK branch as it is still work in progress. You may discuss it here: https://gitter.im/red/GTK
19:14@XANOZOID You can download latest Red from GTK branch here https://static.red-lang.org/dl/branch/GTK/linux/red-latest (reposted as link was incorrect)
henrikmk
19:52Wow, glad to see there is so much life here. Wish I could participate more.
21:26Welcome @henrikmk ! Nice to see old Rebolers here!
loziniak
22:04About :point_up: [stackshare](https://gitter.im/red/red?at=5dd84a68f3ea522f264d5e18) again. I've noticed a button there that says "claim this page", so perhaps Red team would be interested in making it official.
greggirwin
05:37I set up an account there, but don't see the Claim This Page button.
22:29@dander @greggirwin Tried to claim, it says this: [](https://files.gitter.im/red/red/AOpx/image.png)
03:03it wanted to verify my i.d. (not my id), as it noted my email doesn't end in red-lang and said it'd have to manually check me out. If I had a dollar for every time I heard that...
03:11As an aside, and all cynicism aside, in the US it's "Thanksgiving" and I'm grateful for this incredible community that pushes me to grow and learn. It's been raining for 24 hours straight in Los Angeles and if we aren't all swept into the LA River in the resulting deluge I am very happy to begin envisioning a new year of amazing growth with Red. I also look forward to continued cat memes from @9214 and the rest of you resident genii.
greggirwin
05:27:^) If you're a Gilbert & Sullivan fan, it would be resident Djinn I think (from The Sorcerer).
Respectech
20:44@lucindamichele Thanks very much for your Thanksgiving wishes. We also had a wonderful Thanksgiving yesterday with a house full of family and friends. I am looking forward to an exciting year with Red.
speps
10:55I know a lot of you might be on Thanksgiving break but the latest Windows binary is broken on AppVeyor and the previous successful builds don't have artefacts available.
10:56@hiiamboris seems like it's your commit that broke it https://github.com/red/red/commit/19853a8b3cc3ed3b75960d21693d45519e8f2f6a
10:57this line in particular: https://github.com/red/red/commit/19853a8b3cc3ed3b75960d21693d45519e8f2f6a#diff-0b158c179ee6c65379e68e5af9203b17R1861
05:42(forget the two dots.. how do you escape the Gitter markup?)
hiiamboris
10:36Please use https://gitter.im/red/bugs room for bugs discussion and when you're sure you've found a bug, post it our tracker: https://github.com/red/red/issues/new?template=bug_report.md
Oldes
11:58@LFReD I suppose you are trying to load hash! saved from Rebol into Red. But Red does not fully implemented the serialization format (the one using: #[...]). So far it supports only #[true],#[false] and #[none].
11:59Btw.. you can use mold/all to see what is the string result used by save/all.
12:07@LFReD and I'm not able to reproduce your loading issue...
>> db
== ["user1" "pred1" "val1" "user2" "pred2" "val2" "user3" "pred3" "val3" "user4" "pred4" "val4" "user5" "pred5" "val...
>> save %/a/db.txt db
>> length? db
== 75000
>> length? load %/a/db.txt
== 75000
06:45I don't do Go, so would have to read up on the struct/def format, but it seems like we could do a nice data-driven version of [this](https://www.reddit.com/r/golang/comments/e3tpmk/jsontogo_but_as_desktop_gui_app/) in Red for the Gophers. Their binary is 30M for Linux, and 45M for Windows. We could save them some bandwidth. :^)
LFReD
06:45Any chance of variable length arguments with Red func?
Select/skip can't select anything other than the the first column: value1, which is quite limiting.
I see useful removing this limit adding an additional /pos (or /offset) integer refinement to select so instead of the first value, any other could be selected! Without /skip the pos/offset refinement should return the nth value after the key.
>> third find/skip myblock [key2 value1] 4
== value2
greggirwin
10:02@GiuseppeChillemi select already has a lot of refinements, and what you want is easy to do at the mezzanine level. It also makes sense, in many cases, to use sub blocks.
hiiamboris
10:23With such a fixed table one shouldn't use select at all, as it'll be slow. Hash is the way to go ;)
GiuseppeChillemi
10:26@xqlab Thanks, I already use a solution like this. I suggested this improvement to Select because, using Gregg's term, "it makes sense". Having a block treated as a record with elements and you can only select the first one, is limiting.
10:50@greggirwin from your experience, in presence of a SKIP refinement, do you could think it could be possible to be considered as key an element different from the first one?
11:38@meijeru because the selection phrase using find would be long and also the intent is having a select not limited to the first column but capable of retrieveing the others composing the record.
11:40@meijeru it is really useful when you have external database tables stored in a block and you need to select an item:
11:42The first feature let you access any column, the second one let you use any column as key.
toomasv
12:49@GiuseppeChillemi Why not do it? Something like this:
13:28@toomasv 😁 because you do not have to learn another word and it's syntax and select will become a very powerful command? (promise I will not continue!)
toomasv
13:30IOW "Red should do everything I think it might do." You are going to rob programmers their job :imp:
GiuseppeChillemi
13:33@toomasv (hovever, thank you for your implementation)
13:36It's like Lego. If you have an idea, you put pieces together to realize it, not write a letter to Lego Company to do it.
GiuseppeChillemi
14:59@toomasv Yes but Legos once where sufficient to create some buildings, now you can create and drive full robots. That's because mother house has not stopped receiving and implementing suggestions and ideas.
15:57I see find too could receive the same improvement. You could find on different position than the first one of the /SKIP group.
16:09[this code searches by the 4th column](https://github.com/red/red/blob/c0b8ff4963333464a8feba4d8240098827f1c5af/environment/reactivity.red#L231)
greggirwin
16:10@GiuseppeChillemi select is not going to add this feature. It's design was reconsidered to match R3, not R2, and @toomasv showed the way to do this. What is one short line in Red, would be a large amount of Red/System code in multiple datatypes, because it's an action.
I appreciate that you have a different perspective, but when deeply experienced Reducers push back on your idea, you tend to push forward with the same request again. Do NOT write a request for these. Find/Select work this way by design.
16:11Well, you can write a request if you want, but it will be rejected. Save your time for other things. :^)
GiuseppeChillemi
16:51@greggirwin Greg, I don't know how deep is the change to implement this feature. I have thought about the speed and completeness of the selection/find mechanism but I can survive until resources and willingness be available. But please admit you liked this feature too in the first instance! @toomasv Please stop creating solutions to my ideas so quickly, you are ruining my requests! ;-)
17:08I was working on this Atomica stuff back in 2010, so trying to refresh my memory climbing over the Altme archives, and came across this historical conversation. It's @dockimbel , @gchiu and I discussing the pros and cons of cloning Rebol. Interesting read.
>> key: 1 b: [0 0 0 1 1 1 2 2 2] find/skip (skip b 2) key 3
== [1 2 2 2] -- search by 3rd column of b
GiuseppeChillemi
18:25So find is able to skip the searched series without interfering with its index. Good to know, great!
19:58@greggirwin >but when deeply experienced Reducers push back on your idea, you tend to push forward with the same request again
Greg, I didn't read this part. Why I ask a second time ? I see in my this vision the RED documentation chapter on Select with an example like mine and new developers all thinking: "great I can search in a blocks like I actually do in databases table, what a great language!". This because in the example you will show them intersects with what they are used to manage day after day. Do you know that showing to the potential adopters, in the very first moments, an operational framework similar to their usual one increases the adoption chance? I am a developer too and I remember when I have chosen something because of that something interacting with my needing. These are the reasons that would drive the request to reconsider that /pos refinement: its a MARKETING one other than a functional one. However, thanks to your reply came the idea of creating a page about using RED blocks as database tables in programming.red.
pekr
21:20I would like any such discussions to move into some other channel. It is imo too much related to one's own projects vs the proposal towards the general language developments ....
GiuseppeChillemi
21:28@pekr I don't agree. Select is one of the core instruction of Red. I have not asked for *help* for a solution (despite very welcome) but to have another refinement in select/find. Now the discussion is at its end, and the topic drifted and we need to move but until now we were talking about one of the Red core functions. Feel free to continue this discussion on https://gitter.im/red/chit-chat
endo64
09:57@GiuseppeChillemi Here is another solution with parse:
>> pos: none parse [1 2 a 3 4 b 5 6 c] [some [pos: 2 skip 'b (print ["Found record at index" index? pos] pos ) fail | 3 skip]] pos
Found record at 4
== [3 4 b 5 6 c]
11:15@endo64 :point_up_2: I have understood what this POS does
dockimbel
11:20@GiuseppeChillemi > Select is one of the core instruction of Red.
It is not a fundamental "instruction", it is just a convenient syntactic sugar for second find on series to cover the common bias towards key/value pairs. You can build your own specific select-nth variation trivially (pick find ... nth), there is no need to bloat the runtime environment with such construct.
11:39@dockimbel Nenad, we can do anything creating other functions, you are right. I think that having a full table search and retrieve methodology in the basic commands gives a sense of power when RED introduces itself to the developers, the so-called WOW factor!
11:40@dockimbel Also, I add my words to Petr ones: nice to see you !
endo64
21:25@GiuseppeChillemi pos in ...] pos) fail | 3 skip] part is unnecessary, a copy/paste error probably.
LFReD
00:09@GiuseppeChillemi If you're looking for some specific feature in Red, then just fork it!
GiuseppeChillemi
00:32The only fork I will activate will be on my pasta tomorrow.
09:20Moreover, print inserts spaces between each of the components of the block, so you don't need to put those in yourself.
09:21Admittedly, this operation is not adequately documented. It does figure, however, in the "specs" document https://github.com/meijeru/red.specs-public/blob/master/specs.adoc, that I am responsible for. See section 11.2.
stmungo
09:52Would someone tell me how to join the (Google) mailing list or where I would find instructions for same, please, When I click on the Red website mailing link the page says the group does not exist... Thanks.
ne1uno
10:07there does seem to be a problem accessing red-lang group by link or search
10:10mostly of historical interest. browsing gitter red/help probably has more information
10:12might be a glitch, other groups.google slow too
LFReD
17:39Every company needs a goal, a one-liner, and that goal should be displayed above the white board of the board room. Every decision, product, direction etc should be to kick the ball towards the goal. Most of the staff I've worked with think the goal is to 'make money', which always the wrong goal.
So, what's Red's goal?
18:04Is it "To create the world's greatest programming language? "
18:08If that's the goal, then where's the current choke point in reaching that goal? Where's the blockage? What's stopping you from reaching that goal right now?
18:14This is from the about page on the website "Red’s ambitious goal is to build the world’s first full-stack language"
GaryMiller
18:19I think the answer to blockage is always money, time, and talent Most all open source development visionaries would love to have enough play money to hire their best contributors to work full time and accelerate the project development life cycle.
18:21I think this product is the closest as I've found to to a full-stack development environment although they support multiple languages under the cover and are expensive. And seem to be not that popular yet in the US. https://www.windev.com/index.html?p=google016WINDEV&gclid=CjwKCAiA8qLvBRAbEiwAE_ZzPcNis4EuqIrD9jsbwllmT1KVvJRcjuewIwW1tVwBvXOe2IvR088sZhoC3s4QAvD_BwE
LFReD
18:23McDonalds had a goal "To deliver delicious pizza to the masses as quick as possible" .. each restaurant spent $50,000 US to buy specialized pizza ovens, ..that was $700M just in ovens alone.. throw in a $200M marketing campaign, renos because the pizza boxes couldn't fit through the drive-thru windows...
18:25If the goal of Red is to 'build the world's first full-stack language', then you're right.
18:36Unless the goal of Red is "develop the world's first full-stack language over the course of 15+ years", you're going to need money.. BIG money.
Personally, I don't think any of these are the real goal.
GiuseppeChillemi
18:40I can hear Vladimir asking to move to [chit-chat](https://gitter.im/red/chit-chat)
23:48:point_up: [December 5, 2019 11:19 AM](https://gitter.im/red/red?at=5de94a3b5506624598736a3f) @GaryMiller, WinDev is one of those old tools that has survived. The modern low-code/no-code tools were the RAD tools of the 90s, and the CASE tools of the 80s if they were around then. We've talked about that market, but a) there are deeply entrenched players there, with their following already locked in, and b) the seem to live off that, and aren't attracting new users in droves. Happy to be wrong about that, if somebody can find the data. Competing there is tough, because they have all the legacy integration bits in place, which is a huge effort; and if we look forward rather than backward, the future will be cloud and SaaS for some time now, until the next disruption.
LFReD
00:47>the future will be cloud and SaaS for some time now, until the next disruption.
@greggirwin How does Red fit into that vision? Cheyenne 2?
greggirwin
02:10Having an old-school web server will be great, and Cheyenne will likely be ported to Red, but it's another generic language feature/library that nobody will pay for. So it falls into the FOSS side of the Red equation. Cloud and service offerings, built with Red, are viable, commercial product areas. We're doing market research for a number of things, with developer oriented tools leading the pack, and consumer oriented products coming after.
TheHowdy_gitlab
05:32Btw: thanks for the rate of new posting on the blog. Keep it up. That way we know you guys aren't dead yet ;)
pekr
05:32@greggirwin you imo really need to get Red into the browser and on the mobile platforms, you don't need any hard numbers for that imo. It is enough to watch the status quo. I know 2 of dev groups in our area, which switched to Flutter last year. I can hardly find any app, which uses native client in terms of a corporate environment, apart from SAP client and even that can be switched to web form. Dunno what is the right way, if it is some kind of VID4web translation, or running the whole app in some WebAssembly container, but it is indeed a big handicap. Strange thing is, that on the mobile, native apps are preferred, but on the desktop, not so ...
viayuve
06:03@greggirwin we are currently paying oracle for database, syncfusion for UI Component and report. If red can produce UI component and report like that my company will happily buy it. I do understand putting app online and service market but still big chunk of market share prefer "in house" custom made software over generic because they like control and sense of data safety.
08:13We prefer in house and independence too. Actually we are facing extortive tactics from our ERP seller which has remotely blocked our software to get money from us. This is happening with in house installed software and we are on emergency! We are accessing the data pipe directly on database table level. I don't want to imagine if the whole company was on cloud. The seller could have cut access to our data at any level and we would have already paid the extortion fee. I an not against clouds but companies needs to know that cloudware con turn to ramsomware nightmare instantly.
vazub
10:22Hey guys, has anyone here tried doing any kind of data analysis in Red and can share any insights/experiences? I am aware, that at this stage of development, it would be unfair to compare Red's facilities to R or Python/Pandas, but I have a feeling that Red should be an interesting option to try, even without dedicated dataframe type and supporting library (unless I am missing something and there already is something of sorts).
Senenmut
11:35"unfair to compare Red" the only "unfair" thing is microsoft NET framework facilities make programming for other languages difficult to handle on windows. What do you mean unfair ? R/Python and other have no GUI inside and you must learn a different GUI language. That's "unfair". Also networking facilities too. They must use libraries. (curl shit etc.) Of course Red is interesting to try. There is no easier way to program for windows in the "REBOL" style when the language is ready. A dataframe you can create yourself. An individual style. Even better. Libraries will come automatic with for example "networking". The question is what amount of work to do for a complete application. To make this easier is VERY HEAVY to reach in this times. You know it if you see your mentioned language libraries.
I mean the amount of man/hour effort put into those facilities already and their level of production readiness, comparing to Red, which has not yet matured to v1.0
Senenmut
13:07this comes from the damn "cross platform" mania. every language is running in that way. if you concentrate on one platform things come to the point. but it seems nobody is doing that.
TheHowdy_gitlab
13:09When they "get to the point", developers will try to port languages
13:10to other (maybe not suitable) environments. See js.
15:52Has anybody ever tried to write a transpiler for Red that would convert a high level language such as Python to Red code? While such a project may be intense it could open up a lot of public domain software converted to Red. There are other projects that try to transpile Python to C but Python is so dynamic that such project usually need to embed an interpreter for the most dynamic sections of code. While the transpiled code could run slower or faster once transpiled it would produce a true executable which is much easier to distribute. If the transpiled code ran faster it could also be another niche market for companies who wrote code in Python but now need more speed without going through an expensive rewrite.
Senenmut
16:38there is only one project. write a application on a platform with minimum GUI and networking plus application special design patterns. my choice is windows for red. red does not need other language approches. it's smart itself. @TheHowdy_gitlab yeah that's the reason for long time development. i make absolute nothing cross compile , only native. problems arise with cross compiling OR it takes a very long time. for myself i dont care what others do or "say" they will do. the most "sayers" do nothing. it's the same story " only make one application really good and smart on one platform include up to date technologies". the simplest really good tool is HEAVY to produce. that is why i take an eye on RED because at this point of development with the actual possibilities faster development is real. it is true that it takes a longer time to go multiplatform before everything is complete on one platform. the difference is that Red has REBOL transformation as vision , that was complete on one platform.
@pekr, Android is on our roadmap, running in the browser is not. We need to be a lot more specific than "get Red into the browser." A key question is how we make money on those platforms. On Android, you really have Android Studio as the main competitor, and a few other key players. On the web, there are *thousands* of dev tools vying for your attention, and many of Red's benefits evaporate in the browser context. What is Red's advantage in the browser, over JS, TS, Elm, Elixir, etc.? If you (anyone) want Red in the browser, we need to be convinced.
lucindamichele
19:48Hi guys! I'm poking my head up from my annual holiday head cold to let you all know we have a new post up on our blog: https://www.red-lang.org/. We have some big thank-yous to members of the core team and are looking forward to new developments in the next couple months. Now is a good time to survey accomplishments from this past year and lay intelligent, scope-bounded plans for the new year. @dockimbel , @qtxie, @greggirwin , @bitbegin , @hiiamboris , @9214 (congrats on relocating, I am doing the same this week, but not nearly as far), @rebolek , @warp , @endo64 , @ameridroid , @toomasv , and @BeardPower plus so many more, thank you ALL for everything you do and for your inspired patience. :) It is so appreciated.
greggirwin
19:49@viayuve correct me if I'm wrong, but syncfusion is a broad and deep tool, with a long history. It's unlikely we can match them feature for feature. This is where specific needs and examples help. What do people really build, and what do they need to do that? Certainly reports play a big role in the format discussion, as businesses still need reports. Though dynamic reports (dashboards) are equally important now.
19:55@vazub, "data analysis" is a very broad term, and not much has been done in Red there. However, Red is a *great* fit for it, especially if you can leverage its rich set of datatypes. When we did the CSV codec, there was a lot of discussion about the various output formats it could support, and whether it was too flexible (and larger because of it), or if that could play well into the various data models (e.g. rows v columns v records).
What is most needed, and maybe you can help here, is expertise. We need input from data scientists, analysts, and those who do this all day, every day, to identify the pain points and priorities.
Senenmut
20:12red in browser ? why can run it on a gemini pda real linux with real keyboard.
pekr
20:18In corporation, browser is often the only accepted environment - you don't need to install nor distribute just anything. As nowaday's websites can act as regular apps, the browser advantage is even bigger. It's there with your OS anyway, waiting for the next URL to display. It is not about html and all that messy stuff, but about browser as a distribution platform. So for a fraction of time I thought, that the situation could be solved by WebAssembly, allowing almost-native-apps to run in terms of the browser container.
Respectech
20:18Agreed. The browser is the universal platform at present. Our infrastructure software is written mostly in Rebol3 and runs in browsers in our internal operations so our employees can work in a paperless environment as they can use tablets, phones, laptops, etc.
greggirwin
20:44We understand this, really we do. But you're not answering the question of how it helps Red become sustainable, or what Red's advantage in the browser is. We have to pick our battles. Native mobile apps are a win, yes? We can do that on Android.
The number of web desktop apps is still very small, e.g. [this list](https://electronjs.org/apps), but if the browser is the only way to go, why do big companies like Slack offer a desktop version?
Finally, and this is important too. We want to improve software development for people, and fight software complexity, with Red. Can we do that in the browser? Does it align with our mission and our values? Do *we* believe it's the best approach? Because if we don't believe it, the only reason to do it is for the money, right? So, again, show me the (path to the) money.
dander
20:58WebAssembly is interesting because it's a byte-code runtime that has been created for the browser environment, as opposed to Java and .NET which originated on the desktop and tried, but failed to migrate to the browser. Moreover, it's light-weight and not controlled by any one tech company. It wouldn't be much of a stretch to see it migrate to the desktop, similar to how Node.js did. Perhaps finally fulfilling the compile-once-run-anywhere goal. One missing piece for that is a cross-platform UI, but since Red is already natively cross-platform, I don't know what Red would gain going in that direction. It's still interesting to think about. Microservice stuff seems like an appealing space to me where image deployment size seems to matter much more compared with desktop or on-prem services. Especially considering ease of development compared with other light-weight environments. Red will certainly get there on the current trajectory.
GiuseppeChillemi
21:06@greggirwin The answer is difficult and simple at the same time. I always think that a mixed approach is winning. Red as foundation should receive donations and also run side projects being paid from companies to develop and customize them.
21:14Also, it is really important to set your yearly economic needings. This will help drive many choices.
Respectech
21:38@greggirwin As the browser has become a platform in itself, it lends itself to the full-stack concept. Web developers have their own full stack and I've seen listings from job postings stating they are looking for a full-stack web developer.
ne1uno
21:41forced tab caching till it gets focus. crash once a week, daily update delays. I rest my case
The only benefit I could see with Red in the browser would be for DSL usage. for say CSS Grid Layout
21:59> @greggirwin So, again, show me the (path to the) money.
Red/Atomica/$$$
The triplestore and CRUD functions are the community version of Atomica :)
22:37Hey, I could never understand why tuples in Rebol were limited to integers, and why has Red adopted the same?
greggirwin
01:34Tuple design has to do with their primary use cases (colors and IP addresses) and efficient implementation, though you can do more with them of course.
01:43@Respectech, web full stack is completely different from Red full stack. We go vertical, down to the hardware, and they go horizontal UI->middleware->DB.
Respectech
01:51@greggirwin But I want all the full-stacks for all the things...
I do understand how Fullstack needs to pursue those projects that will aid in success, and I'll drop this now.
If I had time to understand how Red maps to bytecode and how to map that bytecode to wasm targets, I'd be tempted to try it myself.
pekr
06:43@dander If you are speaking about WebAssembly here: "One missing piece for that is a cross-platform UI, but since Red is already natively cross-platform, I don't know what Red would gain going in that direction.", then I think it is not about Red gaining anything. It is about browser being a distribution, no-install platform. I have not seen much stuff being done in WebAssembly, so who knows what its future is. But tell me - how do I distribute my Red app to the 400 employees? I have to create a package and do some Active Directory policies, etc. Or I would have to have something like IOS desktop, self-upgradeable and able to deliver apps.
06:48@greggirwin is right in many aspects tho, and especially one is interesting - I can see a reneissance of desktop apps. But a bit different ones it seems. Did not used Slack apart from browser, but we are fully O365 on backend, and we use e.g. MS Teams. It has a dedicated desktop app too. And of course mobile counterparts. But those apps behave a bit differently from the old-school fat native apps - they are quite small, user can install / update them without an admin - they mostly self update. It almost feel, like companies willing going out of the browser, but without the hassle of complicated install process. Dunno if those are typical Win32 apps, or some MS "modern" stuff. E.g. new Lightroom (not a Classic version) feels similar.
06:52So maybe, in the end, the problem is not with the Desktop apps per se, but with how cumbersome it was for admins to get new versions to the end users in a larger scale. Mobile apps also showed us one other thing - you don't update your app on the months basis, but often on the week or even day basis. So you really need to solve the distribution infrastructure. I e.g. remember Gabriele created some Rebol self-update mechanism in the past. But on the other hand and also - look at those modern apps (google MS Teams) - they look trendy, not sure those are using native widgets? Maybe they are, I just don't know.
dander
07:45@pekr I think you make a good point about distribution. It seems like self-updating should eventually become a standard feature of most serious apps. I was mainly referring to the idea of web assembly coming out of the browser, with things like https://wasmer.io/ . When I learned about that, I got the impression I was seeing something that could become huge, and I can sort of see how Red could contribute to it, but I'm not sure whether it would help Red grow. For inside the browser, I think Red could be great there too. The thing that makes me nervous about targeting that is how quickly tech seems to turn over in that ecosystem. I'm pretty sure Teams is another Electron app.
GiuseppeChillemi
12:14I don't think it would be so difficult to implement an update server. I see it as a simple server which listen to a port for updates request with ["device-id" "password" "software-id" "current-varsion"]. Any software we create should be configured to poll the update server address and port and if a new version for a specified "software-id" is available it should be downloaded, saved and the application restarted. Now so difficult to create. Its just 4 or 5 days of work including debugging.
12:15Having ports available I could create a prototype in a couple of hours, even less.
pekr
12:45You imo absolutly don't need an update server and direct port communication. Simple URL based download should be enough. It is imo more about the strategy of how to update app components or the executable itself. Remember - OS might keep it locked, while you run it. So you would have to develop some strategy of how to swap processes or something similar. Also - some of the updates might want to change DB structures locally etc., so you need to update on version to version basis, etc. It needs to be well thought out. I do remember Gabriele developed something like that in the past.
software-structure: [software-id version file-path]
software: [
"order-entry" 1.47 %soft/entry147.exe
"inventory" 2.00 %soft/inv200.exe
]
request-structure: [device-id software-id current-version update-request]
forever [
if update-request: read port [
foreach [device-id software-id current-version update-request] update-request [
if (software-id = software/(index? find software-structure 'software-id)) and (curren-version < software/(index? find software-structure 'version) [insert port read/binary software/(index? find software-structure 'file-path)]
]
]
]
13:38About financing Red foundation. I am developing a couple of projects in Red and one will be out when the Android version will be complete. I am available to share revenues with the foundation and also give to other persons/companies the software for sale. I would give a percentage of revenues to the foundation in this case too and the resellers should do the same with their revenues. If a sufficient number of companies/developers will sustain this model we all could have a constant flow of funds.
13:46The mutual help is winning in many ways: everyone could have software from other companies available for sale; having multiple software for sale strengthens the force of the sellers which could propose solutions in multiple areas; the constant flow of money will sustain everyone and the foundation too.
lucindamichele
15:30> It's like Lego. If you have an idea, you put pieces together to realize it, not write a letter to Lego Company to do it.
I love this.
GiuseppeChillemi
17:10@lucindamichele We have our Lego blocks too: we call it blocks and datatypes. Lego started with some basic blocks and then evolved creating others. [History of Lego](https://www.thoughtco.com/lego-toy-bricks-first-introduced-1779349)
17:12Who knows if Lego started creating other types when some consumers called for them. However, history proved it has been a winning choice.
18:19However, my conscience asks me to write an addendum to my last message: not everything needs a multiplication of types or revolutionizing the workings of things. Sometimes it is dangerous not introducing elements of change, sometimes those elements could be disrupting. Discussion and analysis of the ideas under different lights and aptitude is important.
greggirwin
23:13@pekr is spot on about updating systems. They are far from trivial. And we can help users to build them by baking in features that account for it. For example, most apps need some kind of config system, and even most simple apps benefit from CLI support. Those both come into play in an update system. We don't know yet how far we can go at the generic Red level, but there will almost certainly be more than one approach taken to this. At a very high level, where there's an app framework in place, simple cases can be handled declaratively and quite automatically. Complex cases, where more than a single EXE is involved, requires much deeper thinking about "Redaptive" systems. :^)
TheHowdy_gitlab
14:29Q: Custom user data types (with lexical forms) are probably not going to be implemented as stated in the blog, but what about new lexical forms for existing data types? Like, modifying the lexer to recognise
but it's difficult to use and not that scalable for the use case. (e. G. What if someone wants to combine these lexical forms with another lexer "extension"?) So
pre-load
is not enough imho.
14:33(Because it can be set to only a single function)
GiuseppeChillemi
14:57Today I have started asking myself how multiple lexer extension could coexists. I suppose you should be able to create a sequence of isolated extension and run the sequence.
TheHowdy_gitlab
17:11One could also just use the system provided by macros; imagine a normal Red macro, but operating on string level instead of block level.
17:12Just speculating, of course. Certainly has a deeper impact on the language than I can think of right now.
greggirwin
19:38Quantity! (a.k.a. unit!) is a possible type, and path! syntax starting with a number rather than a word is a *possible* approach, but it gets tricky as soon as you go past non-literal quantities. e.g. 44m or 44/m seems fine, but what about n: 44 n/m? What about n: 44 u: 'm n/:u? Then consider meters/second, which you want to treat atomically as a unit spec.
The casual language that has the most thought behind units is Frink. The serious language in this space is Wolfram. What you'll see there is what we could do today with a dialect, or string-based DSL. An earlier experiment on that was linked to not long ago.
I will say again, as soon as you create custom syntax, you are incompatible with everyone else. Your choice. It should be an absolute last resort, if then.
TheHowdy_gitlab
21:16You probably got me wrong, so I'll elaborate further: I took this unit stuff as an example and I don't care about new types in the core language. There are already enough types for most use cases anyway. But one cannot cover all of them.
21:21Essentially, I'm asking for string-level macros. We already have block level macros, which do not cause any incompatibilities, because they are in the core language, right?
21:23Again, I'm not asking for new data types, I'm asking for user-defined lexical forms for existing types.
21:25And I know its possible in a string-based dialect, but then one cannot use all functions which operate on blocks. No head, tail, take, etc.
greggirwin
01:47It's the string based forms that create the incompatibilities, but you can do what you want today. system/lexer/preload makes it easy.
TheHowdy_gitlab
06:31I'm sorry if this has been answered before, but may I ask why? Why can't normal macros create incompatibilities?
viayuve
06:46@greggirwin I am estimating here but like 80 % of our company uses desktop native software, for mobile/tab we do have native app for that too. From syncfusion "Desktop" we use controls of winforms and wpf (we need datagridview like or table with excel like filters from red ;) big part, like every single one of our form have one). From "File Formats" all but largely pdf and excel. For reports we have sap crystal reports and Bold BI + Bold reports (Reports also big part) Dynamic or pre-configured some are Auto generated based on time frame like weekly and monthly . Asked my dev to get those information.
07:03@greggirwin me: How much of our data are in cloud. Dev: some api for otp and few things here and there less than one percent may be. I do know some company run entirely on cloud but not everyone. Concept of renting vs owning bothers many Boss. Dependency not a good thing you know it, some fine all not good at all. @GiuseppeChillemi I understand your position completely. Had that incidence in small data transferring software. My company hired 6 devs and made our own.
GiuseppeChillemi
08:00@viayuve that's one of the reasons I want to adopt only open source solutions. You have always a way to go out of problems.
08:06I have gone public to ask if it has appened to other companies and I have received horror stories. One business has been been forved to pay alweady paid fees and they blocked the ERP to force them. On machinery have been found time bombs to signal fake errors and force to call the mother house for unneeded repairs and many more. Software you have no power on it is the devil.
greggirwin
02:05:point_up: [December 8, 2019 11:31 PM](https://gitter.im/red/red?at=5dedea478e906a1c8d96b941) @TheHowdy_gitlab block based macros can create semantic incompatibilities, to be sure, but string based macros, and non-standard lexical forms create *data* incompatibilities, which is much worse.
lucindamichele
04:16Red is seeking technical graphic designers. If you know someone who can design technical images, flowcharts, illustrate processes and decision trees, create gifs and other simple animations and work with a global team of iterative developers, have them send links to samples (please no image attachments) and a resume to lucinda @ red-lang dot org. Thank you!
09:15@LFReD, the important thing is not how Red performs in microbenchmarks, but whether it's fast enough to be useful.
You have a way you want to do things, and that's fine, but you're fighting the language from what I've seen, and don't want to change that. Our job is not to fix your code, or help you fight the language. There is no magic here, just hard work and understanding.
pekr
09:17@greggirwin I don't consider something being 10K slower being a micro-benchmark related.
greggirwin
09:20Looping on a single function, or small set of them, is a microbenchmark. I don't remember what the 10K slower code was.
pekr
09:23My reaction is mostly related to possible bugs. I know that Red might be generally slower and that R/S is somehow slower than native C apps. I would be OK, if such "worries" of usability problems in certain cases are collected and explained. If we know the reasoning, user might choose different design ....
09:24Not to mention that future JIT might change things again ...
greggirwin
09:24This example lack context to tell us that Red is slow for a given purpose. Nor does it narrow down where the time goes, so the question could be "Why is rejoin slower?" or "Why is to-word slower?" Some optimizations are obvious to experienced Reducers, but do they matter? We don't know.
09:32[This gist](https://gist.github.com/greggirwin/908d44dc069ed84cf69f053e1308390d) is easy to use, so you can cut things apart and test them, bit by bit. Anyone using Red can learn a lot by doing that.
PeterWAWood
09:49@greggirwin You must be clairvoyant - "Why is to-word slower?"
Red
>> do [
[ st: now/precise
[ loop 10000 [ to word! "a" ]
[ et: now/precise
[ difference et st
[ ]
== 0:00:00.298862
Rebol 2
>> do [
[ st: now/precise
[ loop 10000 [ to word! "a" ]
[ et: now/precise
[ difference et st
[ ]
== 0:00:00.001433
09:51@rebolek You too :-) > I’m not sure if making word from string repeatedly is the right thing to do.
LFReD
09:52I have strings and in this example, I'm checking paths. So unless there's some way to do blk/"bob"
09:59The point i was trying to make is everything is slower in Red in this area. My particular use is CRUD functions against large blocks of triples, and no, it's not 'fast enough to be useful' in my case.
10:00What I don't understand is how this seems to be a non-issue at this point in Red's development?
10:04Let's put it to the real test.. Create a block or hash!, whatever, of say 100,000 random values, and at the end put "hello word" or hello-world.. whatever, and then use whatever method you want to find that last value of the block.
dander
10:08@LFReD an issue #4177 was opened for that just 5 days ago (and thanks for reporting it) but I think it's not unreasonable that the team hasn't gotten to fixing that yet, and it doesn't really seem necessary to belabor the point
10:31It might be a bug, or possibly missing optimizations that could come at some point. Either way it takes a lot of technical skill to investigate, so a smaller number of people can address them, and it's hard to determine at what point performance issues like that become high priority. It can be helpful to do investigations like that where you gather data and profile things under different conditions to make it easier to understand where the bottlenecks are. It might be more appropriate in the bugs room though
magicmouse
10:35I find that many of the people who criticize new langauges because of some speed difference from C ignore the point that C is an incredibly unproductive language. Fraught with peril; array buffer overflows, NIL pointer exceptions, hidden conversion errors. Look at the big C programs the world is stuck with: OSX, MS WIndows, they are all full of bugs that never seem to get fixed. We need better, more reliable languages, speed is of minor importance today. More than 95% of all computers are idle at any point in time. I can see it at the data center when i visit. Vast banks of computers idling away. Reliability, ease of learning and use are critical because there are 100 million new computer programmers coming on board i the next few years, and they sure as heck are not going to be using C and stare at the screen trying to figure out "why doesn't it work". Debugging consumes 85% of all programmer time by my long-term measurements. Ignore these speed freaks. The real battle is with the new programmers who are looking for a much simpler system.
meijeru
10:56@LFReD You want to do blok/"bob"-- it turns out you can do blk/("bob")
10:56Eventually, people writing small programs decide they need to scale. And when they don't they have to throw away their work and move to another language. Many startup companies who wrote systems in Php or Ruby which were fast enough when they were small spent small fortunes re-writing their code when they grew and started losing money because their systems could not scale. Just one or two horror stories like that can drive new users, paying users (the best kind) to the competition.
11:0815 years ago when computers were doubling in speed every two years companies would take the risk that the speed of new servers would match their growth curve but now that computers are only increasing in speed at 10% a year if we're lucky, most companies can't afford to take that risk anymore.
11:29@GaryMiller Well, those languages aren't just sitting around either. PHP is now faster than Python (which isn't saying that much, but still)
I just read the latest Mac Pro has 1.5 terabytes of ram and a 28-Core, 2.5GHz Intel Xeon
meijeru
11:33@LFred You could have read this [here](https://github.com/meijeru/red.specs-public/blob/master/specs.adoc#56-components-of-values). That work (mainly by me) contains a lot of information about syntax and semantics of Red.
11:48That new Mac Pro is aimed at a high-end graphics workstation for Hollywood animators. A large in-memory database would seem to perform well also on it for AI. But the software has to either have enough user sessions or threads running to utilize the 28 cores. Most applications today are still written single-threaded and it is the single-threaded benchmarks that fail to increase much from year to year now. The trend now in software development is to decompose the applications into lightweight MicroServices that communicate which each other either inside the machine or across a high-speed network to other servers for scalability. Most languages do not have this capability in their standard library and various frameworks spring up to try to fill the gap, but that leads to multiple ways of doing the same thing and fragmentation.
meijeru
11:53@LFReD Shows you the wealth of Red facilities -- and graphics and parse as well as some other features are not even covered, beacuse well-covered elsewhere.
pekr
13:11@meijeru excellent document. Is there a plan for it to become official part of Red documentation, or at least being linked to from a Red website?
meijeru
15:27It is maintained by me until it will be -- in some modified form -- incorporated in the "official" Red documentaion. It is linked from the Red Wiki under Reference.
loziniak
16:13We hear from time to time about plans of rewriting much of Red sources at the point of creating JIT compiler, or 64-bit support, or bootstrapped compiler. Probably that's why it's not being optimized – much of the code is said to be temporary and planned to be rewritten.
16:14@LFReD you make good work in spotting places, where optimizations are most needed.
LFReD
18:47>Red's notion of a "Full-Stack Language". It's about the ability to bend and redefine the system to meet any need, while still working with literate code, and getting *top-flight performance*.
GiuseppeChillemi
19:07@loziniak We actually need completing the basic features more than optimizing the existing one. Then small optimizations are welcome until a complete rewrite or Red 2.0.
19:08You first need to have a car before having a fast car.
19:49@LFReD Musk sold his products in alpha and beta versions and without full testing. The is no need to be very complete to feel complete. So we do not need full optimization to feel a language ready to be used and be positive about it. The windows problem will be fixed in its cybertruck as the performance issues will be in Red.
GaryMiller
20:08Nobody would have bought the first Tesla if it only went 35 MPH!
dander
20:19A top speed of 35 MPH would not even be street legal. A more reasonable comparison might be battery charging time. Really important to some users some of the time (people who do long road trips?) but for most users, so long as it can get to a full charge overnight, they are fine. The important part is knowing what sort of use cases are impacted by the constraints.
LFReD
20:28>"In corporate religions as in others, the heretic must be cast out not because of the probability that he is wrong but because of the possibility that he is right."
20:30A quote from Dijkstra's famous essay on why arrays should start with 0
GaryMiller
20:33My old boss had a variation of that quote when he was about to squash somebody. "The nail that sticks up must be pounded down!"
GiuseppeChillemi
20:44We are at the end of the journey. Be positive and look at all the good things we have. This will help to keep the spirit high and creates the grounds to for the success.
LFReD
20:51Good news! append blk "a" is 1.2x faster with Red over Rebol (and really fast in general)
pekr
20:59The boss using quotes to squash someone, should not be boss in the first place ...
LFReD
21:36Writing to file is faster in Red as well, by 1.04 over Rebol.
I've ran like 10 of these now, and in general, Red is 4x slower, which we knew, and yeah, who needs to do a:1 100,000 times in a row. It's not a deal breaker.
These two are weird;
a: 1 - 5x slower in Red a: 1 + 1 - 2.4x slower in Red
21:46I've noticed slightly better execution speeds when compiling my Red AI app. I've not done any benchmarks but it definitely feels a bit faster. I'm looping through around 16,000 Levenshtein comparison of sentence lengthed text strings to a user entered input. I don't usually compile though because the whole compile link process with -r takes over 10 minutes.
hiiamboris
21:53Perhaps we should implement some common string distance algorithms as routines? I have a use for that too
greggirwin
22:49@PeterWAWood not clairvoyant, I just put a bunch of blocks in profile. :^)
23:03Edited this Wikipedia page: https://en.wikipedia.org/wiki/Comparison_of_programming_languages_(array)
The Redbol languages really stand out. (if you see any errors, let me know)
greggirwin
23:05:point_up: [December 12, 2019 3:04 AM](https://gitter.im/red/red?at=5df210a92bca3016aa67ad01) The reason it's a non-issue @LFReD is because Red isn't magic. Brute force will go a long way, but it has its limits.
LFReD
23:05@greggirwin If I knew it was going was going to be referred to, I would have renamed dafunk :)
23:08With the memory, is that in bytes? And what's with the negative values?
greggirwin
23:15Memory is simply a stats call and diff, so can vary depending on GC, etc.
Thanks for the wikipedia update. copy/part is tricky, because it's richer in Red than other langs. I also don't know if 1..10 range syntax in some langs can use vars (m..n) or alternate syntax for that.
LFReD
23:16Like I said, it's not a deal breaker, with one or two exceptions, there's workarounds as well. By going through the conversation, I've found an alternative that's suits my desired purpose even better.
But that was never the point. *I expected Red to be 4x faster than Rebol, not the other way around.* And hopefully one day it will be. But I don't think, *ah, good enough* is a good response.
greggirwin
23:18I don't know why you expected that but, again, it's not magic. It gives you easy options for blazing speed in some cases. e.g. your math example could be done in R/S. If you're doing math, and need it fast, you win big time there.
LFReD
23:18Yep, I get it. Same with compiling I would imagine.
greggirwin
23:20Compiling will speed some things up, but you're still working in a very high level language. And you should, 99% of the time.
GaryMiller
03:00@hiamboris That would be wonderful! As you see in RosettaCode quite a few of the higher-level languages have edit distance (Levenshtein) built-in functions that run at compiled speeds.
hiiamboris
10:44@GaryMiller There's also a problem of choice ;) I love the graph in the beginning of [this article](https://www.joyofdata.de/blog/comparison-of-string-distance-algorithms/)
GaryMiller
11:17@hiiamboris Levenshtein still seems to be the most accurate (although slowest) for Bot applications, but I haven't found a code implementation of what the author suggested in this paragraph. "What string distance to use depends on the situation. If we want to compensate for typos then the variations of the Levenshtein distances are of good use, because those are taking into account the three or four usual types of typos. The metric could be improved f.x. by factoring the keyboard layout into the calculation. On an English keyboard the distance between “test” and “rest” would then be smaller than the difference between “test” and “best” for obvious reasons."
11:21Also any Levenshtein function should include a third parameter to return early if the distance calculation reaches the value of the last integer parameter. Call that MaxDistance. The reason this optimization is important is say we are searching a million strings and we find a string that is only 1 less than than the length of what we are comparing to. Any other string that we examine we can return early once we hit a distance of 2 because the one we found earlier with a distance of 1 we already know is a better match. This is a very good speed optimization.
11:23Levenshtein can also run about 11 times faster if converted to code that runs on GPU https://www.researchgate.net/publication/300042590_Using_GPUs_to_Speed-Up_Levenshtein_Edit_Distance_Computation
hiiamboris
11:46> return early once we hit a distance of 2 because the one we found earlier with a distance of 1 we already know is a better match
Yes, a good idea. I myself was using the OSA variant of Levenshtein's to compare 2 file name lists (names can be 100 chars easily), where I used another optimization: if number of errors exceeds a given limit (during the metric computation), consider them a zero match and continue with the other candidates (reducing the time required by ~2 orders of magnitude). The use case here is not looking for a best match, but for a set of acceptable matches (it turns out that in practice everything <0.7 is false matches). Still, it's pretty dumb to compare lists like this. Just the easiest to implement solution, not the optimal one.
GiuseppeChillemi
13:28A question and a proposal: what about organizing a RedCon in Europe ? It could be done on the next Red big announcement !
20:08The timeit function is real time. Set it to 1M and it literally takes nearly two seconds to complete.
20:11Is it the loop function itself that's killing it?
greggirwin
22:14@LFReD first, what do you mean by "expression"? All your examples are expressions. Second, be sure to run small tight loop tests a number of times. At those timescales any system influence can change results. Third, please be careful giving advice about language use and optimization at this stage of your Red knowledge, and confirm your findings.
LFReD
23:46@greggirwin I have tried 'small tight loop tests a number of times'.. which brings up another issue I've found is time/precise doesn't seem to kick in until a certain time has passed?
By advice, I'm guess you're referring to my 'tip'. It's a joke.
'in the usual notation of arithmetic, the expression 1 + 2 × 3 is well-formed...' https://en.wikipedia.org/wiki/Expression_(mathematics)
I posted this particular observation to try to determine if this is an issue or not, and if not, why does it happen? Is it my method?
greggirwin
01:28I thought we had hi res timing on windows since https://github.com/red/red/pull/3476 was merged. If that's not the case, it's an OS limitation on Windows.
> To speed up your code, use an expression when assigning an integer to a word.
Makes it sound authoritative.
On math, if you're referring to precedence of operators, Red is strictly left-to-right in this regard. If you want precedence, use parens or the math dialect.
henrikmk
05:30I observed a difference in time resolution between 0.6.4 and the latest nightly build, so increased time resolution should be working.
giesse
05:58Timing stuff is not as straightforward as one might think at first glance. Use profile if you don't know better. https://gist.github.com/giesse/1232d7f71a15a3a8417ec6f091398811
10:26@magicmouse > "Debugging consumes 85% of all programmer time by my long-term measurements. Ignore these speed freaks. The real battle is with the new programmers who are looking for a much simpler system."
12:07I am not suggesting that months be spent optimizing but as in a hospital if a patient arrives and is in great pain and they triage them and find that pain in a matter of a few hours can be remedied by removing the nail in their leg that keeps them from walking then the patient is cured and that patient wasn't left to sit around in pain or seek out another hospital. I think serious performance problems should be triaged, given rough time estimates to fix, and if the performance problem was just an oversight by the original developer and could be fixed in a short amount of time then that can be seen as significant progress at a minor cost and would not delay new features by a significant amount.
LFReD
12:38Forget all that, the real elephant in the room... a 37mb data file (a block of strings) that takes over 3 minutes to load, and once loaded, consumes nearly 400mb of system memory.. according to my math, that's 10mb per 1mb of data. Once it's loaded, it's absolutely blazing. Find a string among 3M strings in 1ns.
The load time seems to be exponential? I tried to load a 84mb file, and gave up after a half hour. It was loading at 1 mb per 10 seconds.
If I 'didn't know better', I would say that's a big issue. And I know you're working on it, but this...
*"it means that with an optimizing backend (Red/Pro), our lexer will be 4-8 times faster than R3's. It should then be possible to load gigabytes of Red data in memory in just a few seconds (using the future 64-bit version)"*
Pro only? ETA on 64-bit version?
12:41*'gigabytes'*.. Is 2 gb of data going to consume 20gb of memory?
Oldes
12:49@LFReD instead of writing neverending list of complains, maybe you should check yourself, where the activity is. You would maybe noticed, that there is fast-lexer branch, which should address exactly this issue: https://github.com/red/red/tree/fast-lexer
12:50And yes... your way of dealing with data is not efficient, because you are using high level values.. like strings, which requires more bytes than you think and it is by purpose.
12:52I mean when you have key: "abc" it does not consume just 4 bytes like in C.
LFReD
12:54@Oldes Explain to me how you would make a db that doesn't contain strings?
Oldes
12:56Sorry, I have my own work, do your own study... but usually the DBs works as a binary blobs with strictly defined structure, like that keys have 8 chars and so on.
LFReD
13:42 Yeah, binary blobs that need to be converted to and from strings so people can understand the syntax.
GaryMiller
14:22Most strings today for business take more than one byte per character due to foreign language characters and the need for localization in business apps. Some languages give you the choice of a plain array of ASCII characters or an array of Runes which are 2-byte codes used to represent the extended character sets.
dander
18:54@LFReD have you tried preallocating your block? It may be spending a lot of time resizing.
20:30Is the fast-lexer branch functional? I could not get it to work, when I tried yesterday.
ne1uno
20:47@henrikmk, few days earlier commit seemed to work better
LFReD
21:53@planetsizecpu If you think concerns about a few nanoseconds here or there makes one a 'speed freak', you've obviously never tried running O(n) type functions on a large block.. say 1,000,000 strings.
In red, doing a foreach on 34mb of data takes 1.25 seconds. Imagine a 'couple of gigs'.
22:02Instead of comments like *your way of dealing with data is not efficient* then I'll pay to see some examples of ways to do it better.
LFReD
00:52Ok... so leaving all that behind (for now, let see how the new lexer turns out), on a completely different subject.
'View is nice and all, but is a niche development. It doesn't compare with the power and scope of the modern browser UI, and the $billions spent in development. HTML 5, canvas, speed, extensions.. you name it.
Back in the day (2010), @dockimbel and I had long discussions and spent a fair bit of time developing web sockets for Cheyenne which I used to 'push' Rebol generated code to the page. I called the project 'Framewerks'.
Here's some of the conversation http://www.rebol.org/aga-display-posts.r?post=r3wp495x8438 ;)
Now, given the current lack of ports and a Red version of Cheyenne (really?), I've decided to drop a copy of Cheyenne into my Red folder and I'm going to use it as middleware between Red and the browser. There's probably some way to bind it to Red, but if not, I'm just going to have Cheyenne write the incoming request onto a file if necessary, and have Red poll it , and respond back to Cheyenne where Framewerks can take it from there.
Cheyenne still rocks! Just drop it in and fire it up. The amount of control it provides is off the charts!
So, 20 years later, lets see what Red can do with the browser! I've made a new git where I'll do some code cleanup, and drop Framewerks in there.
https://github.com/LFReD/Framewerks-for-Red
I also created a new Gitter if anyone is interested in this project. https://gitter.im/Framewerks-for-Red/community#
greggirwin
00:56@LFReD the way to do it better, as I said before, is to learn how Red works, and don't expect brute force to be fast. And profile things, posting numbers about specifics. From your 37M number, knowing you're doing triples, I can only *guess* you have 4-5M strings in ~1.5M blocks. From there, it's not a stretch to see that the mem use is in line. Of course, you can post comparisons of the exact same data being used the same way in other langs, so we can see how we stack up. But that means collections, not simple arrays, etc. which may mean understanding Red more than you care to do right now.
Features are coming, like fast lexer and full redbin support, that will help a lot with large datasets. But if you use a tool naively, making the same complaints when others have pointed out unrealistic expectations, you get what you pay for in effort.
Red is a language for data interchange and programming. It has published goals and features. It's great to push it into new territory, but be reasonable, and don't make the same complaints repeatedly. We get it, you're doing X and it's slow. 'nuff said.
Going forward, please use the /chit-chat or /sandbox rooms for your project related messages.
00:57:point_up: [December 14, 2019 3:02 PM](https://gitter.im/red/red?at=5df55bfd0616d6515e3cfed0) I hope someone takes you up on this, but don't expect the answer to be simple.
LFReD
01:03It's not 37M, it's a 34mb file which consists of a single block with 1,000,000 strings. And I just said "Ok... so leaving all that behind (for now, let see how the new lexer turns out),"
greggirwin
01:06You said (look at your own message) that it was a 37M file, then talked about foreach on 34M "of data".
01:10They were two different files. One 34mb and one 37mb.
GiuseppeChillemi
13:10I think that all negative things could take a positive shape. If @LFReD could write in a wiki notes about the performance issues, the technique involved, the solutions, the speed difference between Red and Rebol, it would be a great page!
Nomarian
13:49I compared project euler problem 1 between red, rebol and r3, r3 came out winning
henrikmk
14:18R3 is very fast, usually around 1.5-2x faster than R2.
pekr
14:24I wonder if Red would copy/translate R3 code into a R/S, if we would see just excessive examples, as ppl are reporting, like something being orders of magnitude slower. That does not make much sense to me, but then I am not strong with the low level stuff. OTOH Red is not a copy of R2, nor the R3, so the things might be different under the surface ...
henrikmk
14:28About profiling: Learning exactly what is fast or not will be unique for each runtime. It will be a while for a programmer to learn the fastest methods for Red, even if the person is proficient in R2. Learning about what is fast can't really be done without resorting to lots of profiling and putting some work into your loops.
You can also have general rules, like "never use FIND in a loop". I spent time building indexing frameworks to avoid the FIND inside a loop scenario and would love for Red to encourage such an approach, so even if Red might have a slower lexer, making it easy to index things for very fast block searching will overall make it easier to make code run fast.
For Red to truly become fast, we'll just have to wait until it's time to optimize. Make it work properly and correctly first.
Nomarian
14:35http://tpaste.us/8XMO Can you make this faster?
14:37sorry, didn't wait until reading everything you said, yeah, still a long time away from optimization, but with r3 existing, it is possible that red could be faster at least
14:37(even though r3 is still extremely slow when compared to other languages)
henrikmk
14:40REBOL tends to be slow, if you use it like other languages.
hiiamboris
14:48@khwerz repeat i limit [ all [i % 3 <> 0 i % 5 <> 0 sum: sum + i ] ] about 6 times faster
15:19http://tpaste.us/PMED I know i haven't averaged it out but overall, those are the scores
hiiamboris
15:23Okay you're right, I overoptimized it a bit ☻ limit: 1000 - 1 sum: 0 repeat i limit [ all [any [i % 3 =? 0 i % 5 =? 0] sum: sum + i ] ] is the correct solution
15:23But so is limit: 1000 - 1 sum: 999 * 500 repeat i limit [ all [i % 3 <> 0 i % 5 <> 0 sum: sum - i ] ] ;) - and a bit faster
rebred
19:05after installing red-15dec19-583e536e the REPL is very slow
20:53On your other code, oh man, can it be faster. ;^)
mezz: function [][
limit: 1000 - 1
sum: 0
repeat i limit [
if zero? ( (i // 3) * (i // 5) ) [ sum: sum + i ]
]
; print sum
]
rout: routine [
/local
limit [integer!]
sum [integer!]
i [integer!]
][
limit: 1000 - 1
sum: 0
i: 0
loop limit [
i: i + 1
if 0 = ( (i // 3) * (i // 5) ) [
sum: sum + i
]
]
; print-line sum
]
20:54Please post the results when you test that, so we can see how Red stacks up.
20:55I didn't see anything about comparing interpreter performance in the requirements. ;^)
21:07I think anytime R/S is an *easy* solution, e.g. for things like this, we can break it out. And this coming from the guy who pushes for less optimization at every turn. ;^) The key is that, for simple numerics, you don't really have to know anything different. This would also make a great article, showing how easy it is. There are subtle difference, like not having repeat in R/S. Heck, I even used 0 = when zero? is available in R/S. You do have to compile your app, but it's such a *huge* win for almost no effort, we need to promote it. What other high level lang gives you this option so easily?
21:16Yes. Startup overhead and other considerations...I guess we need to provide tools for people to do better comparisons.
21:20Also, @khwerz compiling with -c is fine, since you're not changing anything in the runtime. Much faster for repeat builds.
21:26> its still slower than most languages and r3
@khwerz as with other microbenchmark chat of late, let me ask, does this matter? If so, in what context? That is, what are you using Red for where this makes a difference in the success or usefulness of an app or system? Of course, there are places it matter, so the reason I push back is because we need focus on the things that matter, that make a difference in real use cases, along with features that people need to build those real apps and systems.
21:26I am anxious for the new test results though. ;^)
Nomarian
21:27just wondering if I can use it for number crunching
21:28I had some free time and decided to waste it on project euler is all
greggirwin
21:28If you need fast number crunching, just drop to R/S in routines as shown.
delta-time: function [
"Return the time it takes to evaluate a block"
code [block! word! function!] "Code to evaluate"
/count ct "Eval the code this many times, rather than once"
][
ct: any [ct 1]
t: now/time/precise
if word? :code [code: get code]
; DO here because loops can't compile indirect block refs
do [loop ct either block? :code [code] [[code]]]
now/time/precise - t
]
23:01@greggirwin >there will likely be an optional web server module.
I'm starting a new project Framewerks and I'm going to figure out a way to bind Red with Cheyenne. If worst comes to worst, I'll have Red write a doc, and get Cheyenne to poll for it, but that is obviously not ideal.
loziniak
11:00It would be nice to have Wiki page about speed optimization in Red. Preferably with examples. From recent messages, I got some tricks: 1. Try to move most resource-heavy parts to Red/System as routines. 2. Pre-allocate blocks. Block resizing takes time. 3. Avoid loops with find. If you need this functionality, try to index your data.
17:40@loziniak and do lots of profiling, if you can't avoid loops. in REBOL, using specific block types like hash! speeds up FIND operations a lot, if you can't avoid using FIND, though there are other caveats. I'm not sure if there is such a distinction in Red.
greggirwin
21:49@loziniak if there's no page already, please start one! Could be a general Hints & Tips, with a Performance section too.
21:50@GaryMiller this is your app with *lots* of parse rules, correct? Do you know if encap mode will work for you?
henrikmk
18:16Another performance hint in REBOL is that it's faster to sort and loop through a block once with purely mezzanine functions than to loop many times through a block with native functions. This should apply to Red as well.
Some other performance notes:
- Detecting duplicate values in a block. Using UNIQUE will copy the block and is rather costly. The only way to avoid copying the block is by sorting it and looping through it, and then that's only if you don't care about losing the sort order. - Checking for intersections between two blocks. For that, I made an INTERSECTING? function, which avoids making a new block and just returns TRUE/FALSE. Much faster than INTERSECT, even though INTERSECTING? is a mezzanine. Again requires that both blocks are sorted. - Generally always keeping your blocks sorted is helpful for performance, when you loop through them. A SORTED-INSERT could be helpful there, i.e. when inserting a value, it's automatically placed in the correctly sorted location, so you don't need to sort afterwards. - Storing indexes as ranges instead of [1 2 3 4...] can save space and be very helpful if you need to find a value between ranges. Peter Wood and I worked on a framework for this for REBOL, though it isn't finished yet. - Perhaps it could also be useful to have blocks that keep internal information about an original sorting order, so the user doesn't need to maintain it. This is otherwise necessary to main in separately arranged blocks, and is used a lot in lists for table widgets.
hiiamboris
18:32> Using UNIQUE will copy the block and is rather costly. The only way to avoid copying the block is by sorting it and looping through it
I would argue that copy cost is negligible compared to block-to-hash promotion and 2N hash lookups (done by UNIQUE)
henrikmk
18:38Yes, probably true. In any case, there is room for a simpler, less memory intensive and faster way to detect duplicate values in blocks.
binary-search: function [
"Returns the index where a value is (success), or the index of the insertion point as a negative offset (not found)"
series [series!] "Pre-sorted series"
value "Value to find"
][
if empty? series [return -1] ; none?
low: 1
high: length? series
while [low <= high] [
; Normally I would just use ROUND, but this is one place we do
; care about performance, because this func could get called a
; lot depending on the application.
;mid: round/down low + (high - low / 2)
mid: to integer! low + (high - low / 2)
; Pick is faster than path syntax, and just as clear here.
cmp-val: pick series mid
either cmp-val = value [return mid] [
either cmp-val < value [low: mid + 1] [high: mid - 1]
]
]
negate low
]
e.g. [
binary-search [1 2 3 4 5 6] 4
binary-search [1 2 3 4 5 6] 7
binary-search [1 2 3 4 5 6] 0
]
sorted-insert: function [
"Inserts a value in a pre-sorted series, into its sorted location"
series [series!] "Pre-sorted series"
value [any-type!]
][
insert/only
at series absolute binary-search series value
value
]
e.g. [
blk: copy []
sorted-insert blk 5
sorted-insert blk 1
sorted-insert blk 10
sorted-insert blk 5
sorted-insert blk 10
sorted-insert blk 7
sorted-insert blk 3
print mold blk
]
20:49The above is simplistic, not accounting for types that can't be compared.
GaryMiller
20:52@greggirwin No, not one parse rule at least not in the Red sense. But currently over 18,500 English, sentences, questions, or exclamations that go through the Levenshtein Algorithm and the closest match has a template executed that is Red code meant to generate a correct response based on a few hundred object attributes that can be set at the top of the program to define everything about the AI Avatars life like gender age, name , family, job, etc... Each time close match is found the template for that pattern is stored in a block then at the end the block contains the correct template codee that is executed to generate the response and make the same short term memories a human would from the same information. The Template also binds object attribute to He, She, they, It, Then, There, Reason, and CurrentTopic so that if the human references any of these pronouns later if know who they are referring to. So the reason I have to loop though each time is to call the Levenshtein function and find the closest pattern to what the user typed.
greggirwin
21:28Thanks for clarifying @GaryMiller. I did an LCS (for diffing) func in R2 many years ago, then did it in rebbin, and it was usable speed wise for small to medium inputs.
Yours is a great stress test, and I imagine the big win will come with modular compilation.
GaryMiller
22:05Yes, I was also wondering if it would be possible if when the Lex process loads my code if it could identify the any R/S optimized coded routines in the file and invoke the compiler to compile that code into a runtime time library. In that way too all the code would not need to be recompiled each time only the functions that you wished to optimize. That way you wouldn't have to wait for long compiles to finish since you are only compiling a small part of the code. Also would it be a major project to transpile Red interpretive code into R/S code. I realize there are probably some cases where the code would be too dynamic to statically compile. But in those cases it could just transpile the functions that it could and leave the rest interpreted kind of like pypy or Nuitka does when it tries to optimize Python execution.
greggirwin
22:13We can build tools to do almost anything. Right now it's up to you to structure those parts and build your custom runtime. Transpiling is *really* tricky, unless your functions are very, very simple; in which case, they should be pretty easy to port manually. A way to experiment would be a tool that lets you write simple numeric or string processing funcs, and convert just those, out of any context. That way we can identify patterns and heuristics to drive further work. And they are useful on their own if nothing else.
hiiamboris
22:26@GaryMiller why not get those routines out into routines.red (as #include), build a console with those, and interpret the rest with this custom console?
GaryMiller
22:40@hiiamboris You make it sound very simple. So I'm guessing routines.red is the existing R/S compiled code that the current console calls. And if I included my R/S functions in there I'd just need to recompile the console with the the new routines.red to make those functions available as compiled words inside the custom console. Are there any docs that would walk me through that process?
hiiamboris
22:53It's simple yes - download red snapshot with git or [directly](https://github.com/red/red/archive/master.zip) - download R2 if you don't have it - [2.7.6](http://static.red-lang.org/build/rebview.exe) or you can find 2.7.8 on the official site - modify environment/routines.red (add #include of your file or just copy-paste your routines) - build the new console with rebol -s --do "do/args %red.r {-r environment/console/GUI/gui-console.red}" (or change rebol to rebview) - use gui-console.exe as your interpreter
Ask in /help if you need any more ;)
greggirwin
23:18You know, even better than a wiki page entry for that would be a little custom-console-builder tool that automates it.
Anyone game?
hiiamboris
08:49And I thought of 2 functions - download-runtime and build-console (between those one can modify it) ;)
LongMuchoLove_twitter
13:38Hey! I just downloaded the Red DMS and I'm so excited to play with it. For some reason my Mac can't run the exec
14:19More info....I really want to get this up and running!
14:19> otool -L /usr/local/bin/red /usr/local/bin/red: /System/Library/Frameworks/Carbon.framework/Versions/A/Carbon (compatibility version 2.0.0, current version 128.0.0) /usr/lib/libstdc++.6.dylib (compatibility version 7.0.0, current version 7.4.0) /usr/lib/libSystem.B.dylib (compatibility version 1.0.0, current version 88.3.11) /usr/lib/libgcc_s.1.dylib (compatibility version 1.0.0, current version 1.0.0)
15:07I know this is about Red...but even in Rebol (whom's REPL I can launch) I'm getting nowhwere
15:28@Oldes - no problem.Thank you! Just trying to get acquainted with this language family. I'm now playing and going through the Rebol tutorial. Once we figure out the Red issue on my machine I'll go ahead and do the same thing with Red :) Thank you again :)
Oldes
15:30You should figure out, why is libc.dylib missing on your system. I was using Red without problems on Mac, but I think it was older MacOS version.
15:33And I should also note, that I don't like where is Apple heading (with its Catarina disaster)... but there are hard Mac users, like @rebolek.
LongMuchoLove_twitter
15:35@Oldes - all the libraries are on my system! I also agree. I found Red because I was looking for a cross-platform UI. Originally I found Tcl/Tk—which I really like. Tcl is a bit confusing tho and I suspect Red is more powerful / better choice in the long run
15:36Cross-Platform so I can lose the Mac and still run my software in the future :)
pjhenning
23:17Hello, is there any way to call c code fromwithin red? So far all I can find in the docs is how to call red code from within c.
greggirwin
00:29You can use R/S to define an FFI for it. See https://github.com/red/code/tree/master/Library for examples.
20:06Being cross platform, we need to provide a consistent experience out of the box, as much as possible. Somebody could probably write a lib wrapper for it, which others can use.
You can try it with rlwrap: rlwrap -a ~/.red/console*, there's some minor rendering issues our of box but it's better than default console in some cases, and likely it can be tuned a bit to resolve those issues.
Also readline/emacs' common C-a and C-e work for me instead of Home and End.
05:41Thanks for the tip @iNode. Would you see if https://github.com/red/red/wiki/%5BNOTES%5D-REPL-Tips-and-Tricks seems like a good place for that, and add your tip there?
iNode
18:18Thanks for the pointer. This page seems to be a proper place for such tip. I've added some notes there.
20:34hey guys, are there any fresh news on 64-bit port for Red? just learned the hard way, that OSX Catalina removed 32-bit support altogether, so no easy way of running Red on that system ATM :(
Like many development organizations, we've found it is a big challenge, and we're not caught by surprise so much as having the issue forced. With other big design elements in the works, we do not want to pull focus from our core efforts, so we are not working specifically on Catalina support at this time. More prudently, we are working on moving Red to 64-bit platforms in general, doing so step by step, and will announce more as the work progresses.
In the meantime, you can still use virtualization tools to run Red on macOS after upgrading to 10.15. We have been aware of the change for a long time, but ensuring sustainability of the whole project takes precedence.
vazub
21:08Thanks, Gregg! I am fine with that, just wanted to understand what is current situation. The explanation makes total sense to me.
15:38Hi! Pleas, tel me where i can get DOS version Red? In https://www.red-lang.org/p/download.html only Win, Linux and Mac... Command "red -c -t MSDOS hello.red" make win32 binary, not dos
20:04Sorry @SergeyVladivostok, not enough DOS users to justify supporting that OS. Win7, MacOS, Android, and various Linux distros are enough to keep us busy.
TheHowdy_gitlab
20:19Hm... Just wondering: is Red already fully written in Red/System? If so, would writing a Red/System compiler for DOS / other platforms be enough to support Red too?
pekr
20:45Might sound like a weird question, but if it is part of a docced targets, might be reasonable to remove it. It might as well lead to the questionof the least possible hw co fig support. E.g. Python Micro supports down to something like 16KB ARM MCU.
greggirwin
21:08Red can be ported to anything, and use R/S for tiny systems, though not currently designed for micros. Perhaps renaming MSDOS to WinConsole would be clearer.
23:03Happy New Year to all! A blog post is in the works, talking about what's coming up.